Công cụ tính VRAM cho LLM là gì?
Công cụ này giúp bạn ước tính lượng bộ nhớ đồ họa GPU (VRAM) cần có để nạp và chạy một mô hình ngôn ngữ lớn (LLM) trong giai đoạn suy luận (inference). Mức bộ nhớ phụ thuộc chủ yếu vào số lượng tham số của mô hình và độ chính xác số học dùng để lưu mỗi trọng số. Ngoài ra, một hệ số dự phòng (overhead) được thêm vào để bù cho KV cache, các activation và CUDA context — những thành phần tiêu tốn bộ nhớ ngoài phần trọng số thô.
Cách sử dụng
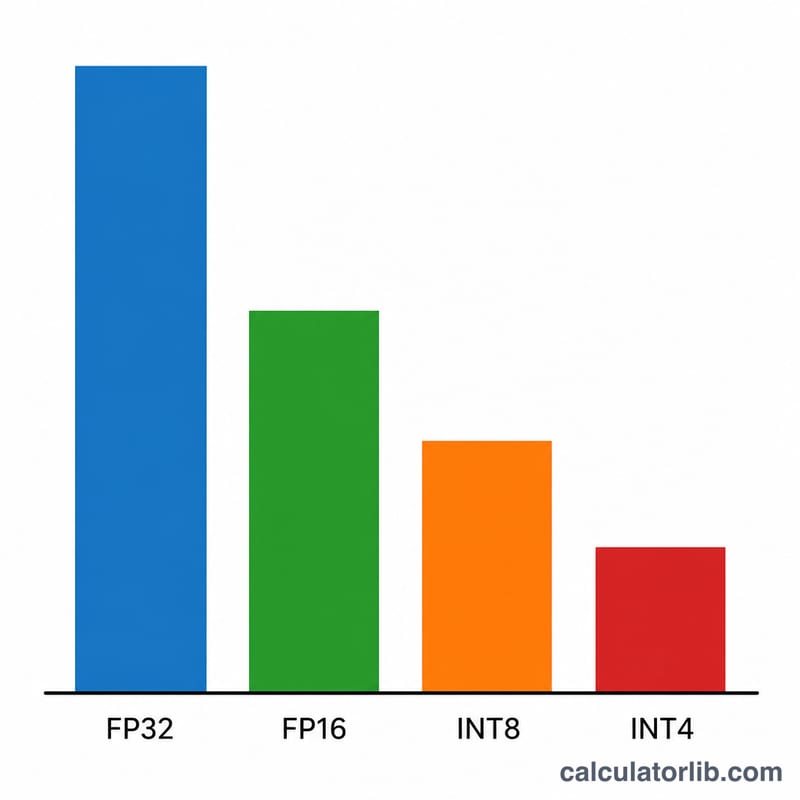
Nhập kích thước mô hình theo đơn vị tỷ tham số (ví dụ nhập 7 cho mô hình 7B, hoặc 70 cho Llama-3 70B). Chọn độ chính xác: FP32 dùng 4 byte mỗi trọng số, FP16/BF16 dùng 2 byte, INT8 dùng 1 byte, còn lượng tử hóa INT4 chỉ dùng 0,5 byte. Cuối cùng, đặt hệ số dự phòng — giá trị 1,2 (tức dư 20%) là mức mặc định hợp lý cho suy luận với ngữ cảnh ngắn; hãy tăng lên nếu bạn dùng ngữ cảnh dài hoặc xử lý theo lô (batching).
Giải thích công thức
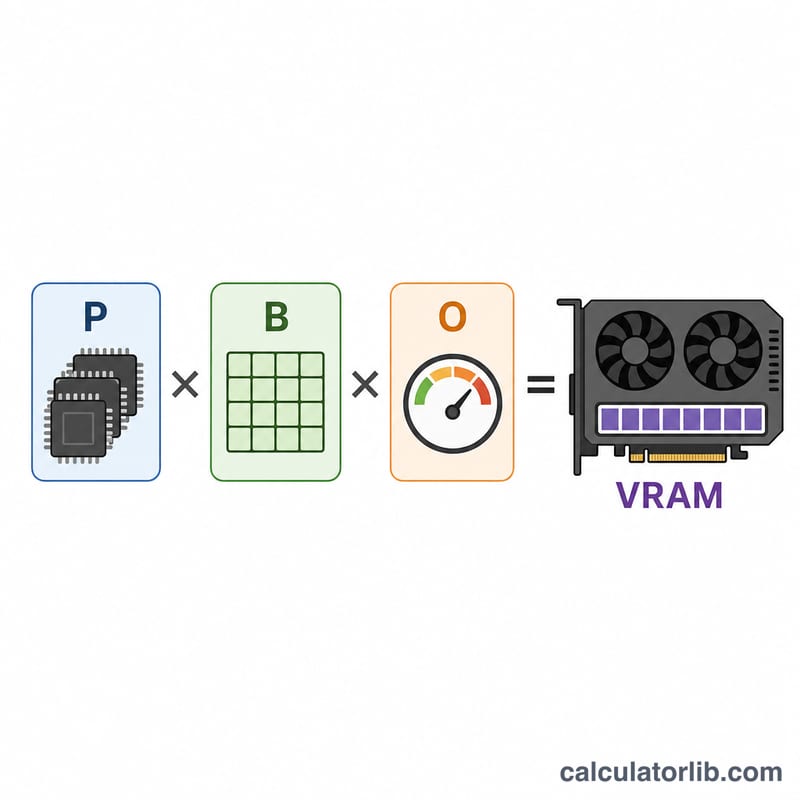
$$\text{VRAM (GB)} = \text{Số tham số (tỷ)} \times \text{Số byte mỗi tham số} \times \text{Hệ số dự phòng}$$ Vì 1 tỷ byte ≈ 1 GB, nên khi nhân số tham số (tính theo tỷ) với số byte mỗi tham số, bạn nhận được kết quả tính bằng gigabyte luôn. Hệ số dự phòng sau đó nhân thêm vào để bao trùm phần bộ nhớ phát sinh lúc chạy.
Ví dụ minh họa
Với mô hình 7B ở định dạng FP16 và hệ số dự phòng 1,2: $$7 \times 2 \times 1{,}2 = 16{,}8 \text{ GB}$$ Mức này nằm gọn trong một card 24 GB. Cũng mô hình đó nhưng ở INT4: $$7 \times 0{,}5 \times 1{,}2 = 4{,}2 \text{ GB}$$ chạy dễ dàng trên GPU 8 GB.
Câu hỏi thường gặp
Vì sao mức sử dụng thực tế cao hơn phần trọng số thô? KV cache phình to theo độ dài ngữ cảnh và kích thước lô, đồng thời framework còn dành riêng bộ nhớ cho các activation và buffer — đó chính là phần mà hệ số dự phòng ước lượng.
Con số này có bao gồm việc huấn luyện không? Không. Huấn luyện cần nhiều hơn khoảng 3–4 lần bộ nhớ để lưu trạng thái optimizer và gradient; ước tính ở đây chỉ dành cho suy luận.
Nên dùng hệ số dự phòng bao nhiêu? Dùng khoảng 1,2 cho prompt ngắn, và 1,5–2,0 trở lên cho ngữ cảnh dài hoặc khi xử lý lô lớn.