
Qu'est-ce que le calculateur de coût des tokens IA/LLM ?
La plupart des API de grands modèles de langage (LLM) — comme celles d'OpenAI, Anthropic, Google et d'autres — facturent au token, avec des tarifs distincts pour les tokens d'entrée (le prompt) et de sortie (la réponse générée). Les prix sont généralement exprimés pour 1 000 tokens (ou par million). Ce calculateur transforme ces tarifs en un montant clair en dollars : vous pouvez ainsi budgétiser une fonctionnalité, comparer plusieurs modèles ou anticiper une charge de production avant la mise en ligne. À noter : ces API facturent en dollars américains (USD), à convertir en euros selon le taux de change en vigueur.
Comment l'utiliser
Saisissez le nombre de tokens d'entrée et de tokens de sortie pour une requête type, puis le prix pour 1 000 tokens dans chaque cas. Vous pouvez aussi indiquer le nombre d'appels pour étendre l'estimation à l'ensemble de votre charge de travail. Le calculateur affiche le coût par appel et le coût total, détaillé entre la part d'entrée et la part de sortie.
La formule expliquée
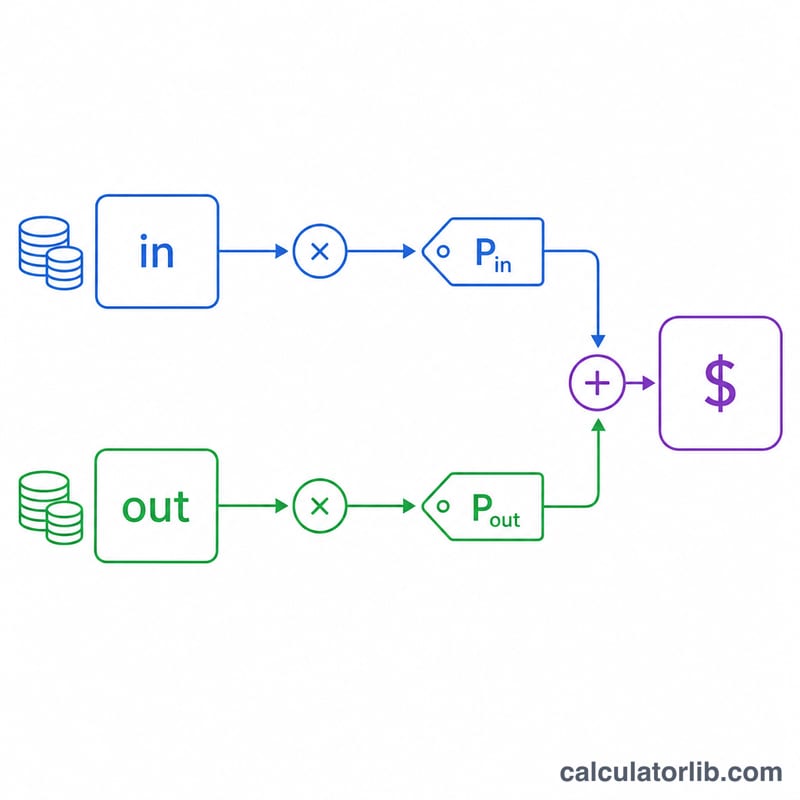
Le coût d'un seul appel se calcule ainsi :
$$\text{coût} = \frac{\text{tokens\_entrée}}{1000}\times \text{prix\_entrée} + \frac{\text{tokens\_sortie}}{1000}\times \text{prix\_sortie}$$
Chaque nombre de tokens est divisé par 1 000 car les prix sont exprimés pour 1 000 tokens. Les tokens de sortie sont généralement plus chers que ceux d'entrée, d'où leur tarification distincte. Le total correspond simplement au coût par appel multiplié par le nombre d'appels.
Exemple chiffré
Imaginons une requête qui consomme 1 000 tokens d'entrée à 0,0015 $ pour 1 000 et génère 500 tokens de sortie à 0,002 $ pour 1 000. Coût d'entrée = \((1000/1000) \times 0{,}0015 = 0{,}0015\) $. Coût de sortie = \((500/1000) \times 0{,}002 = 0{,}001\) $. Coût par appel = \(0{,}0025\) $. Pour 10 000 appels de ce type, le total s'élève à 25,00 $.
