
ماذا تفعل هذه الحاسبة
تساعدك حاسبة متطلبات ذاكرة VRAM لنماذج LLM على تقدير حجم ذاكرة كرت الشاشة (GPU) اللازمة لتحميل وتشغيل نموذج لغوي كبير. تعمل الحاسبة بضرب عدد معاملات النموذج (بالمليارات) في عدد البايتات التي يشغلها كل معامل وفق مستوى الدقة الذي تختاره، ثم تطبّق عامل هامش إضافي لتغطية التنشيطات (activations) وذاكرة KV cache والمخازن المؤقتة الخاصة بإطار العمل.
طريقة الاستخدام
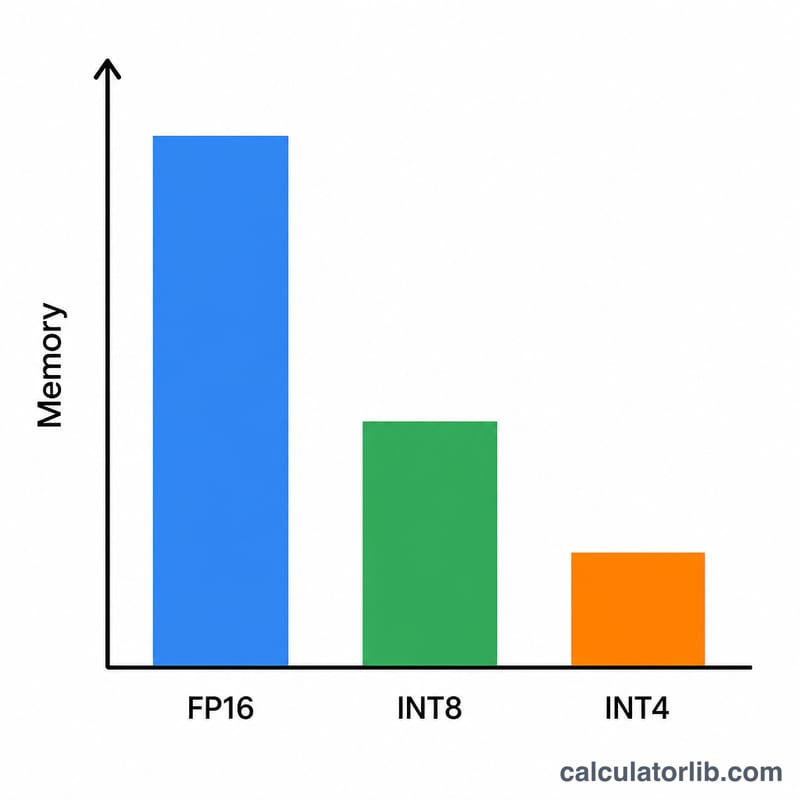
أدخِل حجم النموذج بعدد المعاملات بالمليارات (مثلاً 7 لنموذج بحجم 7B، أو 70 لنموذج بحجم 70B). ثم اختَر مستوى التكميم: تستخدم دقة FP16/BF16 بايتين لكل وزن، وINT8 بايتاً واحداً، و4-بت نصف بايت (0.5)، و2-بت ربع بايت (0.25). أما الهامش الافتراضي البالغ 1.2 (أي زيادة 20%) فهو نقطة بداية معقولة لعمليات الاستدلال (inference)؛ ارفعه عند العمل بسياقات طويلة أو بدفعات متعددة.
شرح المعادلة
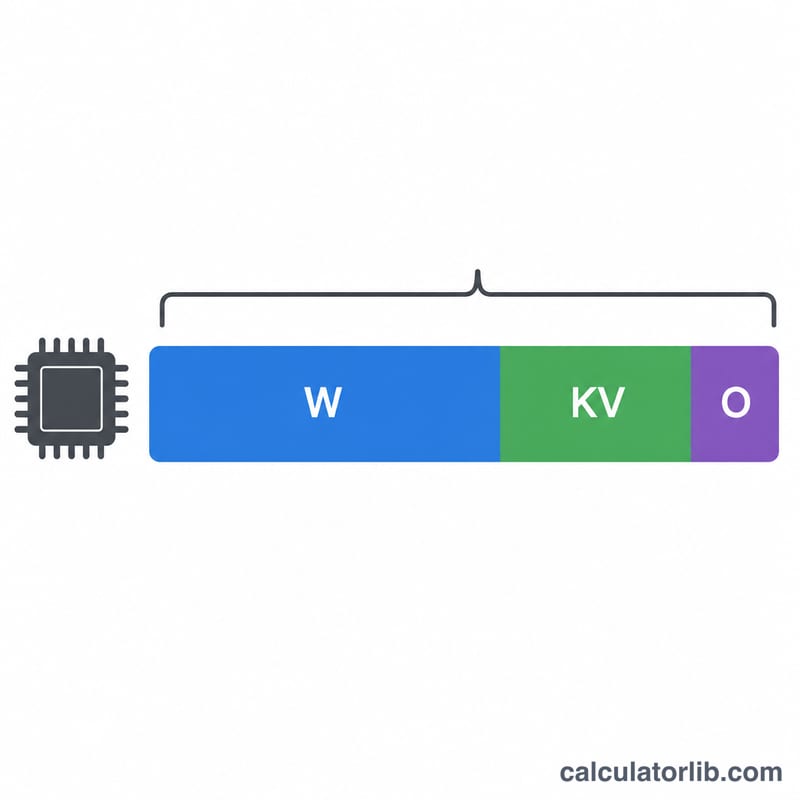
$$\text{VRAM (GB)} = \text{Params (B)} \times \text{Bytes/Param} \times \text{Overhead}$$ يعطي الحدّان الأولان الحجم الخام لأوزان النموذج بالجيجابايت. أما مُضاعِف الهامش فيحجز ذاكرة إضافية تستهلكها أطر العمل مثل PyTorch وCUDA إضافةً إلى ذاكرة KV cache الخاصة بالانتباه أثناء التشغيل، وهي ذاكرة لا يأخذها حجم الأوزان الخام في الحسبان.
مثال تطبيقي
لنأخذ نموذجاً بحجم 7B بدقة 4-بت: \(7 \times 0.5 = 3.5\) جيجابايت من الأوزان. وبتطبيق عامل هامش 1.2: \(3.5 \times 1.2 = 4.2\) جيجابايت. هذا يتسع بأريحية ضمن كرت شاشة استهلاكي سعة 8 جيجابايت. أما النموذج نفسه بدقة FP16 فيحتاج إلى \(7 \times 2 \times 1.2 = 16.8\) جيجابايت، وهو ما يستلزم كرتاً بسعة 24 جيجابايت.
الأسئلة الشائعة
هل هذا التقدير دقيق تماماً؟ لا — إنه تقدير لعمليات الاستدلال. يختلف الاستهلاك الفعلي حسب طول السياق وحجم الدفعة وإطار العمل المستخدم. استعمله لأغراض التخطيط، لا لتحديد آخر ميجابايت.
هل يشمل ذاكرة التدريب؟ لا. يحتاج التدريب إلى ذاكرة أكبر بكثير (حالات المُحسِّن والتدرّجات)، وغالباً ما تبلغ 4 أضعاف رقم الاستدلال أو أكثر.
أي قيمة هامش ينبغي أن أستخدم؟ القيمة 1.2 مناسبة للاستدلال بسياق قصير؛ استخدم 1.3–1.5 للسياقات الطويلة أو الطلبات المتزامنة.