什么是大模型显存需求计算器?
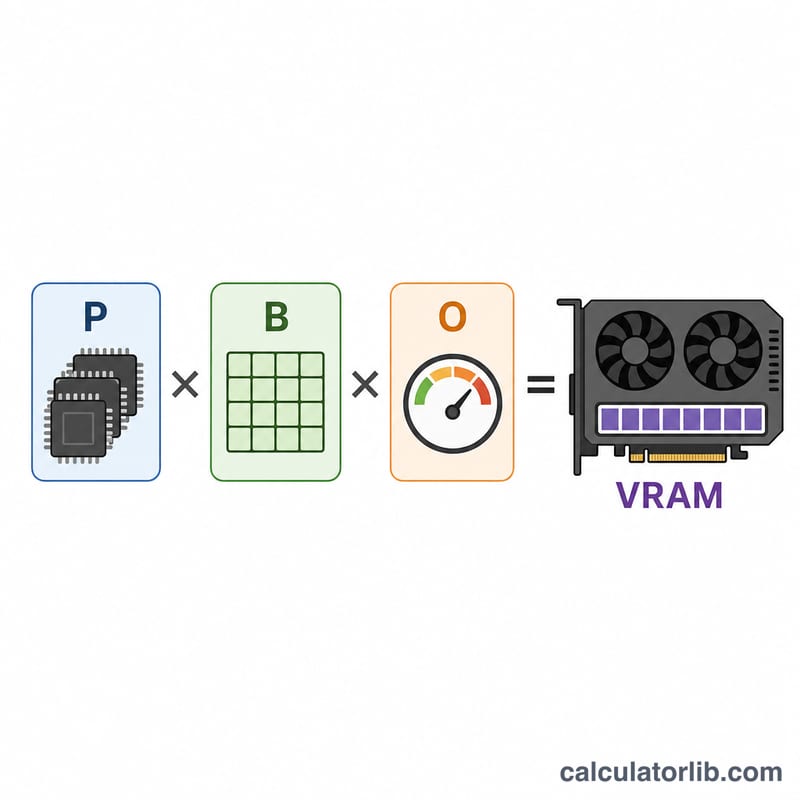
这个工具能帮你估算加载并运行大语言模型(LLM)进行推理时,大约需要多少 GPU 显存(VRAM)。显存占用主要取决于两个因素:模型的参数量,以及存储每个权重所采用的数值精度。此外,我们还引入了一个安全/开销系数,用来覆盖 KV 缓存、激活值和 CUDA 上下文等在纯权重之外额外消耗的显存。
如何使用
先填入模型规模,单位为「十亿参数」(例如 7B 模型填 7,Llama-3 70B 填 70)。接着选择数值精度:FP32 每个权重占 4 字节,FP16/BF16 占 2 字节,INT8 占 1 字节,INT4 量化则只占 0.5 字节。最后设置开销系数——对于短上下文推理,1.2(即预留 20% 缓冲)是一个比较合理的默认值;如果是长上下文或需要批量推理,则应适当调高。
计算公式解析
$$\text{显存(GB)} = \text{参数量(十亿)} \times \text{每参数字节数} \times \text{开销系数}$$由于 10 亿字节 ≈ 1 GB,所以用「十亿为单位的参数量」乘以「每参数字节数」就能直接得到 GB 数。再乘以开销系数,即可把运行时的额外显存一并算进去。
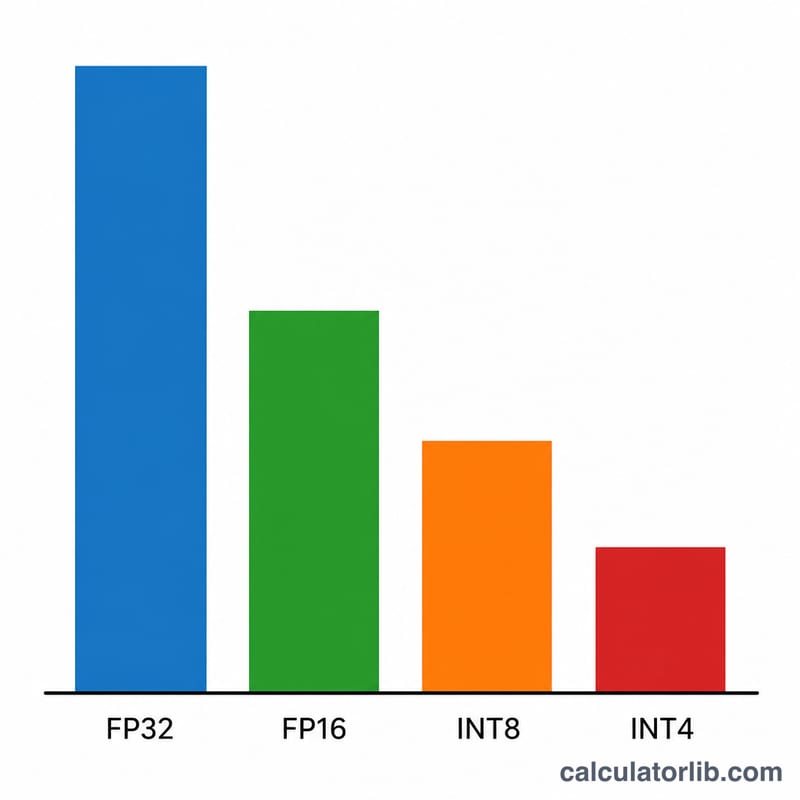
实例演算
以一个 7B 模型、采用 FP16 精度、开销系数为 1.2 为例:$$7 \times 2 \times 1.2 = 16.8 \text{ GB}$$一张 24 GB 的显卡可以轻松容纳。同样的模型若改用 INT4:$$7 \times 0.5 \times 1.2 = 4.2 \text{ GB}$$连 8 GB 的 GPU 都能流畅运行。
常见问题
为什么实际占用比纯权重还要高?KV 缓存会随着上下文长度和批量大小而增长,框架本身也会为激活值和各类缓冲区预留空间——开销系数正是用来近似估算这部分额外消耗的。
这个估算包含训练吗?不包含。训练因为要保存优化器状态和梯度,所需显存大约是推理的 3~4 倍;本计算器只针对推理场景。
开销系数该怎么设?短提示词用 1.2 左右即可;长上下文或大批量推理则建议设为 1.5~2.0 甚至更高。