What is the LLM API Cost Calculator?
This calculator estimates how much you will pay to call a large language model (LLM) API such as GPT, Claude, or Gemini. Providers bill per token, and usually charge a different rate for the tokens you send (input/prompt) than for the tokens the model generates (output/completion). Prices are typically quoted per 1,000 or per 1,000,000 tokens — this tool uses per 1,000 (1K) tokens.
How to use it
Enter the number of input tokens and output tokens for a single request, then the price per 1,000 tokens for each. Set how many identical requests you expect to run. The calculator returns the cost of one request, the split between input and output cost, and the projected total spend.
Tip: if your provider lists prices per million tokens, divide that figure by 1,000 to get the per-1K price (e.g. $0.50 per 1M = $0.0005 per 1K).
The formula explained
The core equation is $$\text{cost} = \frac{\text{input\_tokens}}{1000} \times \text{in\_price} + \frac{\text{output\_tokens}}{1000} \times \text{out\_price}$$ Dividing tokens by 1,000 converts a raw token count into "thousands of tokens," which is then multiplied by the per-1K rate. The two products are summed to give the cost of a single request, and that is multiplied by the request count for total spend.
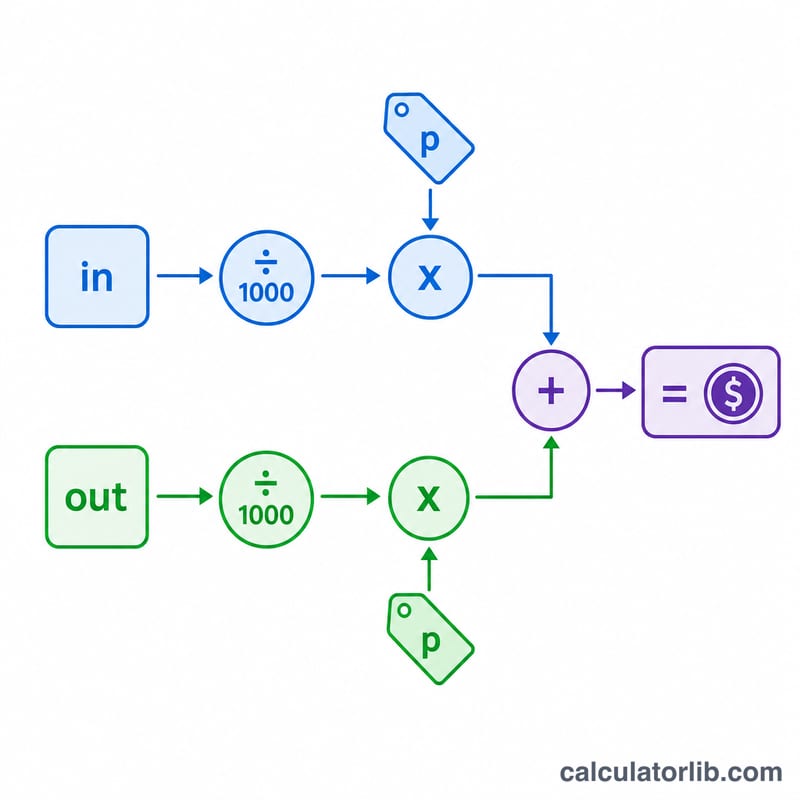
Worked example
Suppose a request uses 1,000 input tokens at $0.0005 per 1K and 500 output tokens at $0.0015 per 1K. Input cost = \(\frac{1000}{1000} \times 0.0005 = \$0.0005\). Output cost = \(\frac{500}{1000} \times 0.0015 = \$0.00075\). Cost per request = \(\$0.00125\). Over 1,000 requests the total is \(\$1.25\).
FAQ
What counts as a token? Roughly ¾ of a word in English, or about 4 characters. Punctuation and spaces also consume tokens.
Are input and output priced the same? Usually no — output tokens are commonly 2–4× more expensive than input tokens, so enter both rates separately.
Does this include caching or batch discounts? No. This is a straightforward list-price estimate; apply provider-specific discounts to your effective per-1K prices first.