Công cụ chuyển mã nhị phân sang văn bản là gì?
Công cụ này giải mã các chuỗi số nhị phân (gồm các chữ số 0 và 1) trở lại thành những ký tự mà con người đọc được. Trong máy tính, mỗi chữ cái, con số hay ký hiệu đều được lưu dưới dạng một số nhị phân thông qua bảng mã ký tự như ASCII. Công cụ này làm điều ngược lại: đọc chuỗi nhị phân của bạn, tách thành từng byte 8 bit và chuyển mỗi byte thành ký tự tương ứng.
Cách sử dụng
Dán chuỗi nhị phân của bạn vào ô nhập. Hãy ngăn cách mỗi nhóm 8 bit bằng dấu cách hoặc xuống dòng — ví dụ 01001000 01101001. Công cụ sẽ tự bỏ qua mọi ký tự không phải là 0 hay 1, nên các dấu câu thừa cũng không gây lỗi. Bấm "Tính" để xem văn bản đã giải mã cùng số lượng ký tự thu được.
Giải thích công thức
Mỗi nhóm 8 chữ số nhị phân là một byte. Byte này được hiểu như một số ở hệ cơ số 2: bit ngoài cùng bên phải có giá trị 1, bit kế tiếp là 2, rồi đến 4, 8, 16, 32, 64 và 128. Cộng tất cả các bit có giá trị 1 lại sẽ cho một con số từ 0 đến 255. Đó chính là mã ký tự, được tra trong bảng ASCII/Unicode để ra một ký tự hiển thị được. Sau đó các ký tự được nối lại theo thứ tự để khôi phục thông điệp ban đầu.
$$\text{Char} = \text{Chr}\!\left( \sum_{k=0}^{7} b_{7-k} \cdot 2^{\,k} \right), \qquad b_k \in \text{Binary (8-bit groups)}$$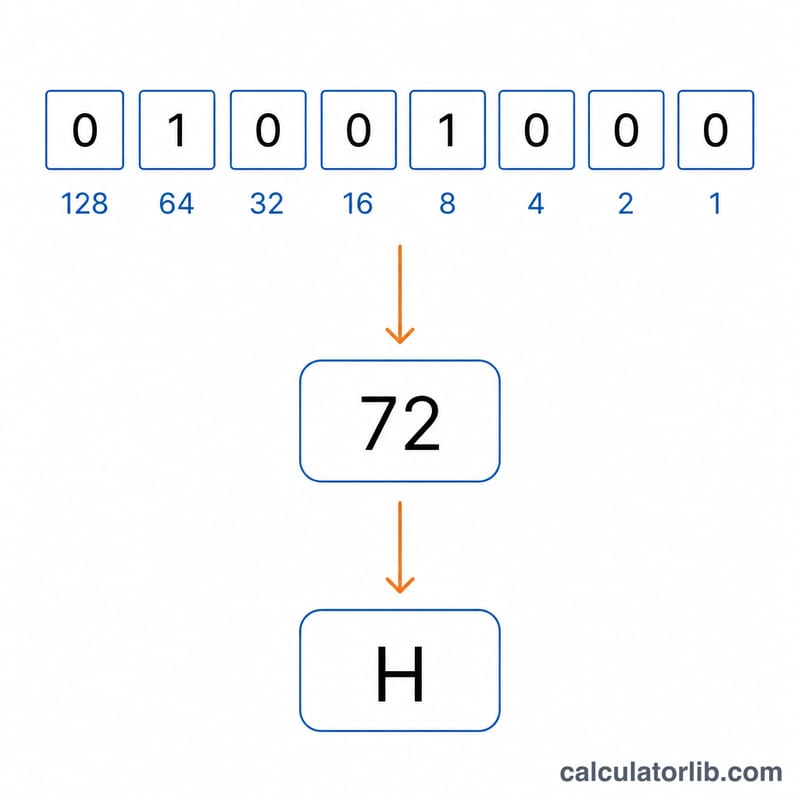
Ví dụ minh họa
Lấy nhóm 01001000. Cộng các bit có giá trị 1: \(64 + 8 = 72\). Mã ký tự 72 chính là chữ "H". Nhóm tiếp theo 01101001 cho \(64 + 32 + 8 + 1 = 105\), tức là chữ "i". Nối lại, kết quả là "Hi".
Bảng Tham Chiếu ASCII Nhị Phân
Mỗi ký tự có thể in được ánh xạ tới một điểm mã thập phân trong tiêu chuẩn ASCII, được lưu trữ dưới dạng một nhóm nhị phân 8 bit (một byte). Để giải mã nhị phân trở lại thành văn bản, chia chuỗi nhị phân thành các nhóm 8 bit, chuyển đổi mỗi nhóm thành giá trị thập phân của nó, và tra cứu ký tự phù hợp. Ví dụ, byte 01000001 bằng 65 thập phân, đó là chữ cái A.
