
Base64エンコードとは?
Base64は、バイナリデータを印刷可能な64種類のASCII文字だけで表現する「バイナリ→テキスト変換」方式です。使用する文字は A-Z、a-z、0-9 に加えて + と / の64文字。HTML/CSSに画像を直接埋め込むデータURI、メールにバイナリ添付を送るMIME、JSON Web Token(JWT)など、テキストしか通せない経路を介してバイナリデータを安全にやり取りしたい場面で広く使われています。このツールでは、入力したテキストをまずUTF-8のバイト列に変換し、そのうえでBase64にエンコードします。
このエンコーダーの使い方
入力欄にテキストを入力するか貼り付けて、実行するだけです。ツールがテキストをUTF-8バイト列に変換し、標準のBase64アルゴリズムを適用して、エンコード結果の文字列を返します。あわせて入力バイト数と出力文字数も表示します。
仕組み(変換のルール)
エンコーダーは入力バイトを3バイトずつ読み込みます。3バイト=24ビットを、6ビットずつ4つのかたまりに均等に分割。それぞれの6ビット値(0〜63)をアルファベット表のインデックスとして、1文字の出力に対応させます。入力の長さが3の倍数でない場合は、最後のグループにパディングを加えます。余りが1バイトのときは2文字+==、余りが2バイトのときは3文字+=1個となります。そのため出力の長さは常に
になります。
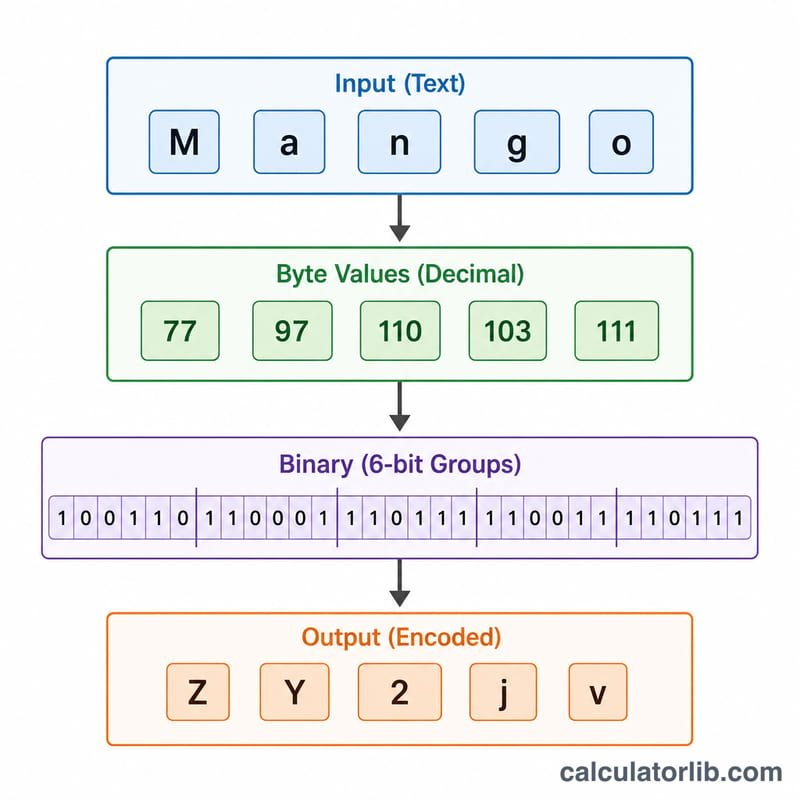
具体例で見てみる
テキスト Man をエンコードしてみましょう。ASCIIバイトは77, 97, 110 → 2進数で 01001101 01100001 01101110。これを6ビットずつに区切ると、\(010011 = 19 \to T\)、\(010110 = 22 \to W\)、\(000101 = 5 \to F\)、\(101110 = 46 \to u\)。結果は TWFu です。入力3バイトに対して出力4文字、パディングなしとなります。
よくある質問(FAQ)
出力の末尾に「=」が付くのはなぜ? 入力が3バイトの倍数でないとき、最後のグループを埋めるためのパディングです。これにより出力の長さが常に4の倍数に保たれます。
Base64でデータは暗号化される? いいえ。Base64は「エンコード」であって「暗号化」ではありません。誰でも簡単にデコードできます。バイナリをテキストとして安全に運べるようにするだけです。
出力が入力より大きくなるのはなぜ? 3バイトが4文字になるため、Base64ではデータ量が約33%増加します。