ما هي حاسبة متطلبات ذاكرة VRAM لنماذج اللغة الكبيرة؟
تساعدك هذه الأداة على تقدير حجم ذاكرة كرت الشاشة (VRAM) اللازمة لتحميل نموذج لغوي كبير (LLM) وتشغيله في مرحلة الاستدلال. يتحدد حجم الذاكرة المطلوب في المقام الأول بعدد معاملات النموذج وبدقة التمثيل الرقمي المستخدمة لتخزين كل وزن. أما عامل الهامش (الأمان الإضافي) فيأخذ في الحسبان ذاكرة الـ KV cache والتنشيطات وسياق CUDA، وهي عناصر تستهلك ذاكرة إضافية تتجاوز حجم الأوزان الخام وحده.
كيفية الاستخدام
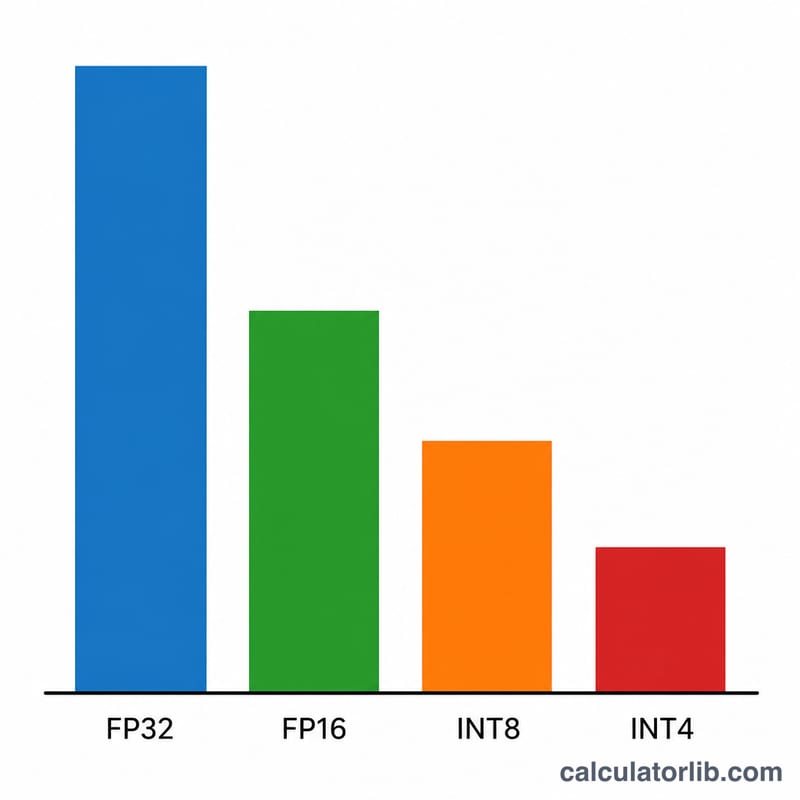
أدخل حجم النموذج بالمليارات من المعاملات (مثلاً 7 لنموذج بحجم 7B، أو 70 لنموذج Llama-3 70B). ثم اختر دقة التخزين: تستهلك دقة FP32 أربعة بايت لكل وزن، بينما تستهلك FP16/BF16 بايتين، وتستهلك INT8 بايتًا واحدًا، أما تكميم INT4 فيستهلك نصف بايت فقط. وأخيرًا حدّد عامل الهامش الإضافي — تُعدّ القيمة 1.2 (أي هامش إضافي بنسبة 20%) خيارًا افتراضيًا معقولًا للاستدلال ضمن سياق قصير، ويُنصح برفعها مع السياقات الطويلة أو معالجة الدفعات (batching).
