
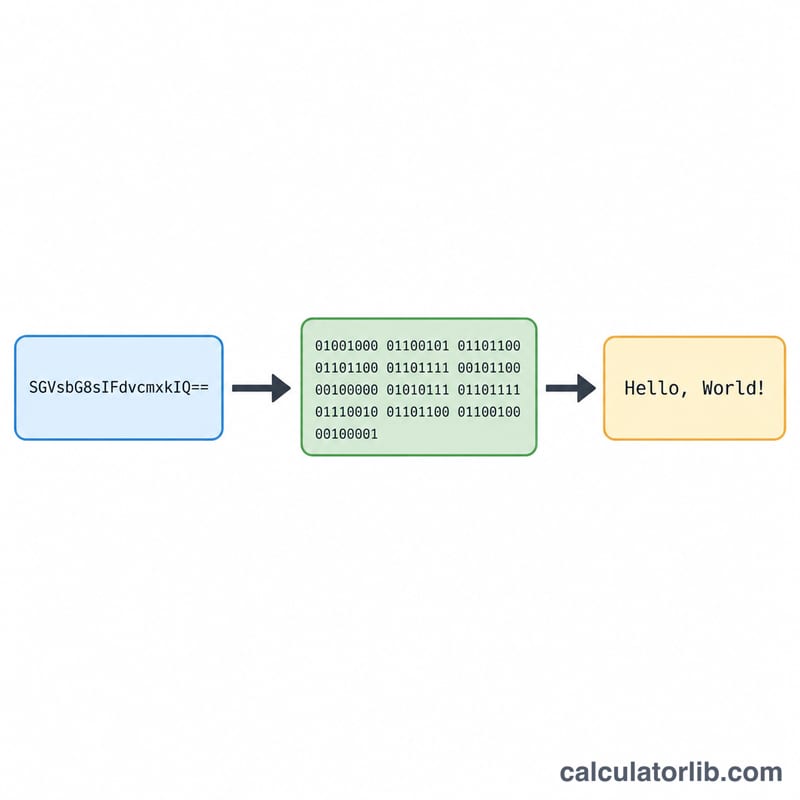
Base64デコーダーとは?
Base64は、印刷可能な64種類のASCII文字(A〜Z、a〜z、0〜9、「+」「/」)を使ってバイナリデータを表現するエンコード方式です。HTMLへの画像埋め込み、JSONやURLでのデータ送信、メール添付ファイルのエンコードなど、さまざまな場面で活躍しています。このデコーダーはその逆の処理を行い、Base64文字列を元のプレーンテキストへと戻します。
使い方
入力欄にBase64文字列を貼り付ける、または入力して実行するだけです。ツールが空白を取り除いて文字をデコードし、変換後のテキストに加えて、デコードされたバイト数、入力文字数、含まれていたパディング文字(「=」)の個数を表示します。Base64で使える文字以外が含まれている場合は、「無効(invalid)」というメッセージが表示されます。
仕組み(計算式)
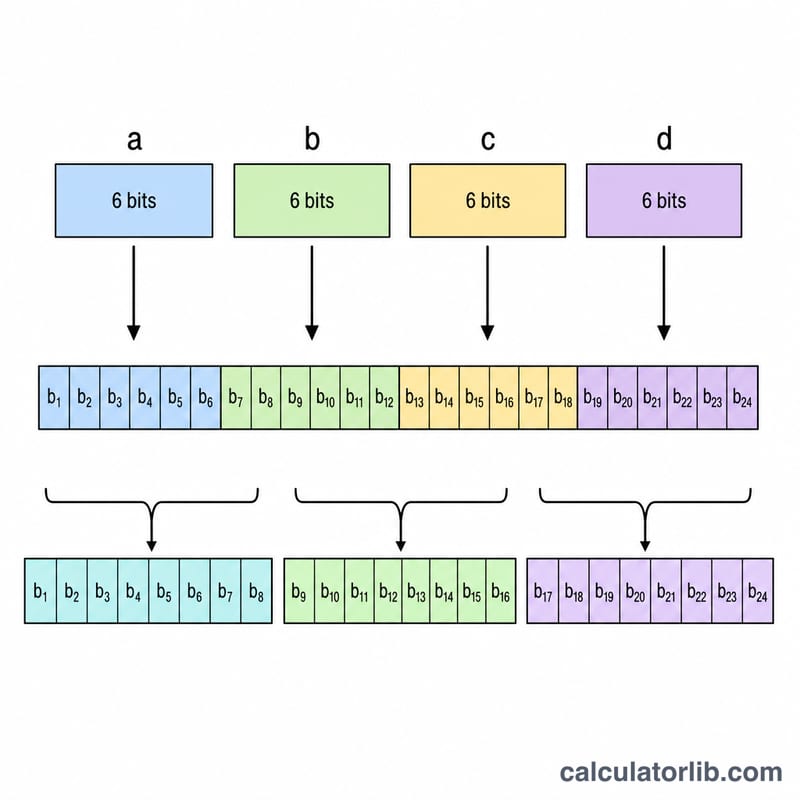
Base64の1文字は6ビットのデータを表します。つまり4文字で4×6=24ビットとなり、これがちょうど8ビットのバイト3つにきれいに収まります。元データの長さが3の倍数でない場合は、1つまたは2つの「=」(パディング文字)が末尾に追加され、エンコード後の文字列の長さが常に4の倍数になるように調整されます。デコード時には、このパディングが取り除かれ、余分なビットは破棄されます。
$$\text{Bytes} = \left\lfloor \frac{6 \times \text{Base64 chars (no padding)}}{8} \right\rfloor$$
$$\begin{gathered} \text{Bytes} = \left\lfloor \frac{6N}{8} \right\rfloor \\[1.5em] \text{where}\quad \left\{ \begin{aligned} N &= \text{valid chars of } \text{Base64 Input} \\ &\quad \text{(whitespace and } = \text{ removed)} \\ \text{char} &\to 6\text{ bits},\; 8\text{ bits} \to 1\text{ byte} \end{aligned} \right. \end{gathered}$$
具体例で確認
Base64文字列 SGk= を見てみましょう。各文字は \(S=18\)、\(G=6\)、\(k=36\) に対応し、「=」はパディングです。2進数で表すと \(010010\ 000110\ 100100 \to 24\) ビットになりますが、末尾のパディングがあるため有効なのは2バイトのみです。すなわち \(01001000\ (72 = \text{'H'})\) と \(01101001\ (105 = \text{'i'})\)。結果は Hi となります。
Base64アルファベット参照
標準Base64(RFC 4648)は、すべての6ビット値(0~63)を64個の印字可能なASCII文字の1つにマップします。デコーダーは各文字を読み込み、このテーブルで対応する6ビットのインデックスを検索し、ビットを連結して8ビットバイトに再グループ化します。下の表は、完全なアルファベットと各文字に割り当てられたインデックスを一覧にしています。
