
Что считает этот калькулятор
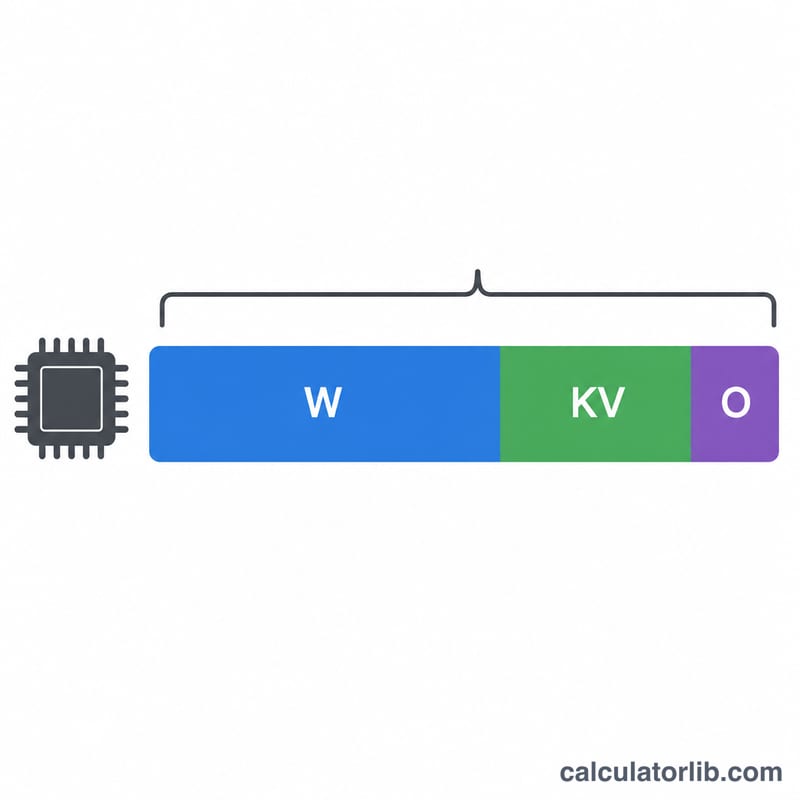
Калькулятор VRAM для LLM показывает, сколько видеопамяти GPU потребуется, чтобы загрузить и запустить большую языковую модель. Он умножает число параметров модели (в миллиардах) на количество байт, которое занимает каждый параметр при выбранной точности, а затем добавляет коэффициент запаса — на активации, KV-кэш и служебные буферы фреймворка.
Как пользоваться
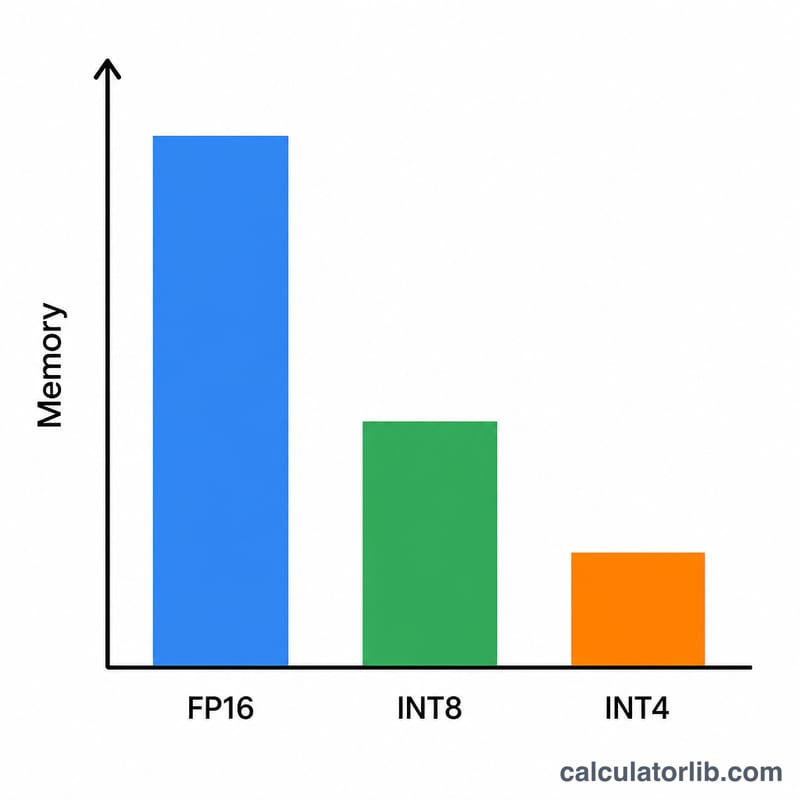
Укажите размер модели в миллиардах параметров (например, 7 для модели 7B или 70 для 70B). Выберите квантование: FP16/BF16 — 2 байта на вес, INT8 — 1 байт, 4-бит — 0,5 байта, 2-бит — 0,25 байта. Значение запаса по умолчанию 1,2 (то есть +20%) — разумная точка отсчёта для инференса; увеличивайте его при длинном контексте или пакетной обработке.
Разбор формулы
$$\text{VRAM (ГБ)} = \text{параметры (млрд)} \times \text{байт на параметр} \times \text{коэффициент запаса}$$ Первые два множителя дают «чистый» объём весов модели в гигабайтах. Коэффициент запаса резервирует дополнительную память, которую во время работы потребляют PyTorch, CUDA и KV-кэш механизма внимания, — её один лишь размер весов не учитывает.
Пример расчёта
Модель 7B в 4-битной точности: $$7 \times 0{,}5 = 3{,}5 \text{ ГБ весов}$$ С коэффициентом запаса 1,2: $$3{,}5 \times 1{,}2 = 4{,}2 \text{ ГБ}$$ Это спокойно помещается на потребительскую видеокарту с 8 ГБ. Та же модель в FP16 требует \(7 \times 2 \times 1{,}2 = 16{,}8\) ГБ — а значит, нужна карта на 24 ГБ.
Частые вопросы
Это точный расчёт? Нет — это оценка для инференса. Реальное потребление зависит от длины контекста, размера батча и используемого фреймворка. Опирайтесь на эти цифры при планировании, но не до последнего мегабайта.
Учитывается ли память для обучения? Нет. Обучению нужно гораздо больше — на состояния оптимизатора и градиенты уходит зачастую в 4 раза и более от объёма для инференса.
Какой коэффициент запаса выбрать? 1,2 подходит для инференса с коротким контекстом; используйте 1,3–1,5 при длинном контексте или одновременных запросах.





