
Mã hóa URL là gì?
Mã hóa URL, còn gọi là percent-encoding (mã hóa phần trăm), là cơ chế được định nghĩa trong chuẩn RFC 3986 để biểu diễn dữ liệu bất kỳ bên trong một Định danh Tài nguyên Thống nhất (URI). Nhiều ký tự — như dấu cách, dấu gạch chéo, dấu hỏi, dấu và (&) hay các chữ cái không thuộc ASCII — đều mang ý nghĩa đặc biệt hoặc đơn giản là không an toàn khi nằm trong URL. Percent-encoding sẽ thay thế mỗi byte như vậy bằng dấu phần trăm (%) theo sau là hai chữ số thập lục phân (hex) biểu thị giá trị của byte đó.
Cách sử dụng công cụ này
Chọn Mã hóa để chuyển văn bản thường thành chuỗi an toàn cho URL, hoặc chọn Giải mã để biến một chuỗi đã percent-encode trở lại thành văn bản dễ đọc. Hãy nhập hoặc dán văn bản của bạn rồi bấm thực hiện. Công cụ cũng hiển thị độ dài ký tự của đầu vào và đầu ra, giúp bạn thấy rõ việc mã hóa đã làm chuỗi dài thêm bao nhiêu.
Giải thích công thức
Quá trình mã hóa có thể biểu diễn như sau:
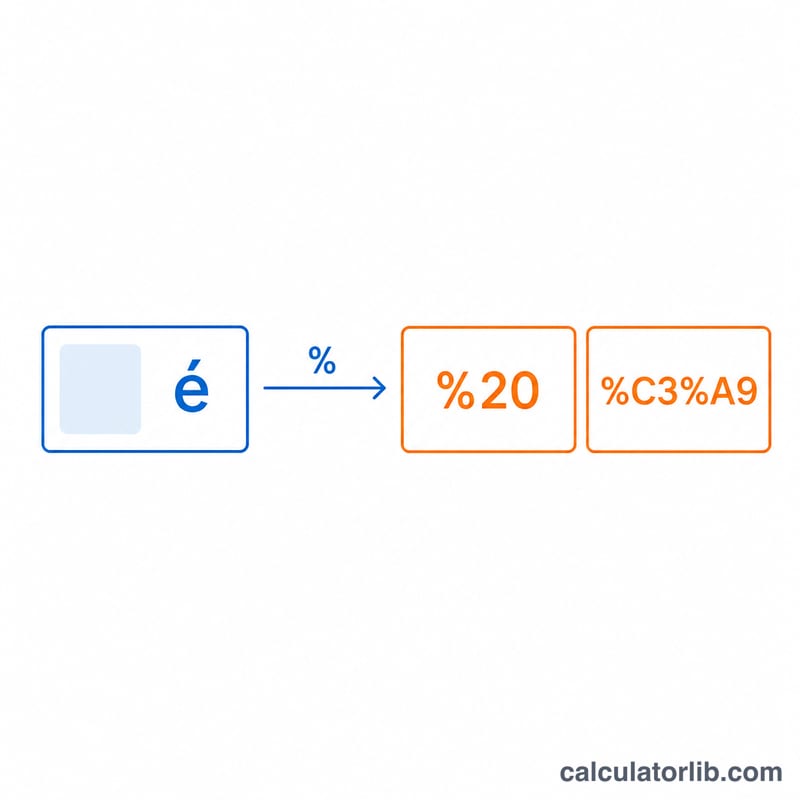
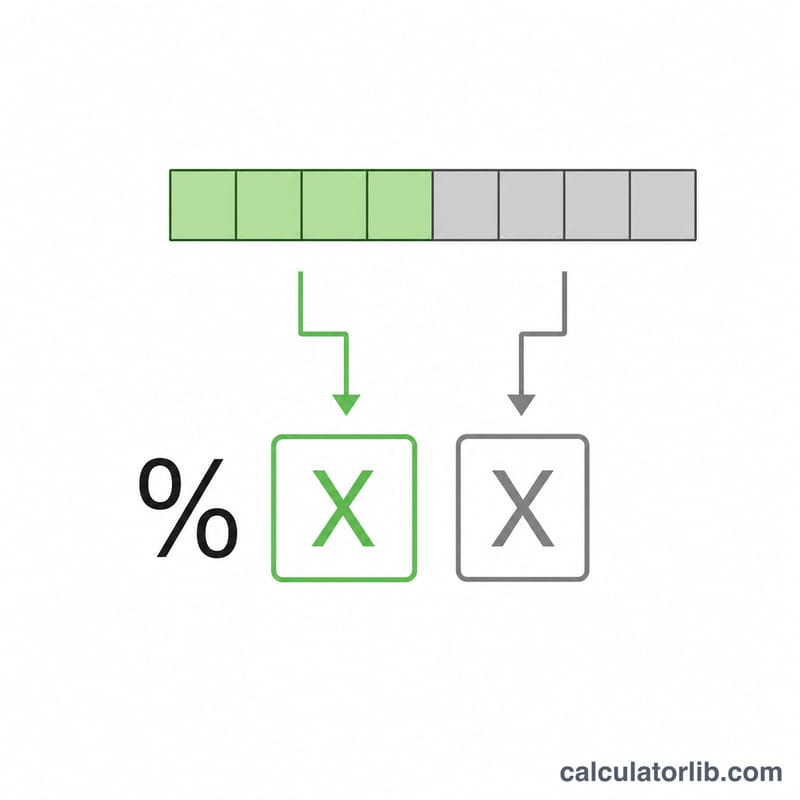
$$\text{Output} = \operatorname{encode}\!\left(\text{Text}\right) = \text{each byte} \to \begin{cases} \text{char}, & \text{if unreserved } (A\text{-}Z,\,a\text{-}z,\,0\text{-}9,\,\text{-}\_.