什麼是 LLM 顯示記憶體需求計算機?
這個工具能幫你估算載入並執行大型語言模型(LLM)進行推論時,所需的 GPU 顯示記憶體(VRAM)有多少。記憶體用量主要取決於模型的參數量,以及儲存每個權重所用的數值精度。此外,還有一個安全(額外開銷)係數,用來涵蓋 KV 快取、啟用值(activations)與 CUDA 環境等,這些都會在純權重之外額外佔用記憶體。
使用方式
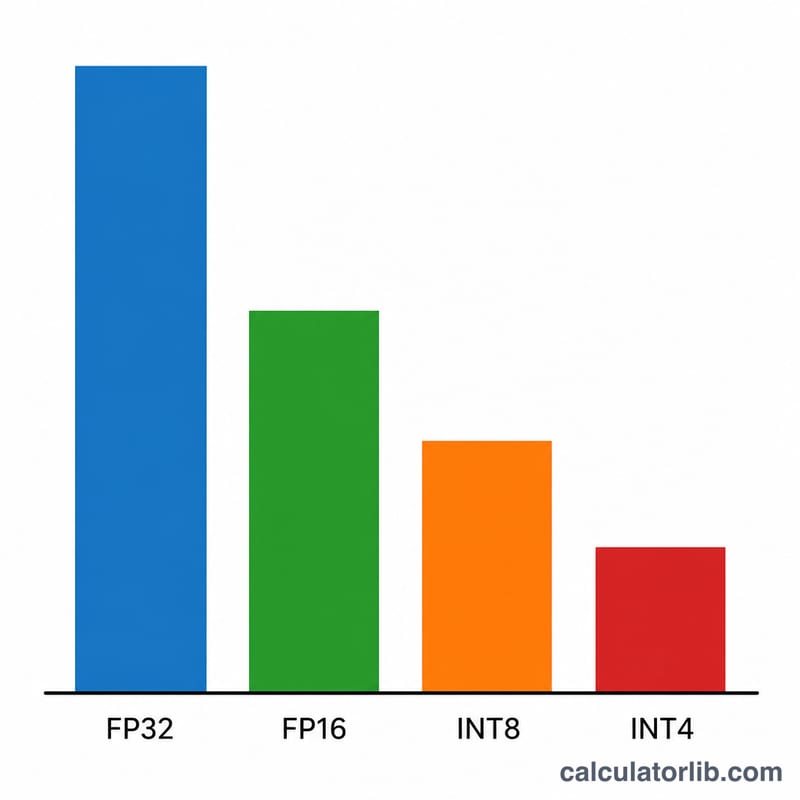
以「十億參數」為單位輸入模型大小(例如 7B 模型輸入 7、Llama-3 70B 輸入 70)。接著選擇精度:FP32 每個權重佔 4 個位元組、FP16/BF16 佔 2 個位元組、INT8 佔 1 個位元組,而 INT4 量化僅佔 0.5 個位元組。最後設定額外開銷係數——對於短上下文的推論,1.2(保留 20% 緩衝)是相當合理的預設值;若是長上下文或需要批次處理,則應調高此數值。
公式解析
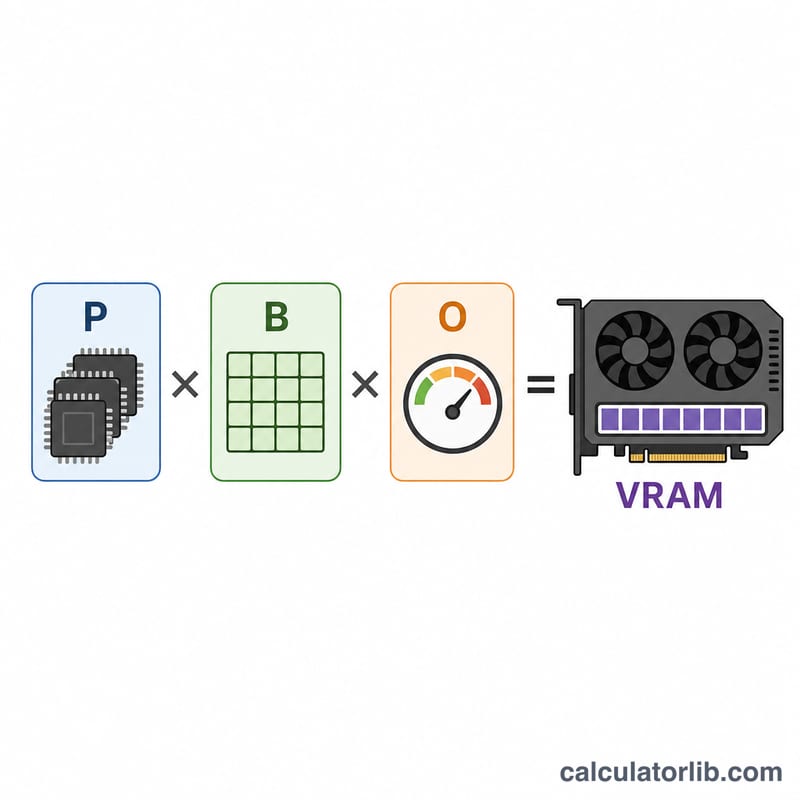
$$\text{VRAM (GB)} = \text{Params (B)} \times \text{Bytes/Param} \times \text{Overhead}$$由於 10 億位元組 ≈ 1 GB,將以「十億」為單位的參數量乘上每個參數的位元組數,便能直接得到 GB 數。再乘上額外開銷係數,就能涵蓋執行階段所需的記憶體。
實際範例
以 7B 模型、採 FP16 精度、額外開銷係數 1.2 為例:$$7 \times 2 \times 1.2 = 16.8 \text{ GB}$$可輕鬆容納於 24 GB 的顯示卡上。同一個模型若改用 INT4:$$7 \times 0.5 \times 1.2 = 4.2 \text{ GB}$$連 8 GB 的 GPU 都能輕鬆執行。
常見問題
為什麼實際用量會比純權重高?KV 快取會隨上下文長度與批次大小而增加,框架本身也會為啟用值與緩衝區保留記憶體——這正是額外開銷係數所要近似估算的部分。
這有包含訓練所需的記憶體嗎?沒有。訓練因為要儲存最佳化器狀態與梯度,大約需要 3~4 倍的記憶體;本估算僅針對推論(inference)。
我該用多少的額外開銷係數?短提示詞約用 1.2;長上下文或大量批次處理則建議使用 1.5~2.0 以上。