Chữ Cái Hoa (A–Z)
| Ký tự | Thập phân | Nhị phân |
|---|---|---|
| A | 65 | 01000001 |
| B | 66 | 01000010 |
| C | 67 | 01000011 |
| D | 68 | 01000100 |
| E | 69 | 01000101 |
| F | 70 | 01000110 |
| G | 71 | 01000111 |
| H | 72 | 01001000 |
| I | 73 | 01001001 |
| J | 74 | 01001010 |
| K | 75 | 01001011 |
| L | 76 | 01001100 |
| M | 77 | 01001101 |
| N | 78 | 01001110 |
| O | 79 | 01001111 |
| P | 80 | 01010000 |
| Q | 81 | 01010001 |
| R | 82 | 01010010 |
| S | 83 | 01010011 |
| T | 84 | 01010100 |
| U | 85 | 01010101 |
| V | 86 | 01010110 |
| W | 87 | 01010111 |
| X | 88 | 01011000 |
| Y | 89 | 01011001 |
| Z | 90 | 01011010 |
Chữ Cái Thường (a–z)
| Ký tự | Thập phân | Nhị phân |
|---|---|---|
| a | 97 | 01100001 |
| b | 98 | 01100010 |
| c | 99 | 01100011 |
| d | 100 | 01100100 |
| e | 101 | 01100101 |
| f | 102 | 01100110 |
| g | 103 | 01100111 |
| h | 104 | 01101000 |
| i | 105 | 01101001 |
| j | 106 | 01101010 |
| k | 107 | 01101011 |
| l | 108 | 01101100 |
| m | 109 | 01101101 |
| n | 110 | 01101110 |
| o | 111 | 01101111 |
| p | 112 | 01110000 |
| q | 113 | 01110001 |
| r | 114 | 01110010 |
| s | 115 | 01110011 |
| t | 116 | 01110100 |
| u | 117 | 01110101 |
| v | 118 | 01110110 |
| w | 119 | 01110111 |
| x | 120 | 01111000 |
| y | 121 | 01111001 |
| z | 122 | 01111010 |
Chữ Số (0–9)
| Ký tự | Thập phân | Nhị phân |
|---|---|---|
| 0 | 48 | 00110000 |
| 1 | 49 | 00110001 |
| 2 | 50 | 00110010 |
| 3 | 51 | 00110011 |
| 4 | 52 | 00110100 |
| 5 | 53 | 00110101 |
| 6 | 54 | 00110110 |
| 7 | 55 | 00110111 |
| 8 | 56 | 00111000 |
| 9 | 57 | 00111001 |
Khoảng Trắng & Dấu Câu Phổ Biến
| Ký tự | Tên | Thập phân | Nhị phân |
|---|---|---|---|
| (khoảng trắng) | Khoảng trắng | 32 | 00100000 |
| ! | Dấu chấm than | 33 | 00100001 |
| " | Dấu ngoặc kép | 34 | 00100010 |
| # | Dấu thăng | 35 | 00100011 |
| $ | Dấu đô la | 36 | 00100100 |
| % | Dấu phần trăm | 37 | 00100101 |
| & | Dấu và | 38 | 00100110 |
| ' | Dấu ngoặc đơn | 39 | 00100111 |
| ( | Ngoặc trái | 40 | 00101000 |
| ) | Ngoặc phải | 41 | 00101001 |
| * | Dấu sao | 42 | 00101010 |
| + | Dấu cộng | 43 | 00101011 |
| , | Dấu phẩy | 44 | 00101100 |
| - | Dấu gạch ngang | 45 | 00101101 |
| . | Dấu chấm | 46 | 00101110 |
| / | Dấu gạch chéo | 47 | 00101111 |
| : | Dấu hai chấm | 58 | 00111010 |
| ; | Dấu chấm phẩy | 59 | 00111011 |
| ? | Dấu chấm hỏi | 63 | 00111111 |
| @ | Dấu at | 64 | 01000000 |
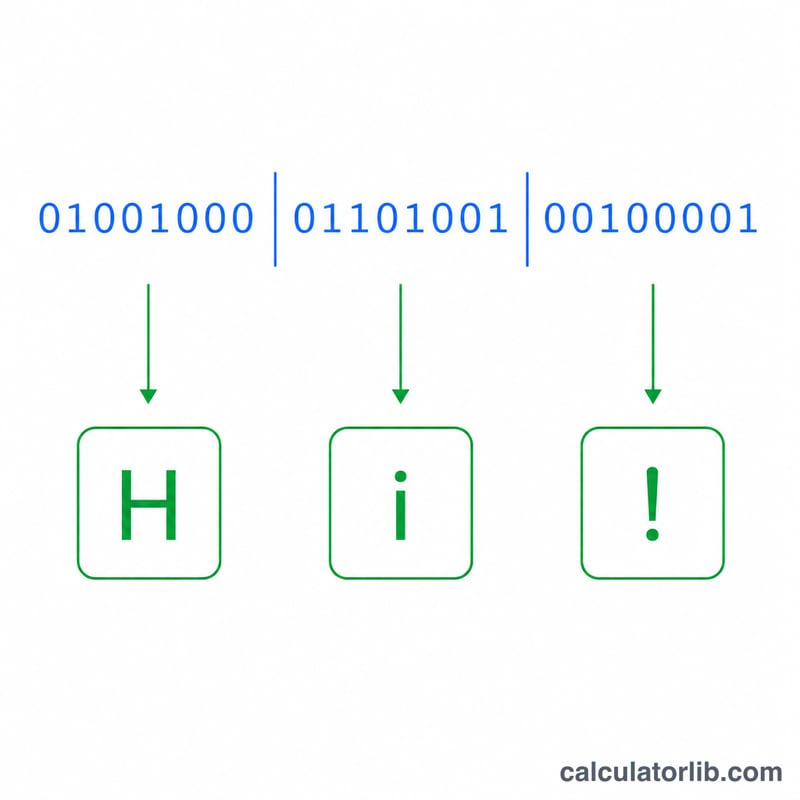
Một ví dụ dài hơn, nhị phân 01001000 01101001 giải mã thành cặp thập phân 72 và 105, cho ra văn bản Hi. Để đi theo hướng khác, bộ chuyển đổi Văn bản sang Nhị phân biến Hi thành 01001000 01101001.
