什么是二进制转文本转换器?
二进制转文本转换器可以把一串二进制数字(也就是 0 和 1)还原成我们能读懂的字符。计算机内部会借助 ASCII 这类字符编码,把每个字母、数字和符号都存成一个二进制数。这个工具做的正是相反的工作:它读取你输入的二进制,按每 8 位拆成一个字节,再把每个字节对应翻译成相应的字符。
使用方法
把二进制粘贴到输入框中,每 8 位为一组,用空格或换行分隔,例如 01001000 01101001。工具会自动忽略 0 和 1 以外的所有字符,所以即便混入了多余的标点也不会出错。点击「计算」即可看到解码后的文本,以及生成的字符数量。
转换原理
每 8 位二进制数字组成一个字节。这个字节会被当作二进制数来解读:最右边一位代表 1,往左依次是 2、4、8、16、32、64 和 128。把所有为 1 的位对应的数值相加,就得到一个 0 到 255 之间的值。这个值就是字符编码,再通过 ASCII/Unicode 对照表映射成一个可打印字符。最后按顺序把这些字符拼接起来,就重新还原出了原始信息。
$$\text{Char} = \text{Chr}\!\left( \sum_{k=0}^{7} b_{7-k} \cdot 2^{\,k} \right), \qquad b_k \in \text{Binary (8-bit groups)}$$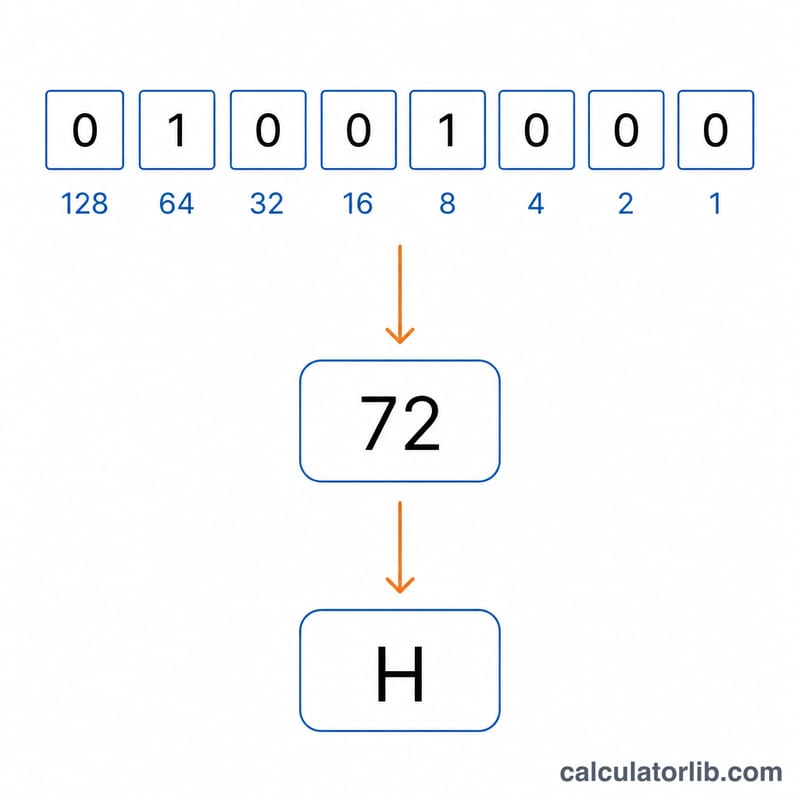
实例演算
以 01001000 为例,把值为 1 的位相加:
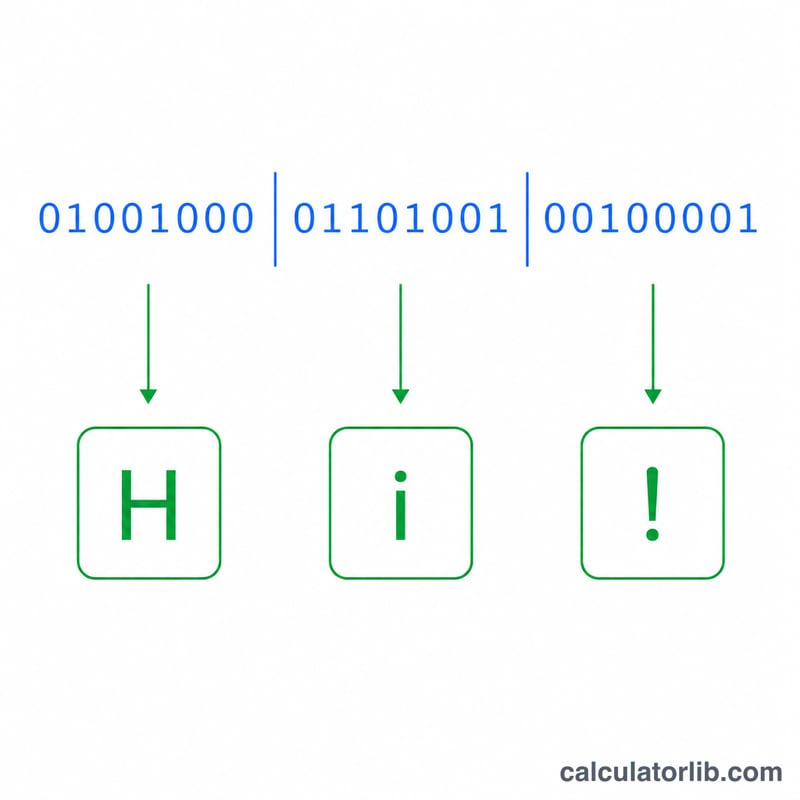
编码 72 对应的字符是字母「H」。下一组 01101001 算出来是
对应字符「i」。两者拼接起来,结果就是「Hi」。
ASCII二进制参考表
在ASCII标准中,每个可打印字符都映射到一个十进制代码点,该代码点存储为一个8位的二进制组(一个字节)。要将二进制解码回文本,请将二进制字符串拆分为8位组,将每组转换为其十进制值,然后查找匹配的字符。例如,字节01000001等于十进制65,即字母A。
大写字母(A–Z)
| 字符 | 十进制 | 二进制 |
|---|---|---|
| A | 65 | 01000001 |
| B | 66 | 01000010 |
| C | 67 | 01000011 |
| D | 68 | 01000100 |
| E | 69 | 01000101 |
| F | 70 | 01000110 |
| G | 71 | 01000111 |
| H | 72 | 01001000 |
| I | 73 | 01001001 |
| J | 74 | 01001010 |
| K | 75 | 01001011 |
| L | 76 | 01001100 |
| M | 77 | 01001101 |
| N | 78 | 01001110 |
| O | 79 | 01001111 |
| P | 80 | 01010000 |
| Q | 81 | 01010001 |
| R | 82 | 01010010 |
| S | 83 | 01010011 |
