
Công cụ này làm gì?
Công cụ tính VRAM cho LLM giúp bạn ước tính lượng bộ nhớ GPU cần thiết để nạp và chạy một mô hình ngôn ngữ lớn. Cách tính khá đơn giản: lấy số tham số của mô hình (tính bằng tỷ) nhân với số byte mà mỗi tham số chiếm ở mức độ chính xác bạn chọn, sau đó nhân thêm một hệ số dự phòng để tính cả phần activations, bộ nhớ đệm KV (KV cache) và các vùng đệm của framework.
Cách sử dụng
Nhập kích thước mô hình theo tỷ tham số (ví dụ nhập 7 cho mô hình 7B, hoặc 70 cho mô hình 70B). Tiếp theo chọn mức lượng tử hóa: FP16/BF16 dùng 2 byte cho mỗi trọng số, INT8 dùng 1 byte, 4-bit dùng 0,5 byte và 2-bit chỉ dùng 0,25 byte. Hệ số dự phòng mặc định 1,2 (tức cộng thêm 20%) là điểm khởi đầu hợp lý cho việc suy luận (inference); nếu bạn chạy ngữ cảnh dài hoặc xử lý theo lô (batch), hãy tăng hệ số này lên.
Giải thích công thức
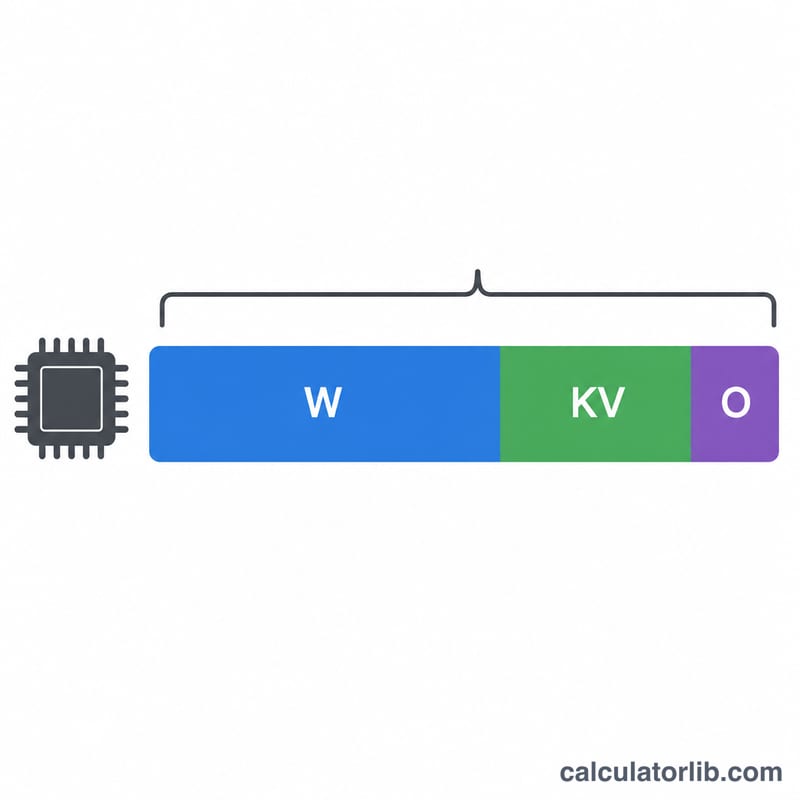
$$\text{VRAM (GB)} = \text{Params (B)} \times \text{Bytes/Param} \times \text{Overhead}$$ Hai thừa số đầu cho ra dung lượng thô của trọng số mô hình tính bằng gigabyte. Hệ số dự phòng dành ra phần bộ nhớ mà PyTorch, CUDA và KV cache của cơ chế attention tiêu tốn khi chạy thực tế — đây chính là phần mà nếu chỉ tính dung lượng trọng số thô sẽ bị bỏ sót.
Ví dụ minh họa
Với mô hình 7B ở mức 4-bit: $$7 \times 0{,}5 = 3{,}5 \text{ GB}$$ trọng số. Nhân với hệ số dự phòng 1,2: $$3{,}5 \times 1{,}2 = 4{,}2 \text{ GB}$$ Con số này nằm gọn trong một chiếc GPU phổ thông 8 GB. Vẫn là mô hình đó nhưng chạy ở FP16 sẽ cần \(7 \times 2 \times 1{,}2 = 16{,}8\) GB, đòi hỏi một card 24 GB.
Câu hỏi thường gặp
Kết quả có chính xác tuyệt đối không? Không — đây chỉ là con số ước tính cho inference. Mức tiêu thụ thực tế còn thay đổi theo độ dài ngữ cảnh, kích thước lô và framework phục vụ mô hình. Hãy dùng nó để lên kế hoạch, đừng kỳ vọng chính xác đến từng megabyte.
Con số này đã bao gồm bộ nhớ cho huấn luyện chưa? Chưa. Huấn luyện (training) cần nhiều bộ nhớ hơn rất nhiều do phải lưu trạng thái optimizer và gradient — thường gấp 4 lần hoặc hơn so với con số inference.
Nên dùng hệ số dự phòng bao nhiêu? 1,2 là đủ cho inference với ngữ cảnh ngắn; hãy dùng 1,3–1,5 nếu ngữ cảnh dài hoặc xử lý nhiều yêu cầu đồng thời.