شرح المعادلة
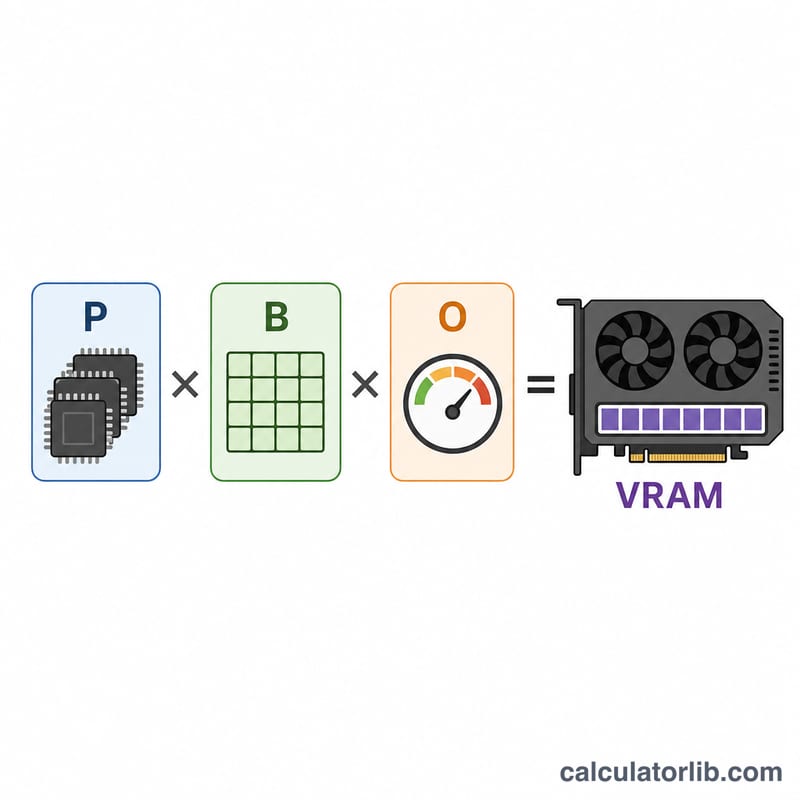
$$\text{VRAM (GB)} = \text{Params (B)} \times \text{Bytes/Param} \times \text{Overhead}$$ وبما أن المليار بايت يساوي تقريبًا 1 جيجابايت، فإن ضرب عدد المعاملات بالمليارات في عدد البايتات لكل معامل يعطينا الناتج مباشرةً بالجيجابايت. ثم يأتي عامل الهامش ليضاعف هذه القيمة بما يكفي لتغطية ذاكرة التشغيل الفعلية.
مثال تطبيقي
لنموذج بحجم 7B بدقة FP16 وبعامل هامش 1.2: $$7 \times 2 \times 1.2 = 16.8 \text{ جيجابايت}$$ وهو ما يتسع له بأريحية كرت بسعة 24 جيجابايت. وأما النموذج نفسه بدقة INT4: $$7 \times 0.5 \times 1.2 = 4.2 \text{ جيجابايت}$$ وهو قابل للتشغيل بسهولة على كرت شاشة بسعة 8 جيجابايت.
الأسئلة الشائعة
لماذا يكون الاستهلاك الفعلي أكبر من حجم الأوزان الخام؟ لأن ذاكرة الـ KV cache تتزايد مع طول السياق وحجم الدفعة، كما تحجز أطر العمل ذاكرة إضافية للتنشيطات والمخازن المؤقتة — وهذا تحديدًا ما يقدّره عامل الهامش الإضافي.
هل يشمل هذا التقدير مرحلة التدريب؟ لا. فالتدريب يحتاج إلى ذاكرة أكبر بنحو 3 إلى 4 أضعاف لتخزين حالات المُحسِّن (optimizer) والتدرجات؛ أما هذا التقدير فموجّه لمرحلة الاستدلال.
ما عامل الهامش المناسب؟ استخدم نحو 1.2 للمطالبات القصيرة، و1.5 إلى 2.0 أو أكثر مع السياقات الطويلة أو معالجة الدفعات الثقيلة.