¿Qué es la calculadora de tokens a palabras?
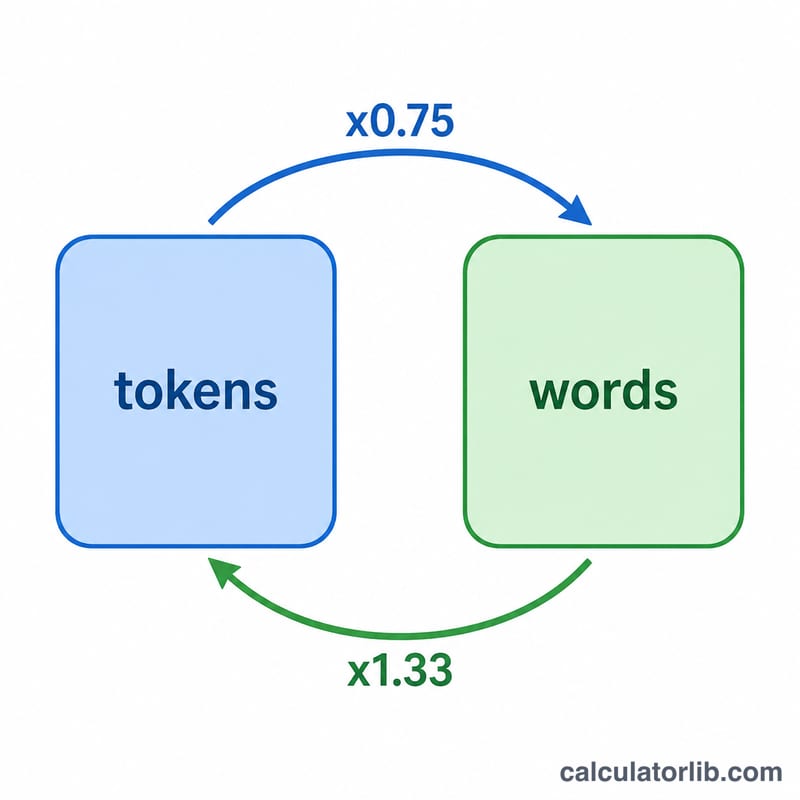
Los grandes modelos de lenguaje (LLM) como GPT, Claude o Gemini no leen el texto palabra por palabra: lo procesan en tokens. Un token es un fragmento de texto que puede ser una palabra completa, una parte de una palabra o incluso un signo de puntuación. En la prosa habitual en inglés, un token equivale aproximadamente a 0,75 palabras (es decir, alrededor de 1,33 tokens por palabra). Esta calculadora transforma un número de tokens en una estimación de palabras, o un número de palabras en los tokens que probablemente consumirá.
Cómo usarla
Elige la dirección —De tokens a palabras o De palabras a tokens—, introduce la cantidad y, si lo deseas, ajusta la proporción de palabras por token (por defecto 0,75). La herramienta muestra al instante la cifra convertida junto con la proporción aplicada. Reduce la proporción para código o texto en otros idiomas (que suelen consumir más tokens) y auméntala para un inglés sencillo y repetitivo.
La fórmula explicada
La conversión es una simple proporción. Para estimar palabras a partir de tokens:
$$\text{palabras} = \text{tokens} \times \text{proporción}$$Para estimar tokens a partir de palabras:
$$\text{tokens} = \frac{\text{palabras}}{\text{proporción}}$$Con la proporción por defecto de 0,75, 1.000 tokens ≈ 750 palabras y 1.000 palabras ≈ 1.333 tokens. Son estimaciones: la tokenización real depende del modelo, el idioma y el contenido.
Ejemplo práctico
Imagina que una llamada a la API indica que usó 1.000 tokens. Con la proporción por defecto:
$$1000 \times 0{,}75 = 750 \text{ palabras}$$Y si has escrito un ensayo de 1.500 palabras y quieres saber su coste en tokens:
$$1500 \div 0{,}75 = 2000 \text{ tokens}$$algo muy útil para no superar la ventana de contexto de un modelo o para controlar el gasto en la API.
Preguntas frecuentes
¿0,75 palabras por token es siempre exacto? No: es una regla práctica muy citada para el inglés. El código, los números y otros idiomas suelen usar más tokens por palabra, así que conviene aplicar una proporción más baja en esos casos.
¿Por qué importan los tokens? Los precios y los límites de contexto de los LLM se miden en tokens, no en palabras, por lo que convertir te ayuda a estimar el coste y el ajuste al contexto.
¿Cómo consigo recuentos exactos? Usa el tokenizador oficial del modelo (por ejemplo, tiktoken en el caso de OpenAI). Esta calculadora ofrece una aproximación rápida, no un recuento exacto.