What is the AI/LLM Token Cost Calculator?
Most large language model (LLM) APIs — such as those from OpenAI, Anthropic, Google and others — bill by the token, with separate rates for input (prompt) tokens and output (completion) tokens. Pricing is usually quoted per 1,000 tokens (or per million). This calculator turns those rates into a clear dollar figure so you can budget a feature, compare models, or forecast a production workload before you ship it.
How to use it
Enter the number of input tokens and output tokens for a typical request, then the price per 1,000 tokens for each. Optionally enter the number of calls to scale the estimate to a full workload. The calculator returns the cost per call and the total cost, broken down into input and output components.
The formula explained
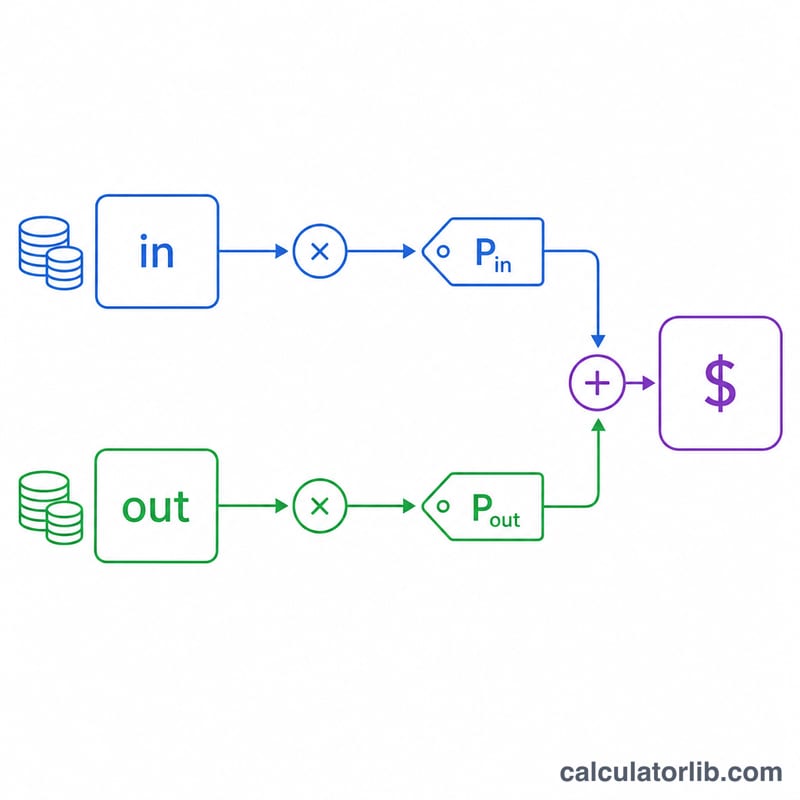
The cost of a single call is:
$$\text{cost} = \frac{\text{input\_tokens}}{1000}\times \text{input\_price} + \frac{\text{output\_tokens}}{1000}\times \text{output\_price}$$
Each token count is divided by 1,000 because prices are quoted per 1K tokens. Output tokens are typically more expensive than input tokens, which is why they are priced separately. The total is simply the per-call cost times the number of calls.
Worked example
Suppose a request uses 1,000 input tokens at $0.0015 per 1K and produces 500 output tokens at $0.002 per 1K. Input cost = \((1000/1000) \times 0.0015 = \$0.0015\). Output cost = \((500/1000) \times 0.002 = \$0.001\). Cost per call = $0.0025. Run 10,000 such calls and the total is $25.00.
Current LLM Pricing Reference (per 1K Tokens)
The table below lists commonly published API prices for popular large language models, expressed per 1,000 tokens (1K) in US dollars. Many providers publish their rates per 1,000,000 tokens (1M) instead; to convert, divide the per-1M price by 1,000. For example, a model priced at $5.00 per 1M input tokens costs $0.005 per 1K input tokens.
| Model | Input ($/1K) | Output ($/1K) |
|---|---|---|
| GPT-4o | $0.0025 | $0.010 |
| GPT-4o mini | $0.00015 | $0.0006 |
| GPT-3.5 Turbo | $0.0005 | $0.0015 |
| Claude 3.5 Sonnet | $0.003 | $0.015 |
| Claude 3 Haiku | $0.00025 | $0.00125 |
| Gemini 1.5 Pro | $0.00125 | $0.005 |
| Gemini 1.5 Flash | $0.000075 | $0.0003 |
Note: LLM pricing changes frequently, varies by region and tier (e.g. long-context, batch, or cached-input discounts), and may differ for fine-tuned models. Always verify the current rate on the official provider pricing page before budgeting. The values above are representative reference figures to plug into the calculator, not a guaranteed quote.
Key Terms Explained
- Token
- The basic unit of text an LLM processes. A token is roughly 4 characters or about ¾ of a word in English, so 1,000 tokens is approximately 750 words. Models bill by tokens, not words or characters.
- Input (prompt) tokens
- All the tokens you send to the model in a request — your instructions, the conversation history, system prompt, and any retrieved context. These are charged at the input rate.
- Output (completion) tokens
- The tokens the model generates in its reply. These are billed at the output rate, which is typically higher than the input rate (often 3–4×), so longer responses cost disproportionately more.
- Per-1K vs per-1M pricing
- Two equivalent ways of quoting the same price. A rate of $5.00 per 1,000,000 tokens equals $0.005 per 1,000 tokens. Divide a per-1M price by 1,000 to get the per-1K price this calculator uses.
- Context window
- The maximum number of tokens (input plus output) a model can handle in a single request — for example 128K or 1M tokens. It caps how much you can send and receive per call but does not by itself change the per-token price.
- Call / request
- One round-trip to the API: you send input tokens and receive output tokens. Total spend is the cost of one call multiplied by the number of calls you make.
FAQ
My provider quotes per million tokens — what do I enter? Divide the per-million price by 1,000 to get the per-1K price (e.g. $1.50 per 1M = $0.0015 per 1K).
How do I estimate token counts? A rough rule of thumb is ~4 characters or ~0.75 words per token in English, but use your provider's tokenizer for accuracy.
Does this include other fees? No — it covers token-based usage only. Fine-tuning, image, audio or storage charges are separate.