
¿Qué es la calculadora de tokens a palabras y coste?
Los grandes modelos de lenguaje (LLM) como GPT, Claude o Gemini procesan el texto en tokens y no en palabras. Un token es un fragmento de texto —a menudo una parte de palabra de unos cuatro caracteres—. Esta calculadora estima cuántas palabras representa una cantidad determinada de tokens y cuánto cuestan esos tokens según el precio por cada 1.000 que fija cada modelo.
Cómo usarla
Introduce el número de tokens, la proporción de palabras por token (0,75 es un buen valor por defecto para texto en inglés) y el precio que cobra tu proveedor por cada 1.000 tokens. La herramienta te devuelve al instante el número estimado de palabras y el coste en dólares.
La fórmula explicada
La estimación de palabras utiliza \(\text{palabras} \approx \text{tokens} \times 0{,}75\), basándose en la regla habitual de que 1.000 tokens equivalen a unas 750 palabras en inglés. El coste se calcula como $$\text{coste} = \frac{\text{tokens}}{1000} \times \text{precio por 1k}$$ ya que los proveedores facturan por cada mil tokens. Ajusta la proporción para otros idiomas o para código, que suelen consumir más tokens por palabra.
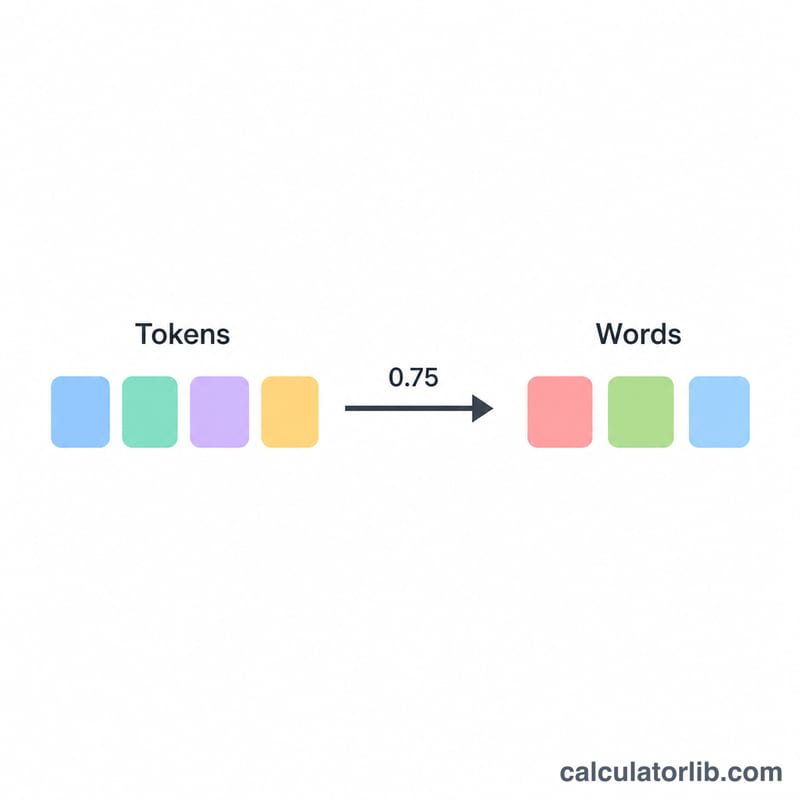
Ejemplo práctico
Imagina que tienes 1.000 tokens con una proporción de 0,75 y un precio de 0,50 $ por cada 1.000 tokens. Palabras = \(1000 \times 0{,}75 = \mathbf{750}\) palabras. Coste = \(\frac{1000}{1000} \times 0{,}50\,\$ = \mathbf{0{,}50\,\$}\).
Preguntas frecuentes
¿Qué precisión tiene la estimación de palabras? Es una aproximación. La tokenización real varía según el modelo y el contenido; 0,75 palabras por token es una buena media para el inglés.
¿Cuestan lo mismo los tokens de entrada y de salida? No: muchos proveedores aplican tarifas distintas. Usa la calculadora dos veces, una con cada tarifa, y suma los resultados.
¿Por qué difieren el código o los textos en otros idiomas? Suelen agrupar más tokens por palabra, así que conviene bajar la proporción (por ejemplo, a 0,5) para obtener una estimación más fiel. El español, en particular, tiende a usar más tokens por palabra que el inglés.