
这个计算器能做什么
本工具用于计算两项软件工程中常用的质量度量指标:测试密度(测试用例数量相对于代码规模的比值)和缺陷密度(发现的缺陷数量相对于代码规模的比值)。两项指标都会同时给出按 LOC(代码行数,Lines Of Code)和按 KLOC(千行代码)计算的结果,因为 KLOC 是行业通用的报告单位。这是一项通用度量指标,不涉及任何地区或国家的特殊规定。
如何使用
输入已执行的测试用例数量、发现的缺陷数量以及源代码规模。再选择填写的代码规模是原始行数(LOC)还是以千行为单位(KLOC)——计算器会先把数值统一换算成原始 LOC,再进行计算。所有密度指标都会自动得出。
公式解析
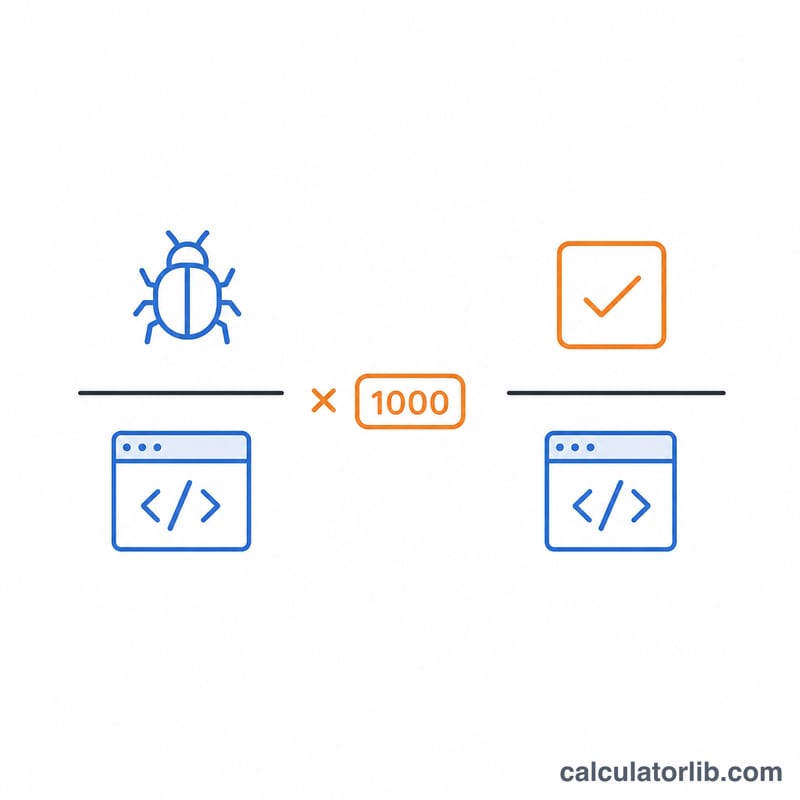
首先对代码规模做归一化处理:\( \text{locLines} = \text{loc} \times \text{factor} \),其中 LOC 对应的系数为 \(1\),KLOC 对应的系数为 \(1000\)。然后,
$$\text{Test Density} = \frac{\text{Test Count}}{L} \times 1000, \qquad \text{Bug Density} = \frac{\text{Bug Count}}{L} \times 1000$$每 LOC 测试密度 = 测试用例数 / locLines,每 LOC 缺陷密度 = 缺陷数 / locLines。每 KLOC 的结果只需把每 LOC 的值乘以 \(1000\) 即可。测试用例数和缺陷数都是整数计数,不做任何换算。
实例演示
假设你执行了 500 个测试,发现了 25 个缺陷,代码规模为 10 KLOC。归一化后的规模 \( = 10 \times 1000 = 10{,}000 \text{ LOC} \)。测试密度 \( = 500 / 10{,}000 = 0.05 \) 个测试/LOC,即 50 个测试/KLOC。缺陷密度 \( = 25 / 10{,}000 = 0.0025 \) 个缺陷/LOC,即 2.5 个缺陷/KLOC。
常见问题
为什么要同时给出每 LOC 和每 KLOC 两种结果?每 LOC 的数值往往很小、不易阅读,因此行业惯例是按 KLOC 报告。两者所表达的信息完全一致——一个只是另一个乘以 \(1000\) 的结果。
为什么结果是空白或显示错误?如果 LOC 为零,密度在数学上就无法定义(除数为零),所以计算器会给出错误提示,而不是显示无穷大的数值。
这些数字能在不同项目之间比较吗?只有在 LOC 的统计口径一致时才能比较。要事先确定是否把注释行和空行计入代码行数,因为这一选择会显著影响密度数值。