2進数→テキスト変換ツールとは?
2進数→テキスト変換ツールは、0と1で並んだ2進数の列を、それが表す人間に読める文字へとデコードするツールです。コンピュータは、文字・数字・記号のすべてを、ASCIIなどの文字エンコードを使って2進数として保存しています。このツールはその流れを逆にたどります。入力された2進数を読み込み、8ビットのバイトに区切り、各バイトを対応する文字へ変換します。
使い方
2進数を入力欄に貼り付けてください。8ビットのまとまりごとに、半角スペースか改行で区切ります。例えば 01001000 01101001 のように入力します。本ツールは0と1以外の文字を無視するため、余計な記号が混ざっても問題なく動作します。「計算」を押すと、デコードされたテキストと変換された文字数が表示されます。
計算のしくみ
8桁の2進数のまとまりが1バイトです。このバイトは2進数(基数2)として解釈されます。一番右のビットの重みは1、その左から順に2、4、8、16、32、64、128となります。値が1になっているビットの重みを合計すると、0〜255の数値が得られます。この数値が文字コードであり、ASCII/Unicodeの対応表を通して表示可能な文字に変換されます。最後に各文字を順番につなぎ合わせて、元のメッセージが復元されます。
$$\text{Char} = \text{Chr}\!\left( \sum_{k=0}^{7} b_{7-k} \cdot 2^{\,k} \right), \qquad b_k \in \text{Binary (8-bit groups)}$$
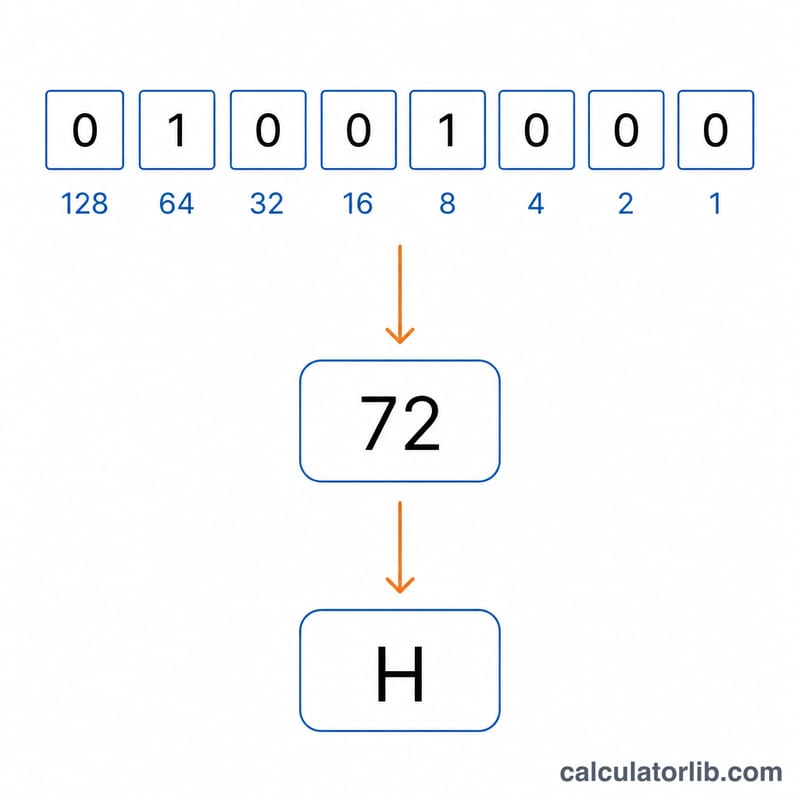
計算例
01001000 を例に見てみましょう。1になっているビットの重みを足すと \(64 + 8 = 72\) です。文字コード72は「H」を表します。次のまとまり 01101001 は \(64 + 32 + 8 + 1 = 105\) となり、これは「i」です。つなぎ合わせると、結果は「Hi」になります。
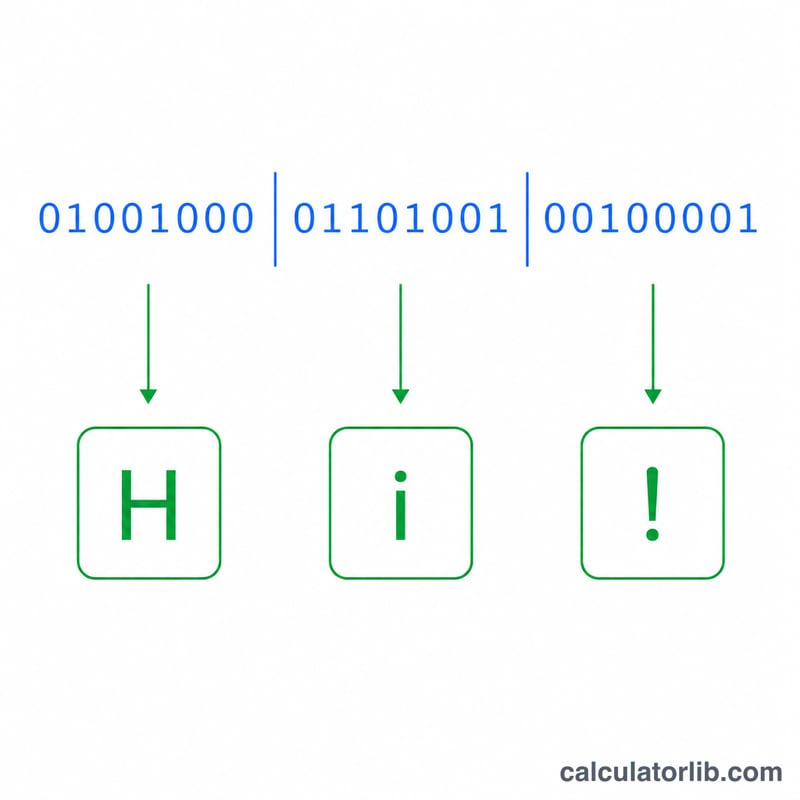
ASCII バイナリ リファレンス テーブル
各印字可能文字は ASCII 標準の10進コード ポイントにマッピングされ、8 ビット バイナリ グループ(1 バイト)として保存されます。バイナリをテキストにデコードするには、バイナリ文字列を 8 ビットのグループに分割し、各グループを10進値に変換して、対応する文字を検索します。たとえば、バイト 01000001 は10進数の 65 に等しく、これは文字 A です。
大文字(A~Z)
| 文字 | 10進数 | バイナリ |
|---|---|---|
| A | 65 | 01000001 |
| B | 66 | 01000010 |
| C | 67 | 01000011 |
| D | 68 | 01000100 |
| E | 69 | 01000101 |
| F | 70 | 01000110 |
| G | 71 | 01000111 |
| H | 72 | 01001000 |
| I | 73 | 01001001 |
| J | 74 | 01001010 |
| K | 75 | 01001011 |
| L | 76 | 01001100 |
| M | 77 | 01001101 |
| N | 78 | 01001110 |
| O | 79 | 01001111 |
| P | 80 | 01010000 |
| Q | 81 | 01010001 |
| R | 82 | 01010010 |
