
이 계산기로 무엇을 알 수 있나요
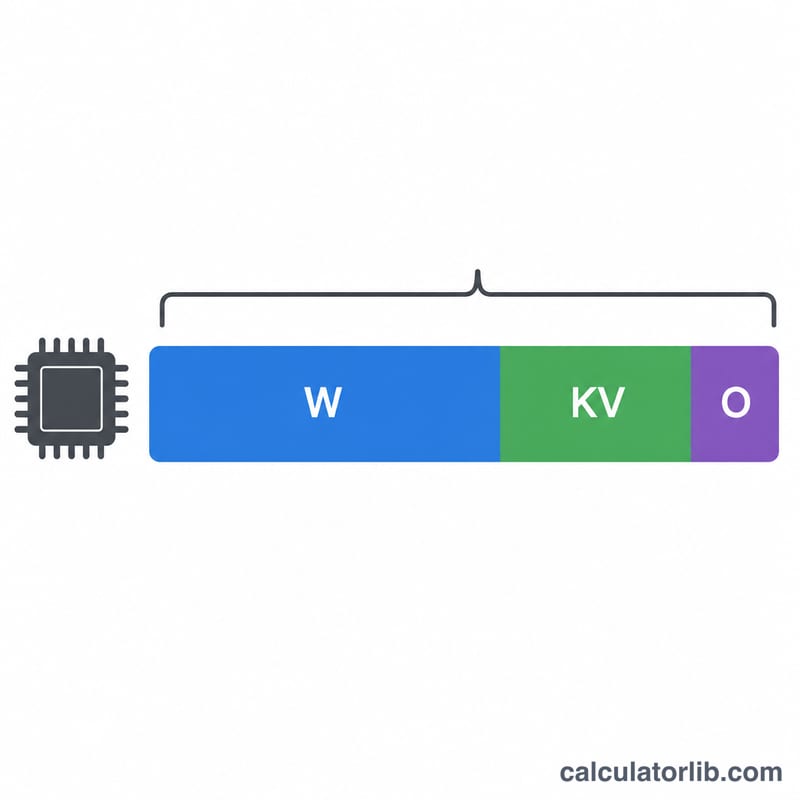
LLM VRAM 요구량 계산기는 대규모 언어 모델을 로딩하고 실행하는 데 GPU 메모리가 얼마나 필요한지 추정해 줍니다. 모델의 파라미터 수(10억 단위)에 선택한 정밀도에서 파라미터 하나가 차지하는 바이트 수를 곱한 뒤, 활성화 값(activation), KV 캐시, 프레임워크 버퍼 등을 감안한 오버헤드 계수를 적용하는 방식입니다.
사용 방법
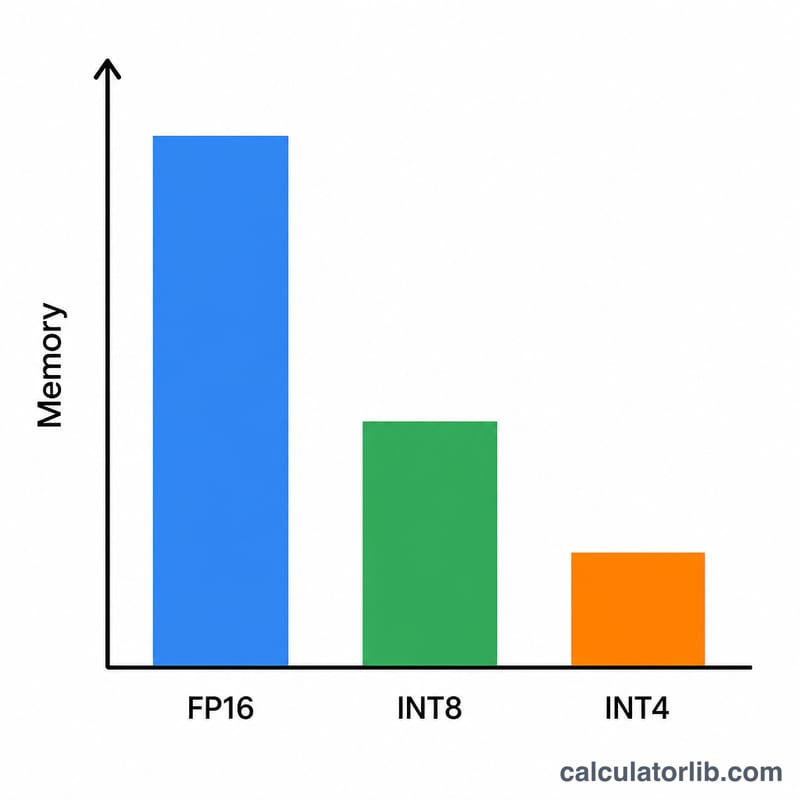
모델 크기를 10억 파라미터 단위로 입력하세요(예: 7B 모델이면 7, 70B 모델이면 70). 그다음 양자화 방식을 고릅니다. FP16/BF16은 가중치당 2바이트, INT8은 1바이트, 4비트는 0.5바이트, 2비트는 0.25바이트를 사용합니다. 기본 오버헤드 값인 1.2(20% 여유분)는 추론(inference)용으로 무난한 출발점입니다. 긴 컨텍스트나 배치 처리 작업이라면 이 값을 더 높여 주세요.
계산식 설명
$$\text{VRAM (GB)} = \text{Params (B)} \times \text{Bytes/Param} \times \text{Overhead}$$ 앞의 두 항은 모델 가중치의 순수 크기(GB)를 나타냅니다. 오버헤드 계수는 PyTorch, CUDA, 어텐션 KV 캐시가 실행 중에 추가로 소비하는 메모리를 확보해 주는데, 이는 가중치 크기만으로는 계산되지 않는 부분입니다.
예시로 살펴보기
7B 모델을 4비트 정밀도로 돌린다면: \(7 \times 0.5 = 3.5\,\text{GB}\) 가중치. 여기에 오버헤드 계수 1.2를 적용하면 $$3.5 \times 1.2 = 4.2\,\text{GB}$$ 가 됩니다. 8GB 보급형 GPU에도 여유 있게 들어가는 수준이죠. 같은 모델을 FP16으로 돌리면 \(7 \times 2 \times 1.2 = 16.8\,\text{GB}\)가 필요해, 24GB짜리 카드가 있어야 합니다.
자주 묻는 질문
이 수치가 정확한가요? 아닙니다. 어디까지나 추론용 추정치입니다. 실제 사용량은 컨텍스트 길이, 배치 크기, 서빙 프레임워크에 따라 달라집니다. 메가바이트 단위까지 따지기보다는 계획을 세우는 용도로 활용하세요.
학습(training)에 필요한 메모리도 포함되나요? 아닙니다. 학습에는 옵티마이저 상태, 그래디언트 등 때문에 훨씬 더 많은 메모리가 필요하며, 추론 수치의 4배 이상이 드는 경우도 흔합니다.
오버헤드는 얼마로 잡아야 하나요? 짧은 컨텍스트 추론에는 1.2면 충분합니다. 긴 컨텍스트나 동시 요청 처리에는 1.3~1.5를 사용하세요.