
Qu'est-ce que l'encodage d'URL ?
L'encodage d'URL, aussi appelé encodage pourcent (percent-encoding), est un mécanisme défini par le RFC 3986 qui permet de représenter n'importe quelle donnée au sein d'un identifiant de ressource uniforme (URI). De nombreux caractères — espaces, barres obliques, points d'interrogation, esperluettes ou lettres non ASCII — ont une signification particulière ou ne peuvent tout simplement pas figurer tels quels dans une URL. L'encodage pourcent remplace chacun de ces octets par un signe pourcent (%) suivi de deux chiffres hexadécimaux qui représentent la valeur de l'octet.
Comment utiliser cet outil
Sélectionnez Encoder pour transformer un texte brut en une chaîne compatible avec les URL, ou Décoder pour retrouver le texte lisible à partir d'une chaîne encodée en pourcent. Saisissez ou collez votre texte, puis validez. L'outil affiche également le nombre de caractères en entrée et en sortie, ce qui vous permet de visualiser l'augmentation de taille induite par l'encodage.
La formule expliquée
L'ensemble des caractères non réservés est A–Z a–z 0–9 - _ . ~. Tout octet en dehors de cet ensemble est encodé.
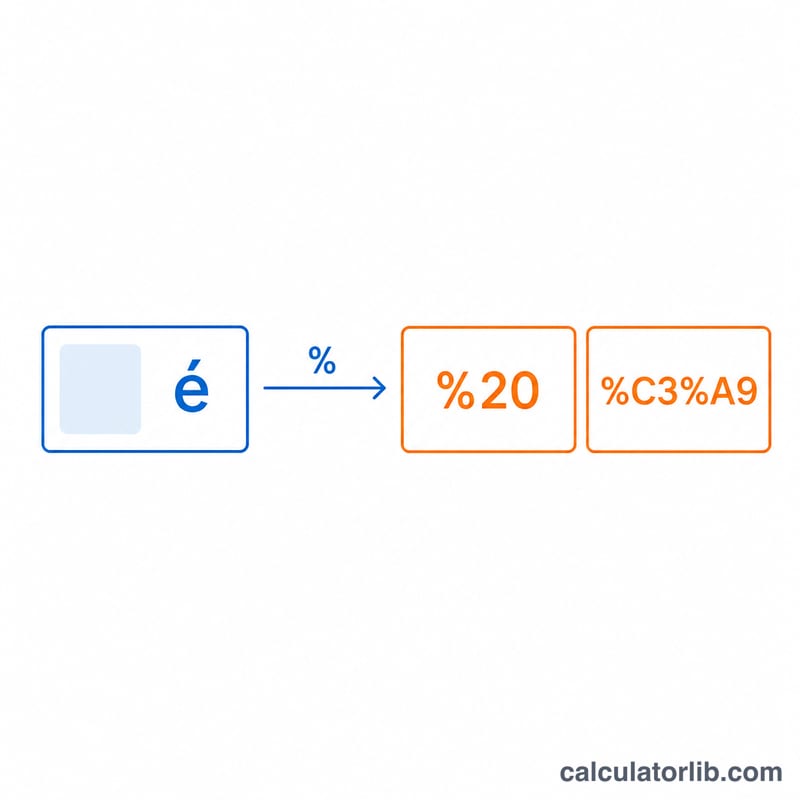
Par exemple, le caractère espace a pour valeur d'octet 32, soit 0x20 en hexadécimal : il devient donc %20. Le texte est d'abord converti en octets en UTF-8, si bien que les caractères multioctets (émojis ou lettres accentuées) sont encodés octet par octet. Le décodage suit le chemin inverse : chaque triplet %XX est interprété comme un octet hexadécimal, et l'ensemble des octets recueillis est ensuite lu comme de l'UTF-8.
Exemple concret
Encodons hello world! : les lettres h-e-l-l-o sont non réservées et restent inchangées. L'espace devient %20 et le point d'exclamation (octet 33 = 0x21) devient %21. Le résultat est hello%20world%21.
FAQ
Le signe plus est-il encodé comme une espace ? À l'encodage, les espaces deviennent %20 (conformément au RFC 3986). Au décodage, un + littéral est interprété comme une espace, pour rester compatible avec les données de formulaire.
Pourquoi certains caractères restent-ils inchangés ? Les lettres, les chiffres et les quatre symboles non réservés - _ . ~ n'ont jamais besoin d'être encodés selon le RFC 3986.
L'Unicode est-il pris en charge ? Oui. Le texte est traité en UTF-8 : les caractères hors ASCII sont donc encodés en plusieurs octets %XX et décodés correctement par la suite.