| T | 84 | 01010100 |
| U | 85 | 01010101 |
| V | 86 | 01010110 |
| W | 87 | 01010111 |
| X | 88 | 01011000 |
| Y | 89 | 01011001 |
| Z | 90 | 01011010 |
小写字母(a–z)
| 字符 | 十进制 | 二进制 |
|---|---|---|
| a | 97 | 01100001 |
| b | 98 | 01100010 |
| c | 99 | 01100011 |
| d | 100 | 01100100 |
| e | 101 | 01100101 |
| f | 102 | 01100110 |
| g | 103 | 01100111 |
| h | 104 | 01101000 |
| i | 105 | 01101001 |
| j | 106 | 01101010 |
| k | 107 | 01101011 |
| l | 108 | 01101100 |
| m | 109 | 01101101 |
| n | 110 | 01101110 |
| o | 111 | 01101111 |
| p | 112 | 01110000 |
| q | 113 | 01110001 |
| r | 114 | 01110010 |
| s | 115 | 01110011 |
| t | 116 | 01110100 |
| u | 117 | 01110101 |
| v | 118 | 01110110 |
| w | 119 | 01110111 |
| x | 120 | 01111000 |
| y | 121 | 01111001 |
| z | 122 | 01111010 |
数字(0–9)
| 字符 | 十进制 | 二进制 |
|---|---|---|
| 0 | 48 | 00110000 |
| 1 | 49 | 00110001 |
| 2 | 50 | 00110010 |
| 3 | 51 | 00110011 |
| 4 | 52 | 00110100 |
| 5 | 53 | 00110101 |
| 6 | 54 | 00110110 |
| 7 | 55 | 00110111 |
| 8 | 56 | 00111000 |
| 9 | 57 | 00111001 |
空格和常见标点符号
| 字符 | 名称 | 十进制 | 二进制 |
|---|---|---|---|
| (空格) | 空格 | 32 | 00100000 |
| ! | 感叹号 | 33 | 00100001 |
| " | 双引号 | 34 | 00100010 |
| # | 哈希符号 | 35 | 00100011 |
| $ | 美元符号 | 36 | 00100100 |
| % | 百分号 | 37 | 00100101 |
| & | 和号 | 38 | 00100110 |
| ' | 撇号 | 39 | 00100111 |
