这个计算器能做什么
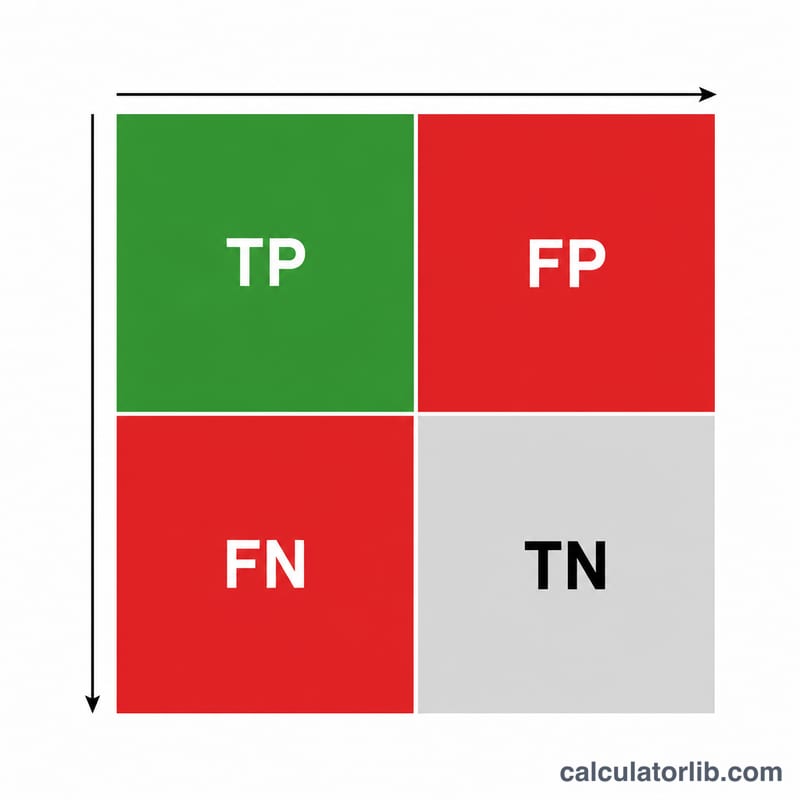
本工具通过计算三个核心指标来评估二分类模型的性能:查准率(Precision,精确率)、查全率(Recall,召回率)以及 F1 分数。你只需提供混淆矩阵中的原始计数——真阳性(TP)、假阳性(FP)和假阴性(FN)——工具便会以百分比形式返回每个指标。这些指标在机器学习、信息检索、医学检测,以及任何需要将样本划分为"正类"和"负类"的领域中都被广泛使用。
如何使用
输入 真阳性 数量(被正确预测为正类的样本)、假阳性 数量(被错误预测为正类的负类样本),以及 假阴性 数量(被模型漏掉的正类样本)。点击计算即可查看查准率、查全率和 F1 分数。计算这几个指标无需用到真阴性(TN)。
公式详解
查准率 = TP /(TP + FP) 回答的是:"在我判定为正类的所有样本中,有多少是判对的?" 查准率高,意味着误报(虚警)很少。
查全率 = TP /(TP + FN) 回答的是:"在所有实际为正类的样本中,我抓住了多少?" 查全率高,意味着漏检很少。
$$\text{Precision} = \frac{\text{TP}}{\text{TP} + \text{FP}}, \quad \text{Recall} = \frac{\text{TP}}{\text{TP} + \text{FN}}$$F1 分数 是两者的调和平均数:F1 = 2 ·(查准率 · 查全率)/(查准率 + 查全率)。它兼顾了二者,在类别分布不平衡时尤其有用。
$$\text{F1} = 2 \cdot \frac{\text{Precision} \cdot \text{Recall}}{\text{Precision} + \text{Recall}}$$
实例演算
假设一个垃圾邮件过滤器将 100 封邮件标记为垃圾邮件。其中 80 封确实是垃圾邮件(TP),20 封其实不是(FP)。同时它还漏掉了 10 封真正的垃圾邮件(FN)。查准率 = \(80 / (80 + 20) = 0.80 = 80\%\)。查全率 = \(80 / (80 + 10) = 0.889 = 88.89\%\)。F1 = \(2 \cdot (0.80 \cdot 0.889) / (0.80 + 0.889) = 84.21\%\)。
常见问题
什么时候应该优先看重查准率? 当误报代价高昂时,优先看重查准率(例如把正常邮件误判为垃圾邮件)。当漏检代价高昂时,则优先看重查全率(例如癌症筛查)。
为什么要用 F1 分数? 在数据不平衡的情况下,准确率(Accuracy)可能具有误导性。F1 分数将查准率和查全率合并为一个均衡的数值。
如果分母为零会怎样? 如果 TP+FP 或 TP+FN 为零,该指标在数学上无定义;这种情况下本计算器会显示 0%。