LLM VRAM必要量 計算ツールとは?
このツールは、大規模言語モデル(LLM)を推論用に読み込んで動かすために、GPUのビデオメモリ(VRAM)がどれくらい必要かを見積もるためのものです。必要なメモリ量は、主にモデルのパラメータ数と、各重みを格納する際の数値精度によって決まります。さらにオーバーヘッド(安全係数)を掛けることで、生の重み以外に消費されるKVキャッシュ・アクティベーション・CUDAコンテキストなどの分も考慮できます。
使い方
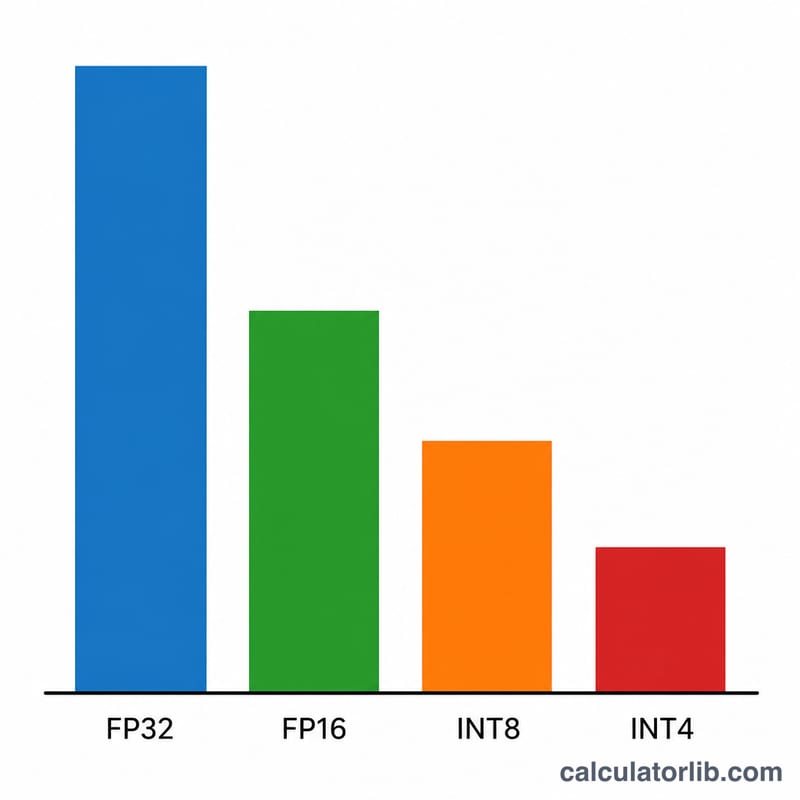
まず、モデルサイズを「10億(B)単位」のパラメータ数で入力します(例:7Bモデルなら「7」、Llama-3 70Bなら「70」)。次に精度を選びます。FP32は重み1つあたり4バイト、FP16/BF16は2バイト、INT8は1バイト、INT4量子化は0.5バイトです。最後にオーバーヘッド係数を設定します。短いコンテキストの推論なら1.2(20%のバッファ)が手頃な初期値で、長いコンテキストやバッチ処理を行う場合は値を大きくしてください。
計算式の解説
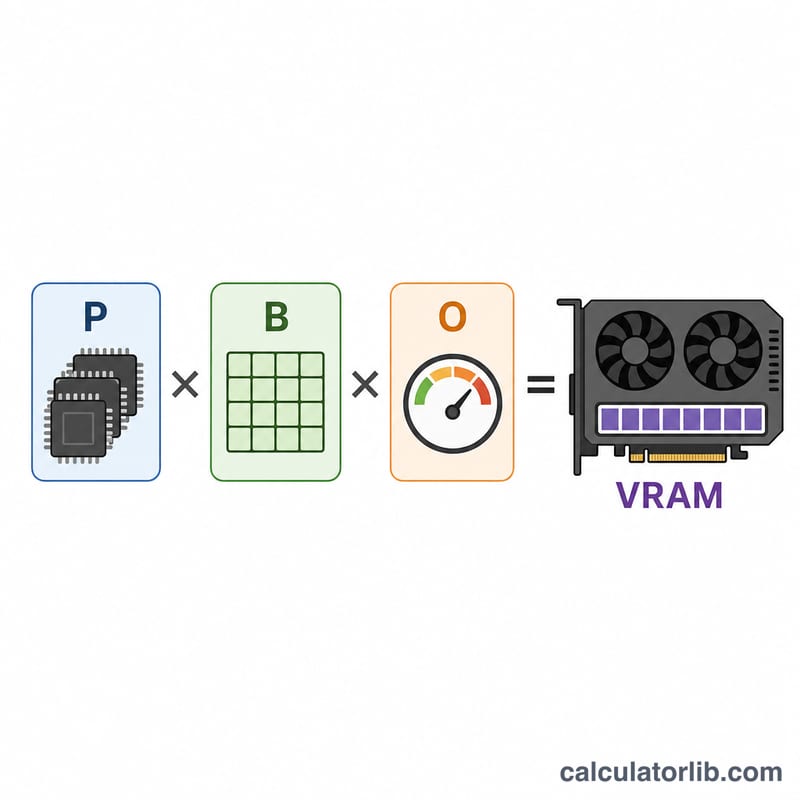
$$\text{VRAM (GB)} = \text{Params (B)} \times \text{Bytes/Param} \times \text{Overhead}$$10億バイト ≒ 1GB であるため、10億単位のパラメータ数に1パラメータあたりのバイト数を掛けると、そのままギガバイト(GB)の値が得られます。さらにオーバーヘッド係数を掛けることで、実行時に必要なメモリ分まで上乗せして見積もれます。
計算例
7BモデルをFP16で、オーバーヘッド係数1.2として計算すると、$$7 \times 2 \times 1.2 = 16.8\,\text{GB}$$となります。これなら24GBのカードに余裕を持って収まります。同じモデルをINT4にすると、$$7 \times 0.5 \times 1.2 = 4.2\,\text{GB}$$となり、8GBのGPUでも楽に動かせます。
よくある質問(FAQ)
なぜ実際の使用量は、生の重みより大きくなるのですか? KVキャッシュはコンテキスト長やバッチサイズに応じて増加し、フレームワークもアクティベーションやバッファ用にメモリを確保します。オーバーヘッド係数は、こうした分をおおまかに見込むためのものです。
これは学習(トレーニング)も含みますか? いいえ。学習ではオプティマイザの状態や勾配のために、おおよそ3〜4倍のメモリが必要になります。この見積もりはあくまで推論を対象としています。
オーバーヘッド係数はどれくらいにすべきですか? 短いプロンプトなら約1.2、長いコンテキストや重いバッチ処理では1.5〜2.0以上を目安にしてください。