
What is URL Encoding?
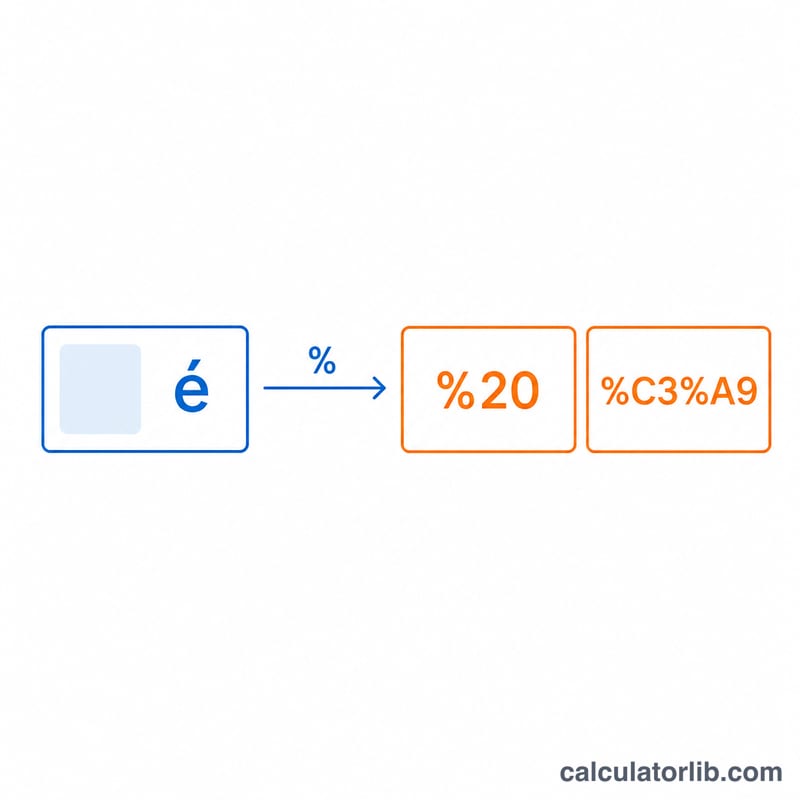
URL encoding, also called percent-encoding, is a mechanism defined by RFC 3986 for representing arbitrary data in a Uniform Resource Identifier (URI). Many characters — spaces, slashes, question marks, ampersands, and non-ASCII letters — have special meaning or are simply unsafe inside a URL. Percent-encoding replaces each such byte with a percent sign (%) followed by two hexadecimal digits representing the byte's value.
How to Use This Calculator
Choose Encode to convert plain text into a URL-safe string, or Decode to turn a percent-encoded string back into readable text. Type or paste your text and submit. The tool also reports the input and output character lengths so you can see how much expansion the encoding introduced.
The Formula Explained
The unreserved character set is A–Z a–z 0–9 - _ . ~. Any byte outside this set is encoded. The encoding rule is:
$$\text{Output} = \operatorname{encode}\!\left(\text{Text}\right) = \text{each byte} \to \begin{cases} \text{char}, & \text{if unreserved } (A\text{-}Z,\,a\text{-}z,\,0\text{-}9,\,\text{-}\_.\sim) \\ \text{\%XX}, & \text{otherwise (UTF-8 hex)} \end{cases}$$
For example the space character has byte value 32, which is 0x20 in hex, so it becomes %20. The text is first converted to bytes using UTF-8, so multibyte characters (like emoji or accented letters) are encoded byte-by-byte. Decoding reverses the process:
$$\text{Output} = \operatorname{decode}\!\left(\text{Text}\right) = \text{scan} \to \begin{cases} \text{byte}(XX), & \text{for each } \text{\%XX} \\ \text{space}, & \text{for } + \\ \text{char}, & \text{otherwise} \end{cases}\ \text{as UTF-8}$$
each %XX triple is parsed as a hex byte, and the collected bytes are interpreted as UTF-8.
Worked Example
Encoding hello world!: the letters and h-e-l-l-o are unreserved and stay the same. The space becomes %20 and the exclamation mark (byte 33 = 0x21) becomes %21. The result is hello%20world%21.
FAQ
Does this encode the plus sign as a space? When encoding, spaces become %20 (RFC 3986 style). When decoding, a literal + is treated as a space for compatibility with form data.
Why are some characters left unchanged? Letters, digits, and the four unreserved symbols - _ . ~ never need encoding under RFC 3986.
Does it support Unicode? Yes. Text is processed as UTF-8, so characters outside ASCII are encoded as multiple %XX bytes and decoded back correctly.