
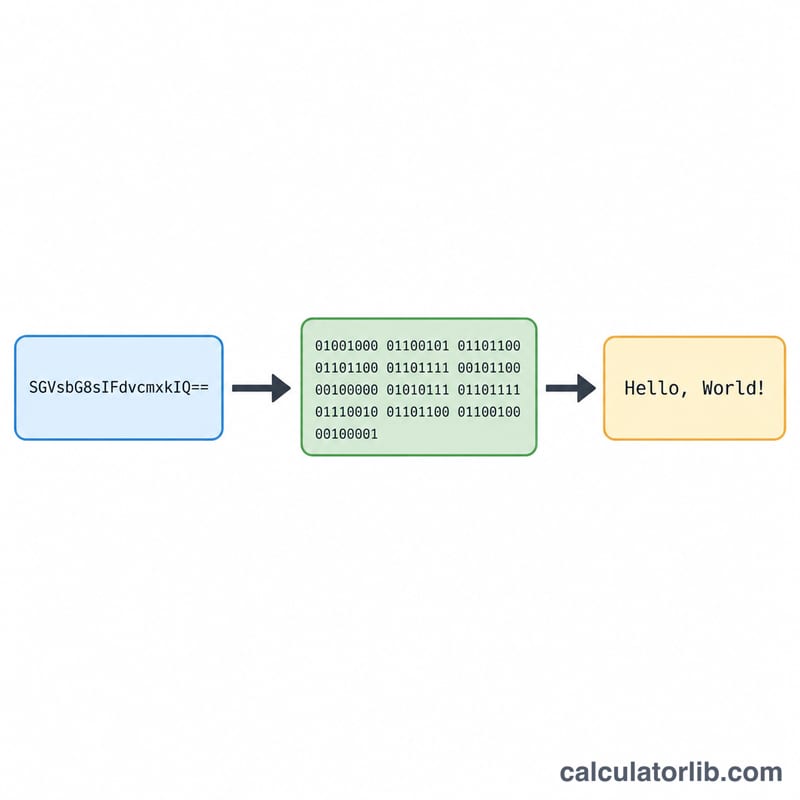
什么是 Base64 解码器?
Base64 是一种编码方式,它用 64 个可打印的 ASCII 字符(A–Z、a–z、0–9、+ 和 /)来表示二进制数据。它被广泛用于在 HTML 中内嵌图片、在 JSON 或 URL 中传输数据,以及对电子邮件附件进行编码。本解码器则负责执行相反的操作——把一段 Base64 字符串还原回它原本所代表的纯文本。
使用方法
把你的 Base64 字符串粘贴或输入到输入框中并提交。工具会先去除所有空白字符,再对内容进行解码,最后显示还原后的文本,同时给出解码得到的字节数、去除空白后的输入字符数,以及末尾包含了多少个填充符('=')。如果输入中含有 Base64 字符集之外的字符,页面会提示"无效"。
原理与公式
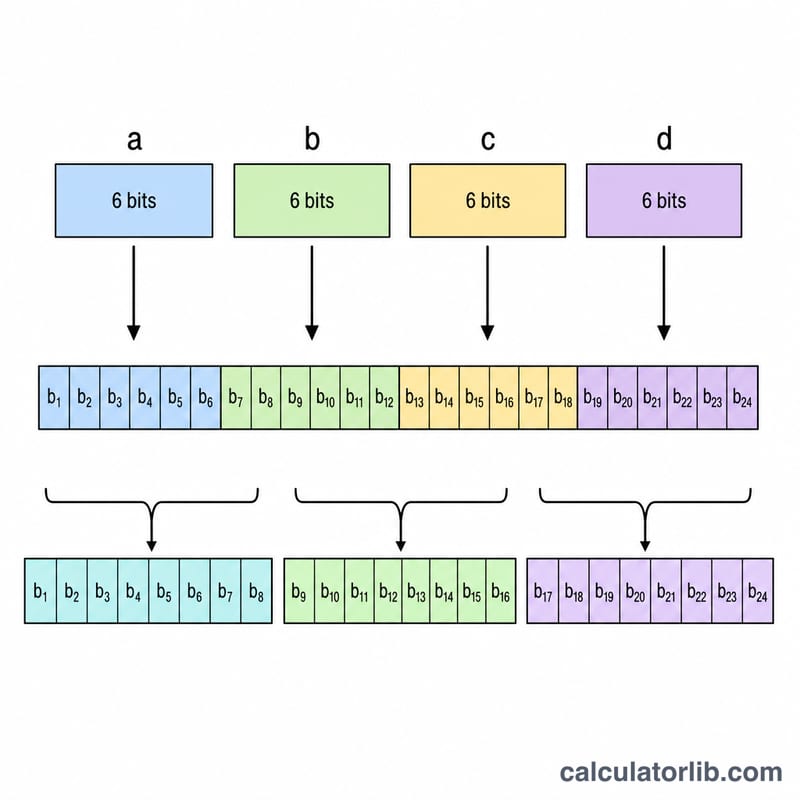
每个 Base64 字符承载 6 个比特的数据。因此,4 个 Base64 字符共携带 \(4 \times 6 = 24\) 个比特,正好可以重新组合成 3 个 8 比特的字节。当原始数据的长度不是 3 的整数倍时,就会在末尾补上 1 个或 2 个填充符 '=',从而保证编码后的字符串长度始终是 4 的倍数。在解码过程中,这些填充符会被去除,多余的比特也会被丢弃。
$$\text{Bytes} = \left\lfloor \frac{6 \times \text{Base64 chars (no padding)}}{8} \right\rfloor$$
$$\begin{gathered} \text{Bytes} = \left\lfloor \frac{6N}{8} \right\rfloor \\[1.5em] \text{where}\quad \left\{ \begin{aligned} N &= \text{valid chars of } \text{Base64 Input} \\ &\quad \text{(whitespace and } = \text{ removed)} \\ \text{char} &\to 6\text{ bits},\; 8\text{ bits} \to 1\text{ byte} \end{aligned} \right. \end{gathered}$$
实例演示
以 Base64 字符串 SGk= 为例。各字符对应的值为:S=18、G=6、k=36,而 '=' 是填充符。换算成二进制为:\(010010\ 000110\ 100100\) → 共 24 个比特,但末尾的填充符意味着只有 2 个字节是有效的:\(01001000\)(72 = 'H')和 \(01101001\)(105 = 'i')。最终结果为 Hi。
Base64 字母表参考
