What is the Tokens to Words Calculator?
Large language models (LLMs) like GPT, Claude, and Gemini don't read text word-by-word — they process it in tokens. A token is a chunk of text that can be a whole word, part of a word, or even punctuation. For typical English prose, one token corresponds to roughly 0.75 words (equivalently, about 1.33 tokens per word). This calculator converts a token count into an estimated word count, or a word count into the tokens it will likely consume.
How to Use It
Pick a direction — Tokens to Words or Words to Tokens — enter your amount, and optionally adjust the words-per-token ratio (default 0.75). The tool instantly shows the converted figure plus the ratio used. Lower the ratio for code or non-English text (which tends to use more tokens), and raise it for simple, repetitive English.
The Formula Explained
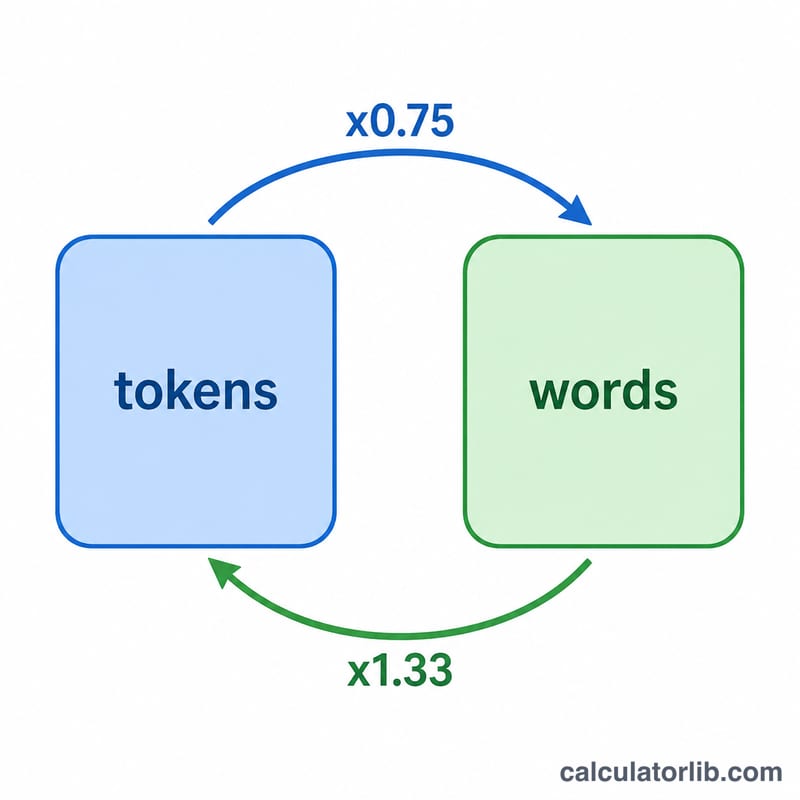
The conversion is a simple proportion. To estimate words from tokens: $$\text{Words} = \text{Tokens} \times \text{Words per Token}$$ To estimate tokens from words: $$\text{Tokens} = \frac{\text{Words}}{\text{Words per Token}}$$ With the default ratio of 0.75, \(1{,}000\) tokens \(\approx 750\) words, and \(1{,}000\) words \(\approx 1{,}333\) tokens. These are estimates: real tokenization depends on the model, language, and content.
Worked Example
Suppose an API call reports it used 1,000 tokens. Using the default ratio: $$1000 \times 0.75 = 750 \text{ words}$$ If instead you wrote a 1,500-word essay and want to know its token cost: $$1500 \div 0.75 = 2{,}000 \text{ tokens}$$ — helpful for staying within a model's context window or budgeting API spend.
FAQ
Is 0.75 words per token always accurate? No — it's a widely cited rule of thumb for English. Code, numbers, and other languages often use more tokens per word, so use a lower ratio for those.
Why do tokens matter? LLM pricing and context limits are measured in tokens, not words, so converting helps you estimate cost and fit.
How can I get exact counts? Use the model's official tokenizer (e.g., tiktoken for OpenAI). This calculator gives a fast approximation, not an exact count.