このツールでできること
本ツールは、二値分類モデルの性能を3つの主要指標—適合率(Precision)、再現率(Recall)、F1スコア—で評価します。混同行列から得られる基本的な件数、すなわち真陽性(TP)、偽陽性(FP)、偽陰性(FN)を入力するだけで、各指標をパーセンテージで返します。これらの指標は、機械学習や情報検索、医療検査をはじめ、対象を「陽性」「陰性」に分類するあらゆる分野で広く使われています。
使い方
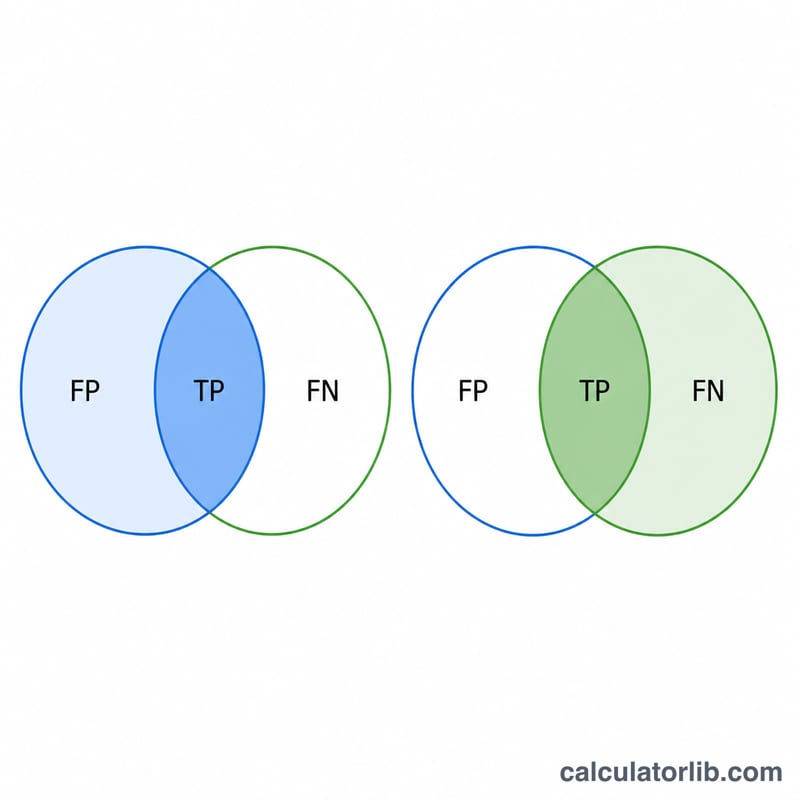
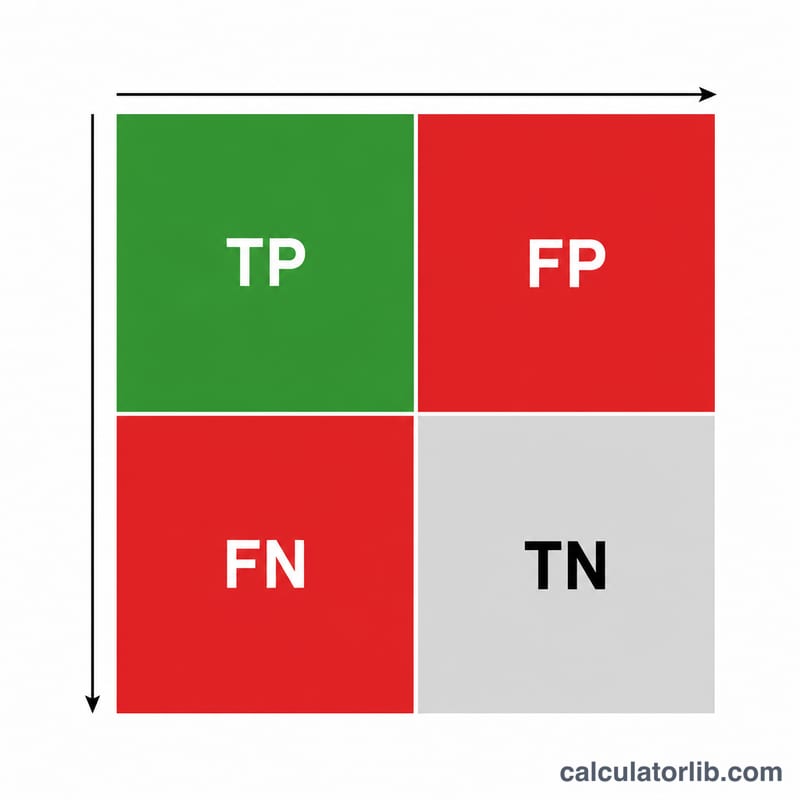
真陽性(TP)=正しく陽性と予測した数、偽陽性(FP)=陰性を誤って陽性と予測した数、偽陰性(FN)=見逃した陽性の数、をそれぞれ入力します。「計算する」をクリックすると、適合率・再現率・F1スコアが表示されます。これらの指標の算出に真陰性(TN)は不要です。
計算式の解説
\(\text{適合率} = \frac{\text{TP}}{\text{TP} + \text{FP}}\)は、「陽性と判定したもののうち、正しかった割合はどれくらいか?」を表します。適合率が高いほど、誤検出(フォルスアラーム)が少ないことを意味します。
\(\text{再現率} = \frac{\text{TP}}{\text{TP} + \text{FN}}\)は、「本来陽性だったもののうち、どれだけ拾えたか?」を表します。再現率が高いほど、見逃しが少ないことを意味します。
F1スコアは、この2つの調和平均です。$$\text{F1} = 2 \cdot \frac{\text{適合率} \cdot \text{再現率}}{\text{適合率} + \text{再現率}}$$両者のバランスを取った指標で、クラスの偏り(不均衡データ)があるときに特に役立ちます。
計算例
あるスパムフィルターが100通のメールをスパムと判定したとします。そのうち80通は本当にスパム(TP)、残り20通は誤判定(FP)でした。さらに、本物のスパム10通を見逃しています(FN)。$$\text{適合率} = \frac{80}{80 + 20} = 0.80 = 80\%$$$$\text{再現率} = \frac{80}{80 + 10} = 0.889 = 88.89\%$$$$\text{F1} = 2 \times \frac{0.80 \times 0.889}{0.80 + 0.889} = 84.21\%$$ となります。
よくある質問
適合率と再現率、どちらを優先すべき? 偽陽性のコストが大きい場合は適合率を重視します(例:正当なメールをスパムと誤判定してしまうケース)。一方、陽性の見逃しが致命的な場合は再現率を重視します(例:がん検診)。
なぜF1スコアを使うのか? 不均衡データでは「正解率(Accuracy)」が実態を見誤らせることがあります。F1スコアは適合率と再現率を1つのバランスの取れた数値にまとめてくれます。
分母がゼロになる場合は? TP+FP または TP+FN がゼロのとき、指標は定義できません。本ツールではその場合、0%と表示します。