标准 Base64(RFC 4648)将每个 6 位值(0–63)映射到 64 个可打印 ASCII 字符之一。解码器读取每个字符,在此表中查找其 6 位索引,连接这些位,然后将它们重新分组为 8 位字节。下表列出了完整字母表以及分配给每个字符的索引。
| 索引 | 字符 | 索引 | 字符 | 索引 | 字符 | 索引 | 字符 |
|---|---|---|---|---|---|---|---|
| 0 | A | 16 | Q | 32 | g | 48 | w |
| 1 | B | 17 | R | 33 | h | 49 | x |
| 2 | C | 18 | S | 34 | i | 50 | y |
| 3 | D | 19 | T | 35 | j | 51 | z |
| 4 | E | 20 | U | 36 | k | 52 | 0 |
| 5 | F | 21 | V | 37 | l | 53 | 1 |
| 6 | G | 22 | W | 38 | m | 54 | 2 |
| 7 | H | 23 | X | 39 | n | 55 | 3 |
| 8 | I | 24 | Y | 40 | o | 56 | 4 |
| 9 | J | 25 | Z | 41 | p | 57 | 5 |
| 10 | K | 26 | a | 42 | q | 58 | 6 |
| 11 | L | 27 | b | 43 | r | 59 | 7 |
| 12 | M | 28 | c | 44 | s | 60 | 8 |
| 13 | N | 29 | d | 45 | t | 61 | 9 |
| 14 | O | 30 | e | 46 | u | 62 | + |
| 15 | P | 31 | f | 47 | v | 63 | / |
第 65 个符号 =(等号)不是数据字符。它是在编码字符串末尾使用的填充标记,以确保总长度总是 4 个字符的倍数。一个 = 表示最后一个 4 字符组编码 2 个字节;两个 == 表示它编码 1 个字节。解码器会丢弃填充及其隐含的多余零位。
更多解码示例
每个 Base64 字符贡献 6 位。四个字符(24 位)准确解码为 3 个字节;部分组使用填充,以便解码器知道要保留多少个字节。字节计数遵循 \(\text{字节数} = \left\lfloor \frac{6 \times n}{8} \right\rfloor\),其中 \(n\) 是实数(非填充)字符的数量。
示例 1 — 无填充:"TWFu" → "Man"
- 索引:T=19、W=22、F=5、u=46。
- 6 位组:
010011 010110 000101 101110。 - 重新分组为字节:
01001101 01100001 01101110= 77、97、110。 - ASCII 77、97、110 = M、a、n。其中 \(n=4\):\(\lfloor 24/8 \rfloor = 3\) 个字节 — Man。
示例 2 — 一个 '=' 填充:"SGVsbG8=" → "Hello"