Các Thuật Ngữ Chính Được Giải Thích
- Bit
- Đơn vị thông tin kỹ thuật số nhỏ nhất, chứa một giá trị nhị phân duy nhất là 0 hoặc 1. Từ này là viết tắt của "binary digit" (chữ số nhị phân).
- Byte
- Một nhóm 8 bit được xử lý như một đơn vị. Một byte có thể đại diện cho \(2^8 = 256\) giá trị phân biệt (0–255), vừa đủ để mã hóa mọi ký tự trong bộ ASCII mở rộng. Đây là lý do tại sao văn bản nhị phân được nhóm thành các khúc 8 bit.
- Nhị phân / Cơ số-2
-
Một hệ thống số sử dụng chỉ hai ký hiệu, 0 và 1. Mỗi vị trí đại diện cho một lũy thừa của hai; đọc từ phải sang trái các giá trị vị trí là \(1, 2, 4, 8, 16, 32, 64, 128\). Ví dụ,
01000001= 64 + 1 = 65. - ASCII
- Mã Tiêu Chuẩn Mỹ cho Trao Đổi Thông Tin, một mã ký tự ánh xạ các số nguyên 0–127 tới các chữ cái, chữ số, dấu câu và mã kiểm soát. ASCII tiêu chuẩn sử dụng 7 bit; một bit dẫn đầu thứ tám (thường là 0) đệm nó thành một byte đầy đủ.
- Điểm Mã
-
Giá trị số được gán cho một ký tự duy nhất trong một lược đồ mã hóa. Trong ASCII, chữ cái
Acó điểm mã là 65; cùng một ký tự có điểm mã Unicode là U+0041 (cũng là 65). - Mã Hóa Ký Tự
- Bộ quy tắc ánh xạ ký tự thành điểm mã số và sau đó thành byte để lưu trữ hoặc truyền tải. ASCII, Latin-1 và UTF-8 đều là các mã hóa; chọn cái đúng đảm bảo byte được giải mã trở lại thành văn bản dự định.
- Unicode
- Một tiêu chuẩn ký tự phổ quát gán một điểm mã duy nhất cho mọi ký tự trong các hệ thống chữ viết của thế giới, vượt far beyond ASCII's 128 characters. Các điểm mã 128 đầu tiên của nó giống hệt như ASCII, vì vậy văn bản tiếng Anh cơ bản giải mã theo cách tương tự dưới cả hai.
- UTF-8
- Mã hóa phổ biến nhất cho Unicode trên web. Nó biểu diễn các ký tự ASCII trong một byte duy nhất (khớp với ASCII chính xác) và sử dụng 2–4 byte cho các điểm mã cao hơn, giữ văn bản tiếng Anh thuần túy hoàn toàn tương thích ngược.
Câu hỏi thường gặp
Vì sao chuỗi nhị phân phải chia thành nhóm 8 bit? Bảng mã ASCII tiêu chuẩn dùng 8 bit (một byte) cho mỗi ký tự. Công cụ cắt dữ liệu đầu vào thành từng đoạn 8 bit, nhờ đó mỗi byte tương ứng chính xác với một ký tự.
Nếu các nhóm của tôi không đủ đúng 8 bit thì sao? Công cụ sẽ xử lý các chữ số tìm được theo từng đoạn 8 bit, lần lượt từ trái sang phải. Để có kết quả chính xác, hãy đảm bảo mỗi byte của ký tự có đủ 8 chữ số.
Công cụ có hỗ trợ ký tự mở rộng không? Các giá trị từ 0–127 là ASCII tiêu chuẩn; các giá trị từ 128–255 ứng với ký tự mở rộng, và giá trị byte sẽ được dùng trực tiếp làm điểm mã (code point) Unicode.