| ( | 左括号 | 40 | 00101000 |
| ) | 右括号 | 41 | 00101001 |
| * | 星号 | 42 | 00101010 |
| + | 加号 | 43 | 00101011 |
| , | 逗号 | 44 | 00101100 |
| - | 连字符 | 45 | 00101101 |
| 。 | 句号 | 46 | 00101110 |
| / | 斜杠 | 47 | 00101111 |
| : | 冒号 | 58 | 00111010 |
| ; | 分号 | 59 | 00111011 |
| ? | 问号 | 63 | 00111111 |
| @ | At符号 | 64 | 01000000 |
作为一个更长的例子,二进制01001000 01101001解码为十进制对72和105,得到文本Hi。要反向操作,文本转二进制转换器将Hi转回为01001000 01101001。
关键术语解释
- 比特
- 数字信息的最小单位,保存单个二进制值0或1。这个词是"二进制数字"的缩写。
- 字节
- 作为一个单位处理的8个比特的组。一个字节可以表示 \(2^8 = 256\) 个不同的值(0–255),这恰好足以编码扩展ASCII集中的每个字符。这就是为什么二进制文本被分组为8位块。
- 二进制/二进制制
-
仅使用两个符号0和1的数字系统。每个位置代表2的幂次;从右到左读取,位置值为 \(1, 2, 4, 8, 16, 32, 64, 128\)。例如,
01000001= 64 + 1 = 65。 - ASCII
- 美国信息交换标准代码,一种字符编码,将整数0–127映射到字母、数字、标点和控制代码。标准ASCII使用7位;第八个前导位(通常为0)将其填充为完整字节。
- 代码点
-
在编码方案中分配给单个字符的数值。在ASCII中,字母
A有代码点65;同一字符在Unicode中有代码点U+0041(也是65)。 - 字符编码
- 将字符映射到数值代码点,然后映射到字节进行存储或传输的一组规则。ASCII、Latin-1和UTF-8都是编码;选择正确的编码可确保字节被解码回预期的文本。
- Unicode
- 一个通用字符标准,为世界各地书写系统中的每个字符分配一个唯一的代码点,远超过ASCII的128个字符。其前128个代码点与ASCII相同,因此基本英文文本在两者下解码方式相同。
- UTF-8
- 网络上最常见的Unicode编码。它用单个字节表示ASCII字符(与ASCII完全匹配),并对更高的代码点使用2–4个字节,保持普通英文文本完全向后兼容。
常见问题
为什么二进制必须按 8 位分组? 标准 ASCII 编码每个字符占 8 位(即一个字节)。工具会把输入按 8 位切片,这样每个字节就能干净利落地对应到一个字符。
如果我的分组不正好是 8 位怎么办? 转换器会从左到右,把找到的所有数字按 8 位一段来处理。要想得到正确结果,请确保每个字符对应的字节都是完整的 8 位数字。
它支持扩展字符吗? 0–127 是标准 ASCII;128–255 对应扩展字符,此时字节的数值会被直接当作 Unicode 码位使用。