- 丢弃填充:7 个实字符 S、G、V、s、b、G、8。
- 索引:S=18、G=6、V=21、s=44、b=27、G=6、8=60。
- 位:
010010 000110 010101 101100 011011 000110 111100(填充组的尾随 2 位是零填充符,被丢弃)。 - 字节:
01001000 01100101 01101100 01101100 01101111= 72、101、108、108、111 = H、e、l、l、o。 - 其中 \(n=7\):\(\lfloor 42/8 \rfloor = 5\) 个字节 — Hello。
示例 3 — 两个 '==' 填充:"aGk="... 和 "TQ==" → "M"
- 丢弃填充:2 个实字符 T、Q。
- 索引:T=19、Q=16。
- 位:
010011 010000;仅保留前 8 位,其余 4 位是零填充符。 - 字节:
01001101= 77 = M。 - 其中 \(n=2\):\(\lfloor 12/8 \rfloor = 1\) 个字节 — M。
要反向操作并从文本生成这些字符串,请使用 Base64 编码器。
关键术语
- Base64 字母表
- 用于将二进制数据表示为文本的固定的 64 个可打印字符集合(A–Z、a–z、0–9、+ 和 /)。每个字符代表一个 0 到 63 的 6 位值。
- 填充 ('=')
- 在编码字符串末尾追加的等号,使其长度为 4 字符的倍数。它不携带数据;一个 '=' 标记 2 字节的最终组,'==' 标记 1 字节的最终组。
- 六位组(6 位)
- 一组 6 位 — 单个 Base64 字符编码的单位。四个六位组(24 位)正好与三个八位组对齐。
- 八位组 / 字节(8 位)
- 一个 8 位单位,是解码数据的一个字节的标准大小。Base64 解码将六位组重新分组回八位组,二进制转文本转换器 也可以逐位说明。
- 空白剥除
- 在解码前删除空格、制表符和换行符。许多系统在长 Base64 中插入换行符(例如 PEM 证书、电子邮件 MIME);强大的解码器会忽略此空白而不是将其视为数据。
- URL 安全 Base64
- 一种变体(RFC 4648 §5),用 - 替换 + 和用 _ 替换 /,以便字符串在 URL 和文件名中是安全的。填充通常也会被省略。在使用标准解码器之前,将这些字符转换回 + 和 /;关于周围 URL 本身,请参见 URL 编码 / 解码计算器。
常见问题
我的数据会被发送到别处吗? 解码逻辑在服务器端运行以生成结果,但不会存储任何输入内容。请勿粘贴敏感信息或密钥。
为什么字节数不能被 4 整除? 这里的字节数指的是解码后的输出字节数,而非输入字符数。每 4 个输入字符最多可还原出 3 个输出字节。
填充符代表什么? 1 个 '=' 表示最后一组解码出了 2 个字节;2 个 '=' 表示只解码出了 1 个字节;没有填充符则说明原始数据长度本来就是 3 的整数倍。