這個計算器的用途
本工具透過三項核心指標評估二元分類模型的表現:精確率(Precision)、召回率(Recall),以及 F1 分數。你只要從混淆矩陣中提供原始數值——真陽性(TP)、偽陽性(FP)與偽陰性(FN)——系統就會以百分比形式回傳每項指標。這些指標廣泛應用於機器學習、資訊檢索、醫學檢測,以及任何需要把資料分為「正類」與「負類」的領域。
使用方法
輸入真陽性(正確預測為正類的數量)、偽陽性(被誤判為正類的負類數量),以及偽陰性(模型漏掉的正類數量)。按下計算,即可看到精確率、召回率與 F1 分數。計算這三項指標並不需要用到真陰性(TN)。
公式解析
\(\text{Precision} = \frac{\text{TP}}{\text{TP} + \text{FP}}\),回答的問題是:「在我所有判定為正類的項目中,有多少是正確的?」精確率越高,代表誤報越少。
\(\text{Recall} = \frac{\text{TP}}{\text{TP} + \text{FN}}\),回答的問題是:「在所有實際為正類的項目中,我抓到了多少?」召回率越高,代表漏掉的越少。
F1 分數則是兩者的調和平均數:$$\text{F1} = 2 \cdot \frac{\text{Precision} \cdot \text{Recall}}{\text{Precision} + \text{Recall}}$$它能在兩者之間取得平衡,特別適用於類別分布不均的情況。
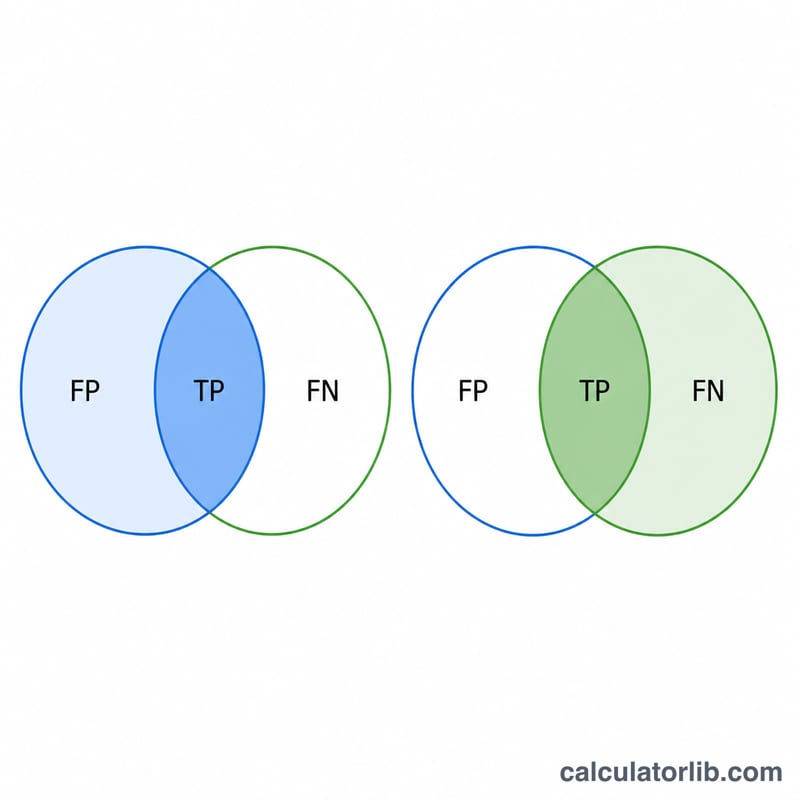
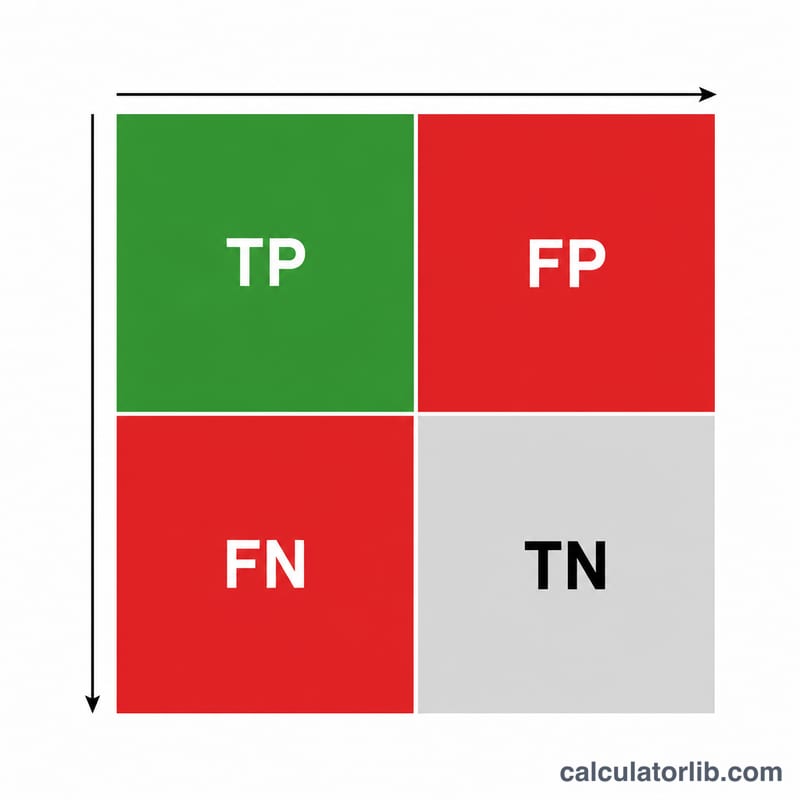
範例試算
假設一個垃圾郵件過濾器將 100 封郵件判定為垃圾郵件。其中 80 封確實是垃圾郵件(TP),20 封其實不是(FP);此外它還漏掉了 10 封真正的垃圾郵件(FN)。$$\text{Precision} = \frac{80}{80 + 20} = 0.80 = 80\%$$$$\text{Recall} = \frac{80}{80 + 10} = 0.889 = 88.89\%$$$$\text{F1} = 2 \cdot \frac{0.80 \cdot 0.889}{0.80 + 0.889} = 84.21\%$$
常見問題
什麼時候該優先考量精確率,而非召回率?當「誤報」成本高昂時,應優先重視精確率(例如把正常郵件誤判為垃圾郵件)。當「漏判」成本高昂時,則應優先重視召回率(例如癌症篩檢)。
為什麼要使用 F1 分數?在資料類別分布不均時,準確率(Accuracy)可能造成誤導。F1 分數把精確率與召回率整合為單一且兼顧兩者的數值。
如果分母為零會怎樣?若 TP+FP 或 TP+FN 為零,該指標在數學上無法定義;此時本計算器會回報 0%。