
Что такое URL-кодирование?
URL-кодирование, или процентное кодирование (percent-encoding), — это механизм, описанный в стандарте RFC 3986, для представления произвольных данных внутри URI (унифицированного идентификатора ресурса). Многие символы — пробелы, слэши, знаки вопроса, амперсанды, а также буквы вне набора ASCII — имеют в URL особое значение или попросту небезопасны. Процентное кодирование заменяет каждый такой байт знаком процента (%) и двумя шестнадцатеричными цифрами, обозначающими значение этого байта.
$$\text{Output} = \operatorname{encode}\!\left(\text{Text}\right) = \text{each byte} \to \begin{cases} \text{char}, & \text{if unreserved } (A\text{-}Z,\,a\text{-}z,\,0\text{-}9,\,\text{-}\_.\sim) \\ \text{\%XX}, & \text{otherwise (UTF-8 hex)} \end{cases}$$
Как пользоваться калькулятором
Выберите режим Кодировать, чтобы превратить обычный текст в безопасную для URL строку, или Декодировать, чтобы вернуть процентно-закодированную строку обратно в читаемый вид. Введите или вставьте текст и нажмите кнопку. Инструмент также покажет длину входных и выходных данных в символах — так вы увидите, насколько кодирование увеличило строку.
Как это работает
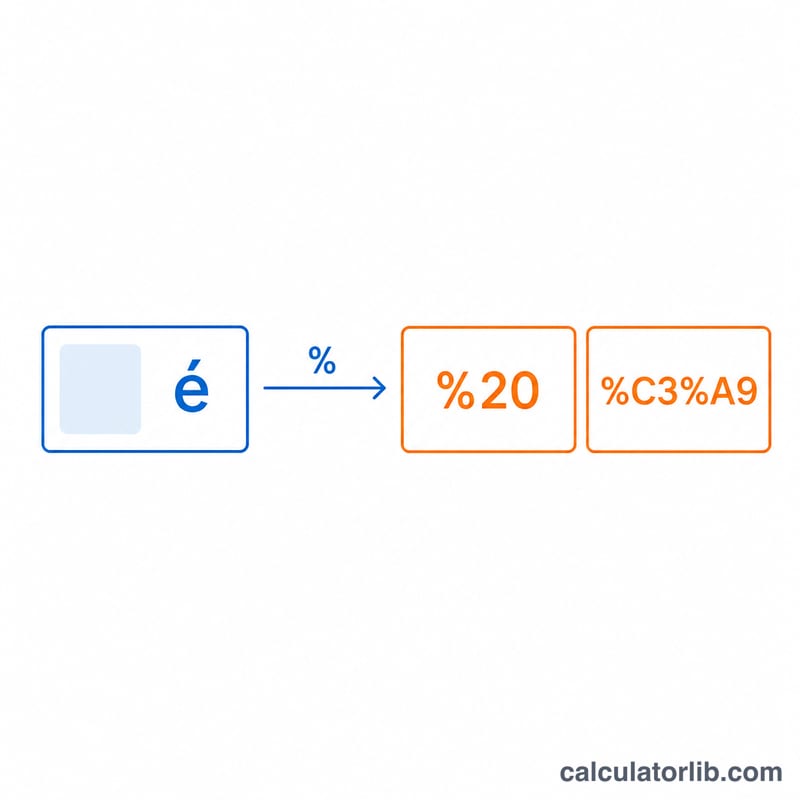
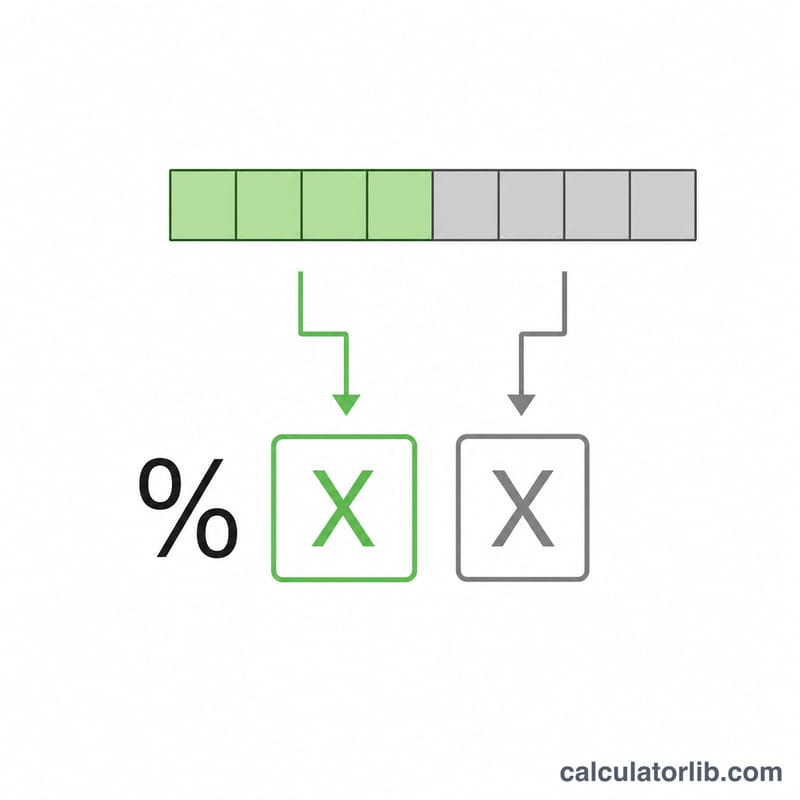
К незарезервированным символам относятся A–Z a–z 0–9 - _ . ~. Любой байт вне этого набора подлежит кодированию. Например, пробел имеет значение байта 32, то есть 0x20 в шестнадцатеричном виде, поэтому он превращается в %20. Сначала текст переводится в байты с помощью UTF-8, поэтому многобайтовые символы (эмодзи или буквы с диакритикой) кодируются побайтно. Декодирование выполняет обратное действие: каждая тройка %XX разбирается как шестнадцатеричный байт, а полученные байты интерпретируются как UTF-8.
$$\text{Output} = \operatorname{decode}\!\left(\text{Text}\right) = \text{scan} \to \begin{cases} \text{byte}(XX), & \text{for each } \text{\%XX} \\ \text{space}, & \text{for } + \\ \text{char}, & \text{otherwise} \end{cases}\ \text{as UTF-8}$$
Разбор примера
Кодируем hello world!: буквы h-e-l-l-o являются незарезервированными и остаются без изменений. Пробел превращается в %20, а восклицательный знак (байт 33 = 0x21) — в %21. В результате получаем hello%20world%21.
Частые вопросы
Кодируется ли знак «плюс» как пробел? При кодировании пробелы превращаются в %20 (стиль RFC 3986). При декодировании символ + трактуется как пробел — для совместимости с данными веб-форм.
Почему некоторые символы остаются без изменений? Буквы, цифры и четыре незарезервированных символа - _ . ~ по правилам RFC 3986 в кодировании не нуждаются.
Поддерживается ли Unicode? Да. Текст обрабатывается как UTF-8, поэтому символы вне ASCII кодируются несколькими байтами %XX и корректно декодируются обратно.