什麼是 Token 字數換算器?
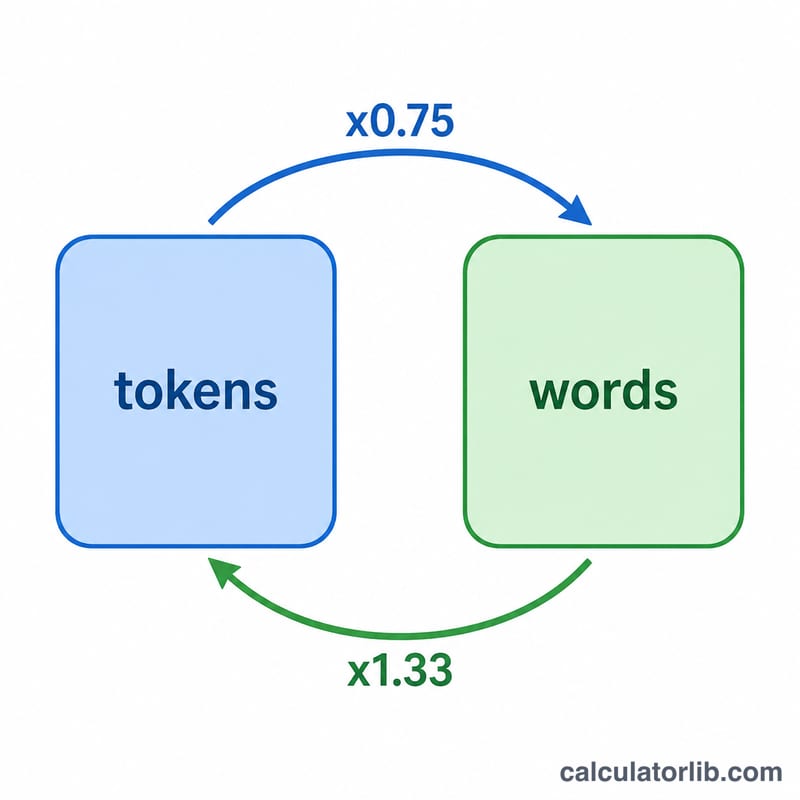
GPT、Claude、Gemini 等大型語言模型(LLM)並非逐字閱讀文字,而是以 Token(詞元)為單位處理。一個 Token 是一段文字片段,可能是一個完整單字、單字的一部分,甚至是標點符號。以一般英文文章來說,1 個 Token 大約對應 0.75 個英文單字(換算過來約為每個單字 1.33 個 Token)。這個換算器能把 Token 數換算成估計的字數,也能把字數換算成可能耗用的 Token 數。要提醒的是,這套比例是以英文為基準;中文的 Token 切分方式不同,實際比例會有所差異。
使用方式
先選擇換算方向──Token 換字數 或 字數換 Token──輸入數量,並可視需要調整 每個 Token 對應的字數比例(預設為 0.75)。工具會立即顯示換算結果以及採用的比例。處理程式碼或非英文內容時(這類文字通常會耗用更多 Token),可把比例調低;若是簡單、重複性高的英文,則可調高。
公式說明
換算其實是單純的比例運算。由 Token 估算字數:$$\text{字數} = \text{Token 數} \times \text{比例}$$由字數估算 Token:$$\text{Token 數} = \frac{\text{字數}}{\text{比例}}$$以預設比例 0.75 計算,1,000 個 Token ≈ 750 字,而 1,000 字 ≈ 1,333 個 Token。這些都是估計值──實際的 Token 切分會因模型、語言與內容而不同。
實際範例
假設某次 API 呼叫顯示用掉了 1,000 個 Token,套用預設比例:$$1000 \times 0.75 = 750 \text{ 字}$$反過來,如果你寫了一篇 1,500 字的英文文章,想知道它大約會耗用多少 Token:$$1500 \div 0.75 = 2{,}000 \text{ 個 Token}$$──這對於控制模型的脈絡視窗(context window)上限、或抓 API 費用預算都很有幫助。
常見問題
0.75 字/Token 的比例一定準嗎?不一定──這是針對英文廣為引用的經驗法則。程式碼、數字以及其他語言(包含中文)往往每個字會用掉更多 Token,因此這類內容建議改用較低的比例。
為什麼 Token 這麼重要?LLM 的計費與脈絡長度上限都是以 Token(而非字數)為單位計算,因此做好換算有助於估算成本與內容是否塞得下。
要怎麼取得精確的 Token 數?請使用模型官方的 Tokenizer(例如 OpenAI 的 tiktoken)。本換算器提供的是快速的近似值,並非精確計數。