
¿Qué es la codificación de URL?
La codificación de URL, también conocida como codificación porcentual (percent-encoding), es un mecanismo definido por el RFC 3986 para representar datos arbitrarios dentro de un identificador uniforme de recursos (URI). Muchos caracteres —espacios, barras, signos de interrogación, ampersands y letras no ASCII— tienen un significado especial o, sencillamente, no son seguros dentro de una URL. La codificación porcentual sustituye cada uno de esos bytes por un signo de porcentaje (%) seguido de dos dígitos hexadecimales que representan el valor del byte.
Cómo usar esta calculadora
Selecciona Codificar para convertir texto normal en una cadena apta para URL, o Decodificar para transformar una cadena con codificación porcentual en texto legible. Escribe o pega tu texto y envíalo. La herramienta también te indica la longitud de la entrada y la salida en caracteres, de modo que puedas comprobar cuánto se expandió el texto al codificarlo.
La fórmula explicada
El conjunto de caracteres no reservados es A–Z a–z 0–9 - _ . ~. Cualquier byte que quede fuera de este conjunto se codifica.
$$\text{Output} = \operatorname{encode}\!\left(\text{Text}\right) = \text{each byte} \to \begin{cases} \text{char}, & \text{if unreserved } (A\text{-}Z,\,a\text{-}z,\,0\text{-}9,\,\text{-}\_.\sim) \\ \text{\%XX}, & \text{otherwise (UTF-8 hex)} \end{cases}$$
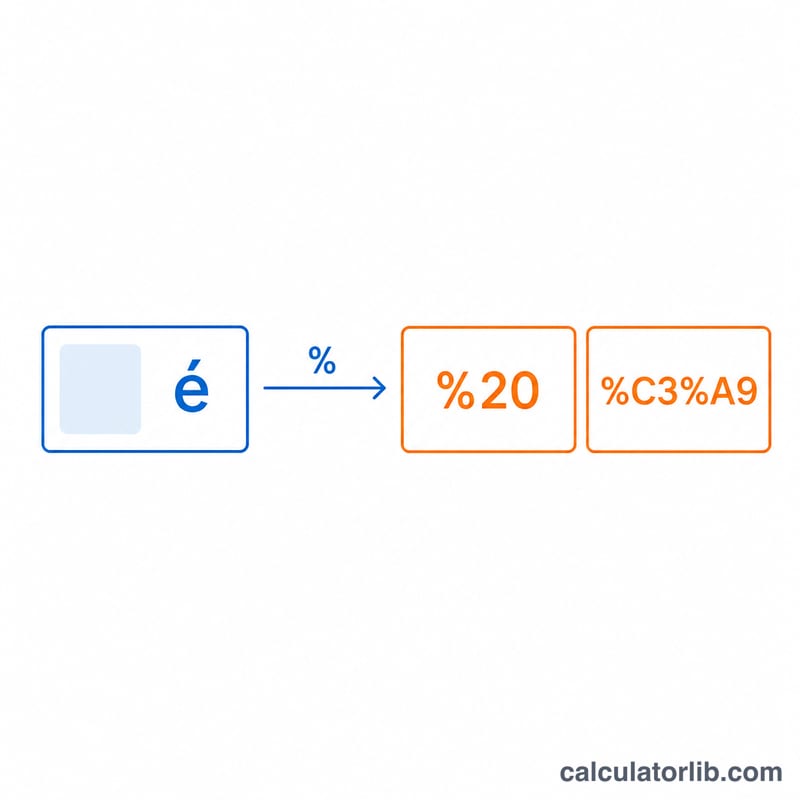
Por ejemplo, el carácter de espacio tiene el valor de byte 32, que en hexadecimal es 0x20, así que se convierte en %20. El texto se convierte primero en bytes mediante UTF-8, de modo que los caracteres multibyte (como los emojis o las letras acentuadas) se codifican byte a byte. Al decodificar se invierte el proceso: cada trío %XX se interpreta como un byte hexadecimal, y el conjunto de bytes resultante se lee como UTF-8.
$$\text{Output} = \operatorname{decode}\!\left(\text{Text}\right) = \text{scan} \to \begin{cases} \text{byte}(XX), & \text{for each } \text{\%XX} \\ \text{space}, & \text{for } + \\ \text{char}, & \text{otherwise} \end{cases}\ \text{as UTF-8}$$
Ejemplo resuelto
Al codificar hello world!: las letras h-e-l-l-o son no reservadas y se mantienen igual. El espacio pasa a ser %20 y el signo de exclamación (byte 33 = 0x21) se convierte en %21. El resultado es hello%20world%21.
Preguntas frecuentes
¿Codifica el signo más como un espacio? Al codificar, los espacios se convierten en %20 (estilo RFC 3986). Al decodificar, un + literal se interpreta como un espacio para mantener la compatibilidad con los datos de formularios.
¿Por qué algunos caracteres se quedan sin cambios? Las letras, los dígitos y los cuatro símbolos no reservados - _ . ~ nunca necesitan codificarse según el RFC 3986.
¿Es compatible con Unicode? Sí. El texto se procesa como UTF-8, por lo que los caracteres fuera de ASCII se codifican como varios bytes %XX y se decodifican correctamente de nuevo.