| S | 83 | 01010011 |
| T | 84 | 01010100 |
| U | 85 | 01010101 |
| V | 86 | 01010110 |
| W | 87 | 01010111 |
| X | 88 | 01011000 |
| Y | 89 | 01011001 |
| Z | 90 | 01011010 |
小文字(a~z)
| 文字 | 10進数 | バイナリ |
|---|---|---|
| a | 97 | 01100001 |
| b | 98 | 01100010 |
| c | 99 | 01100011 |
| d | 100 | 01100100 |
| e | 101 | 01100101 |
| f | 102 | 01100110 |
| g | 103 | 01100111 |
| h | 104 | 01101000 |
| i | 105 | 01101001 |
| j | 106 | 01101010 |
| k | 107 | 01101011 |
| l | 108 | 01101100 |
| m | 109 | 01101101 |
| n | 110 | 01101110 |
| o | 111 | 01101111 |
| p | 112 | 01110000 |
| q | 113 | 01110001 |
| r | 114 | 01110010 |
| s | 115 | 01110011 |
| t | 116 | 01110100 |
| u | 117 | 01110101 |
| v | 118 | 01110110 |
| w | 119 | 01110111 |
| x | 120 | 01111000 |
| y | 121 | 01111001 |
| z | 122 | 01111010 |
数字(0~9)
| 文字 | 10進数 | バイナリ |
|---|---|---|
| 0 | 48 | 00110000 |
| 1 | 49 | 00110001 |
| 2 | 50 | 00110010 |
| 3 | 51 | 00110011 |
| 4 | 52 | 00110100 |
| 5 | 53 | 00110101 |
| 6 | 54 | 00110110 |
| 7 | 55 | 00110111 |
| 8 | 56 | 00111000 |
| 9 | 57 | 00111001 |
スペース・一般的な句読点
| 文字 | 名前 | 10進数 | バイナリ |
|---|---|---|---|
| (スペース) | スペース | 32 | 00100000 |
| ! | 感嘆符 | 33 | 00100001 |
| " | ダブルクォート | 34 | 00100010 |
| # | ハッシュ | 35 | 00100011 |
| $ | ドル記号 | 36 | 00100100 |
| % | パーセント | 37 | 00100101 |
| & | アンパサンド | 38 | 00100110 |
| ' | アポストロフィ | 39 | 00100111 |
| ( | 左括弧 | 40 | 00101000 |
| ) | 右括弧 | 41 | 00101001 |
| * | アスタリスク | 42 | 00101010 |
| + | プラス | 43 | 00101011 |
| , | カンマ | 44 | 00101100 |
| - | ハイフン | 45 | 00101101 |
| . | ピリオド | 46 | 00101110 |
| / | スラッシュ | 47 | 00101111 |