\sim) \\ \text{\%XX}, & \text{otherwise (UTF-8 hex)} \end{cases}$$Tập ký tự không dành riêng (unreserved) gồm A–Z a–z 0–9 - _ . ~. Mọi byte nằm ngoài tập này đều sẽ được mã hóa. Ví dụ, ký tự dấu cách có giá trị byte là \(32\), tương đương 0x20 trong hệ hex, nên nó trở thành %20. Văn bản trước tiên được chuyển thành các byte bằng bảng mã UTF-8, vì vậy các ký tự nhiều byte (như emoji hay chữ cái có dấu) được mã hóa theo từng byte một. Quá trình giải mã thì làm ngược lại: mỗi bộ ba %XX được hiểu là một byte hex, sau đó toàn bộ các byte thu được sẽ được diễn giải theo UTF-8.
Ví dụ minh họa
Mã hóa chuỗi hello world!: các chữ cái h-e-l-l-o đều thuộc tập không dành riêng nên được giữ nguyên. Dấu cách trở thành %20 và dấu chấm than (byte \(33 = \) 0x21) trở thành %21. Kết quả là hello%20world%21.
Câu hỏi thường gặp
Công cụ này có mã hóa dấu cộng thành dấu cách không? Khi mã hóa, dấu cách sẽ trở thành %20 (theo đúng phong cách RFC 3986). Khi giải mã, ký tự + được xem như dấu cách để tương thích với dữ liệu biểu mẫu (form data).
Vì sao một số ký tự được giữ nguyên? Các chữ cái, chữ số và bốn ký hiệu không dành riêng là - _ . ~ không bao giờ cần mã hóa theo chuẩn RFC 3986.
Công cụ có hỗ trợ Unicode không? Có. Văn bản được xử lý dưới dạng UTF-8, nên các ký tự ngoài ASCII sẽ được mã hóa thành nhiều byte %XX và giải mã trở lại một cách chính xác.