Référence actuelle des tarifs des modèles de langage (par 1K jetons)
Le tableau ci-dessous énumère les tarifs des API couramment publiés pour les modèles de langage populaires, exprimés par 1 000 jetons (1K) en dollars américains. De nombreux fournisseurs publient leurs tarifs par 1 000 000 jetons (1M) ; pour convertir, divisez le prix par 1M par 1 000. Par exemple, un modèle au prix de 5,00 $ par 1M de jetons d'entrée coûte 0,005 $ par 1K de jetons d'entrée.
| Modèle | Entrée ($/1K) | Sortie ($/1K) |
|---|---|---|
| GPT-4o | $0,0025 | $0,010 |
| GPT-4o mini | $0,00015 | $0,0006 |
| GPT-3.5 Turbo | $0,0005 | $0,0015 |
| Claude 3.5 Sonnet | $0,003 | $0,015 |
| Claude 3 Haiku | $0,00025 | $0,00125 |
| Gemini 1.5 Pro | $0,00125 | $0,005 |
| Gemini 1.5 Flash | $0,000075 | $0,0003 |
Remarque : Les tarifs des modèles de langage changent fréquemment, varient selon la région et le tier (par exemple, réductions pour contexte long, lot ou entrée mise en cache), et peuvent différer pour les modèles affinés. Vérifiez toujours le tarif actuel sur la page de tarification officielle du fournisseur avant de budgétiser. Les valeurs ci-dessus sont des chiffres de référence représentatifs à intégrer dans le calculateur, non une citation garantie.
Termes clés expliqués
- Jeton
- L'unité de base de texte qu'un modèle de langage traite. Un jeton représente environ 4 caractères ou environ ¾ d'un mot en anglais, donc 1 000 jetons correspondent approximativement à 750 mots. Les modèles facturent par jetons, non par mots ou caractères.
- Jetons d'entrée (invite)
- Tous les jetons que vous envoyez au modèle dans une demande — vos instructions, l'historique de la conversation, l'invite système et tout contexte récupéré. Ceux-ci sont facturés au tarif d'entrée.
- Jetons de sortie (complément)
- Les jetons que le modèle génère dans sa réponse. Ceux-ci sont facturés au tarif de sortie, qui est généralement supérieur au tarif d'entrée (souvent 3-4×), donc les réponses plus longues coûtent de manière disproportionnée.
- Tarification par 1K ou par 1M
- Deux façons équivalentes de citer le même prix. Un tarif de 5,00 $ par 1 000 000 jetons équivaut à 0,005 $ par 1 000 jetons. Divisez un prix par 1M par 1 000 pour obtenir le prix par 1K que ce calculateur utilise.
- Fenêtre de contexte
- Le nombre maximum de jetons (entrée plus sortie) qu'un modèle peut gérer dans une seule demande — par exemple 128K ou 1M jetons. Cela limite la quantité que vous pouvez envoyer et recevoir par appel, mais ne modifie pas en soi le prix par jeton.
- Appel / demande
- Un aller-retour vers l'API : vous envoyez des jetons d'entrée et recevez des jetons de sortie. Les dépenses totales correspondent au coût d'un appel multiplié par le nombre d'appels que vous effectuez.
FAQ
Mon fournisseur affiche un prix par million de tokens — que dois-je saisir ? Divisez le prix par million par 1 000 pour obtenir le prix pour 1 000 tokens (par exemple, 1,50 $ par million = 0,0015 $ pour 1 000).
Comment estimer le nombre de tokens ? En anglais, une règle approximative est d'environ 4 caractères ou 0,75 mot par token ; en français, le ratio peut différer légèrement. Pour plus de précision, utilisez le tokenizer de votre fournisseur.
Cela inclut-il les autres frais ? Non — seul l'usage facturé au token est pris en compte. Le fine-tuning, les images, l'audio ou le stockage font l'objet de tarifs distincts.