| インデックス | 文字 | インデックス | 文字 | インデックス | 文字 | インデックス | 文字 |
|---|---|---|---|---|---|---|---|
| 0 | A | 16 | Q | 32 | g | 48 | w |
| 1 | B | 17 | R | 33 | h | 49 | x |
| 2 | C | 18 | S | 34 | i | 50 | y |
| 3 | D | 19 | T | 35 | j | 51 | z |
| 4 | E | 20 | U | 36 | k | 52 | 0 |
| 5 | F | 21 | V | 37 | l | 53 | 1 |
| 6 | G | 22 | W | 38 | m | 54 | 2 |
| 7 | H | 23 | X | 39 | n | 55 | 3 |
| 8 | I | 24 | Y | 40 | o | 56 | 4 |
| 9 | J | 25 | Z | 41 | p | 57 | 5 |
| 10 | K | 26 | a | 42 | q | 58 | 6 |
| 11 | L | 27 | b | 43 | r | 59 | 7 |
| 12 | M | 28 | c | 44 | s | 60 | 8 |
| 13 | N | 29 | d | 45 | t | 61 | 9 |
| 14 | O | 30 | e | 46 | u | 62 | + |
| 15 | P | 31 | f | 47 | v | 63 | / |
65番目の記号である=(等号)はデータ文字ではありません。エンコードされた文字列の末尾で使用されるパディングマーカーで、合計長が常に4文字の倍数になるようにします。1つの=は最終の4文字グループが2バイトをエンコードすることを意味し、2つの==は1バイトをエンコードすることを意味します。デコーダーはパディングおよびそれが暗示する余分なゼロビットを破棄します。
デコード例の詳細
各Base64文字は6ビットを提供します。4文字(24ビット)は正確に3バイトにデコードされ、部分的なグループではパディングを使用してデコーダーが保持するバイト数を認識させます。バイト数は\(\text{バイト数} = \left\lfloor \frac{6 \times n}{8} \right\rfloor\)に従い、ここで\(n\)は実際の(パディングではない)文字の数です。
例1~パディングなし:「TWFu」→「Man」
- インデックス:T=19、W=22、F=5、u=46。
- 6ビットグループ:
010011 010110 000101 101110。 - バイトに再グループ化:
01001101 01100001 01101110= 77、97、110。 - ASCII 77、97、110 = M、a、n。\(n=4\)の場合:\(\lfloor 24/8 \rfloor = 3\)バイト~Man。
例2~1文字の「=」パディング:「SGVsbG8=」→「Hello」
- パディングを削除:7文字のパディングなし文字S、G、V、s、b、G、8。
- インデックス:S=18、G=6、V=21、s=44、b=27、G=6、8=60。
- ビット:
010010 000110 010101 101100 011011 000110 111100(パディンググループからの末尾の2ビットはゼロフィラーであり、破棄されます)。 - バイト:
01001000 01100101 01101100 01101100 01101111= 72、101、108、108、111 = H、e、l、l、o。 - \(n=7\)の場合:\(\lfloor 42/8 \rfloor = 5\)バイト~Hello。
例3~2文字の「==」パディング:「aGk=」...および「TQ==」→「M」
- パディングを削除:2文字のパディングなし文字T、Q。
- インデックス:T=19、Q=16。
- ビット:
010011 010000;最初の8ビットのみを保持し、残りの4ビットはゼロフィラーです。 - バイト:
01001101= 77 = M。 - \(n=2\)の場合:\(\lfloor 12/8 \rfloor = 1\)バイト~M。
逆方向に進んでテキストからこれらの文字列を生成するには、Base64エンコーダーを使用してください。
主要な用語
- Base64アルファベット
- バイナリデータをテキストとして表すために使用される64個の印字可能文字(A~Z、a~z、0~9、+、/)の固定セット。各文字は0~63の6ビット値を表します。
- パディング(「=」)
- エンコードされた文字列の末尾に追加される等号で、その長さが4文字の倍数になるようにします。データは含まず、1つの「=」は2バイトの最終グループをマークし、「==」は1バイトの最終グループをマークします。
- セクステット(6ビット)
- 6ビットのグループ~単一のBase64文字がエンコードする単位。4つのセクステット(24ビット)は3つのオクテットと正確に一致します。
- オクテット/バイト(8ビット)
- 8ビット単位で、デコードされたデータの1バイトの標準サイズです。Base64デコーディングはセクステットをオクテットに再グループ化し、バイナリからテキストへのコンバーターもビット単位で説明できます。
- 空白文字のストリップ
- デコード前にスペース、タブ、改行を削除します。多くのシステムは長いBase64に改行を挿入し(例:PEMサーティフィケート、メールMIME)、堅牢なデコーダーはこれを削除します。
- URL安全Base64
- +を-に、/を_に置き換える変種(RFC 4648 §5)で、文字列がURLとファイル名で安全になります。パディングはしばしば省略されます。標準デコーダーを使用する前にそのような文字を+と/に変換してください。周囲のURL自体についてはURLエンコード/デコード計算機を参照してください。
よくある質問(FAQ)
入力したデータはどこかに送信されますか? 結果を表示するためにデコード処理はサーバー側で実行されますが、入力内容が保存されることはありません。とはいえ、機密情報の貼り付けは避けてください。
バイト数が4で割り切れないのはなぜですか? ここで表示されるバイト数は、入力文字数ではなくデコード後の出力バイト数を指します。入力4文字ごとに最大3バイトの出力が生成されます。
パディングとは何を意味しますか? 「=」が1つの場合、最後のグループから2バイトが生成されたことを意味します。「=」が2つの場合は1バイトです。パディングがない場合は、元データの長さがすでに3の倍数だったことを示します。