| : | コロン | 58 | 00111010 |
| ; | セミコロン | 59 | 00111011 |
| ? | 疑問符 | 63 | 00111111 |
| @ | アットマーク | 64 | 01000000 |
より長い例として、バイナリ 01001000 01101001 は10進数のペア 72 と 105 にデコードされ、テキスト Hi になります。反対方向に進むには、Text to Binary コンバーターが Hi を 01001000 01101001 に変換します。
主要用語の説明
- ビット
- デジタル情報の最小単位で、0 または 1 のいずれかのバイナリ値を保持します。この言葉は「バイナリ デジット」の短縮形です。
- バイト
- 8 ビットのグループで 1 つの単位として処理されます。1 バイトは \(2^8 = 256\) の異なる値(0~255)を表すことができ、これはちょうど拡張 ASCII セット内のすべての文字をエンコードするのに十分です。これが、バイナリ テキストが 8 ビットのチャンクに分割される理由です。
- バイナリ / 2 進法
-
0 と 1 の 2 つの記号のみを使用する数値体系です。各位置は 2 の累乗を表します。右から左に読むと、位の値は \(1, 2, 4, 8, 16, 32, 64, 128\) です。たとえば、
01000001= 64 + 1 = 65 です。 - ASCII
- アメリカン スタンダード コード フォー インフォメーション インターチェンジで、整数 0~127 を文字、数字、句読点、および制御コードにマッピングする文字エンコーディングです。標準 ASCII は 7 ビットを使用し、8 番目の先頭ビット(通常は 0)をパディングして完全なバイトにします。
- コード ポイント
-
エンコーディング スキーム内の単一文字に割り当てられた数値です。ASCII では文字
Aはコード ポイント 65 を持ちます。同じ文字は Unicode コード ポイント U+0041(同じく 65)を持ちます。 - 文字エンコーディング
- 文字を数値コード ポイントにマッピングし、その後バイトにしてストレージまたは送信するための一連のルールです。ASCII、Latin-1、UTF-8 はすべてエンコーディングで、正しいものを選択することでバイトが意図したテキストに確実にデコードされます。
- Unicode
- 世界の文字体系全体のすべての文字に一意のコード ポイントを割り当てる普遍的な文字標準で、ASCII の 128 文字をはるかに超えています。最初の 128 コード ポイントは ASCII と同じなので、基本的な英語テキストは両方で同じようにデコードされます。
- UTF-8
- ウェブ上で最も一般的な Unicode のエンコーディングです。ASCII 文字を単一のバイト(ASCII と正確に一致)で表し、より高いコード ポイントに 2~4 バイトを使用して、プレーンな英語テキストを完全に下位互換性を保つようにします。
よくある質問
なぜ8ビット区切りにする必要があるの? 標準的なASCIIは1文字あたり8ビット(1バイト)を使います。本ツールは入力を8ビットごとに区切るため、各バイトが1文字にきれいに対応します。
区切りがちょうど8ビットでない場合は? 本ツールは見つけた数字を左から順に8ビットずつ処理します。正しい結果を得るには、各文字のバイトを必ず8桁にそろえてください。
拡張文字には対応していますか? 0〜127は標準ASCIIです。128〜255は拡張文字に対応しており、バイト値はそのままUnicodeのコードポイントとして使われます。