Qu'est-ce que la fonction Softplus ?
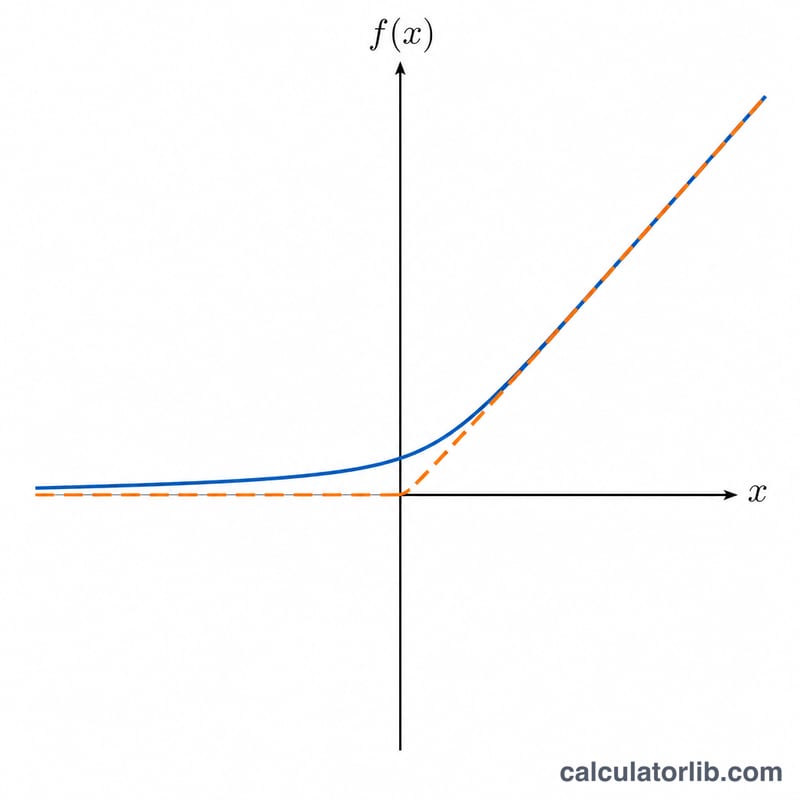
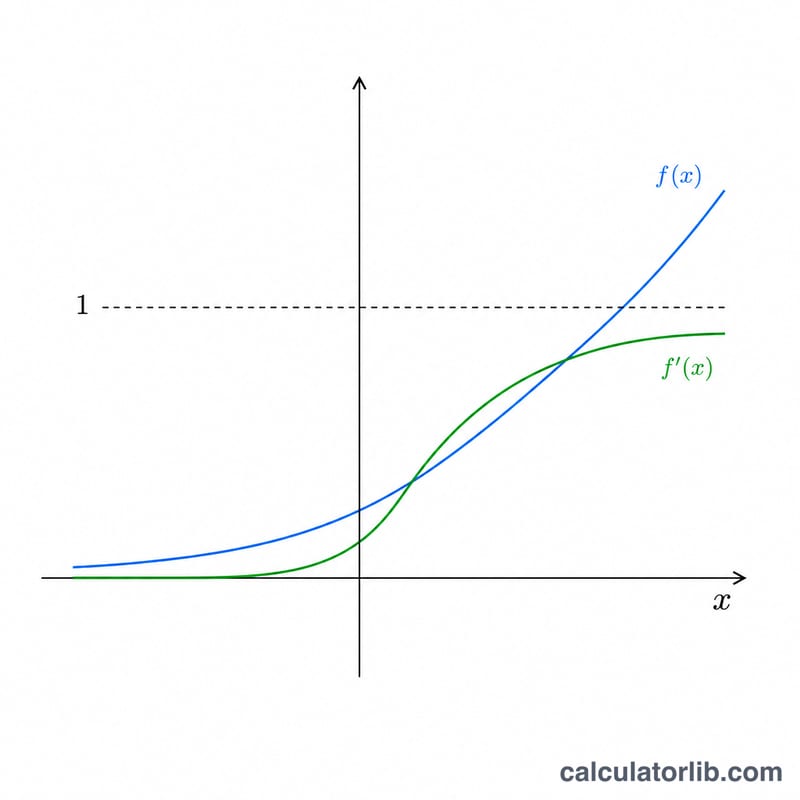
La fonction Softplus, \(f(x) = \ln(1 + e^{x})\), est une approximation lisse et dérivable de l'activation ReLU (unité de rectification linéaire) employée dans les réseaux de neurones. Contrairement à ReLU, qui présente un angle vif à l'origine, Softplus est lisse en tout point et toujours strictement positive. Ce calculateur construit une table de \(x\), \(f(x)\) et sa dérivée première sur la plage que vous définissez, puis trace les deux courbes pour révéler sa forme caractéristique en S évoluant vers une rampe.
Comment l'utiliser
Saisissez trois valeurs : la valeur initiale de x (la première abscisse), l'incrément (l'espacement entre les points) et le nombre de répétitions (le nombre de lignes à générer). Par exemple, une valeur initiale de -5, un incrément de 0,1 et 101 répétitions produisent un \(x\) allant de -5,0 à +5,0. Le résultat se présente sous la forme d'une table déroulante accompagnée d'un graphique de la fonction Softplus et de sa dérivée.
La formule expliquée
La fonction Softplus s'écrit $$f(x) = \ln\!\left(1 + e^{x}\right).$$ Sa dérivée vaut $$f'(x) = \frac{e^{x}}{1 + e^{x}} = \frac{1}{1 + e^{-x}},$$ soit précisément la sigmoïde logistique. Lorsque \(x\) devient grand et positif, \(f(x)\) tend vers \(x\) et \(f'(x)\) tend vers 1 ; lorsque \(x\) devient grand et négatif, \(f(x)\) tend vers 0 et \(f'(x)\) tend vers 0. Pour éviter tout dépassement de capacité aux grandes valeurs de \(x\), l'outil emploie la forme numériquement stable $$f(x) = \max(x, 0) + \ln\!\left(1 + e^{-|x|}\right).$$
Exemple détaillé
En \(x = 0\) : \(f(0) = \ln(2) = 0{,}693147\) et \(f'(0) = 0{,}5\). En \(x = 1\) : \(f(1) = \ln(1 + 2{,}718282) = 1{,}313262\) et \(f'(1) = \dfrac{1}{1 + e^{-1}} = 0{,}731059\). En \(x = -1\) : \(f(-1) = 0{,}313262\) et \(f'(-1) = 0{,}268941\). Remarquez l'identité \(f(x) - f(-x) = x\), par exemple $$1{,}313262 - 0{,}313262 = 1.$$
Foire aux questions
Pourquoi utiliser Softplus plutôt que ReLU ? Softplus est lisse et possède un gradient non nul partout, ce qui peut faciliter l'optimisation par descente de gradient, même si ReLU reste moins coûteuse à calculer.
La sortie est-elle toujours positive ? Oui. \(\ln(1 + e^{x}) > 0\) pour tout \(x\) fini, car \(1 + e^{x} > 1\).
Que représente la dérivée ? Il s'agit de la pente de la courbe Softplus ; elle coïncide avec la sigmoïde logistique et croît de façon monotone de 0 à 1, valant 0,5 en \(x = 0\).