Qu'est-ce que le calculateur de VRAM pour LLM ?
Cet outil estime la quantité de mémoire vidéo GPU (VRAM) nécessaire pour charger et faire tourner un grand modèle de langage (LLM) en inférence. Cette mémoire dépend avant tout du nombre de paramètres du modèle et de la précision numérique utilisée pour stocker chaque poids. Un facteur de surcharge (marge de sécurité) prend en compte le cache KV, les activations et le contexte CUDA, qui consomment de la mémoire en plus des poids bruts.
Comment l'utiliser
Indiquez la taille du modèle en milliards de paramètres (par exemple 7 pour un modèle 7B, ou 70 pour Llama-3 70B). Choisissez la précision : le FP32 utilise 4 octets par poids, le FP16/BF16 en utilise 2, l'INT8 en utilise 1 et la quantification INT4 n'en utilise que 0,5. Réglez enfin le facteur de surcharge : 1,2 (soit une marge de 20 %) constitue une valeur par défaut raisonnable pour de l'inférence en contexte court ; augmentez-le pour les contextes longs ou le traitement par lots (batching).
La formule expliquée
$$\text{VRAM (Go)} = \text{Paramètres (milliards)} \times \text{Octets par paramètre} \times \text{Surcharge}$$ Comme 1 milliard d'octets ≈ 1 Go, multiplier le nombre de paramètres exprimé en milliards par le nombre d'octets par paramètre donne directement un résultat en gigaoctets. Le facteur de surcharge vient ensuite majorer ce total pour couvrir la mémoire utilisée à l'exécution.
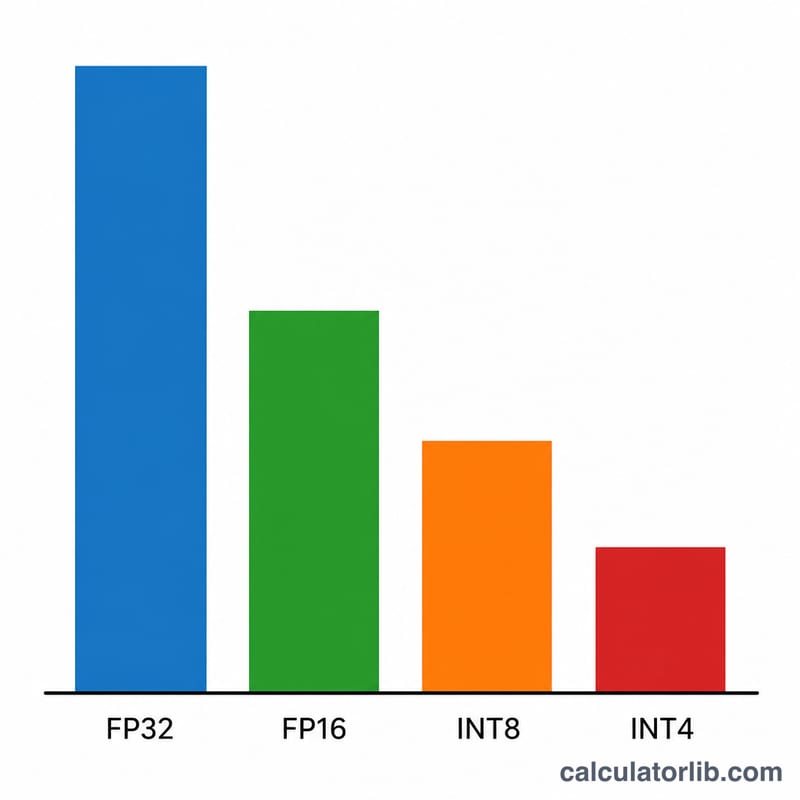
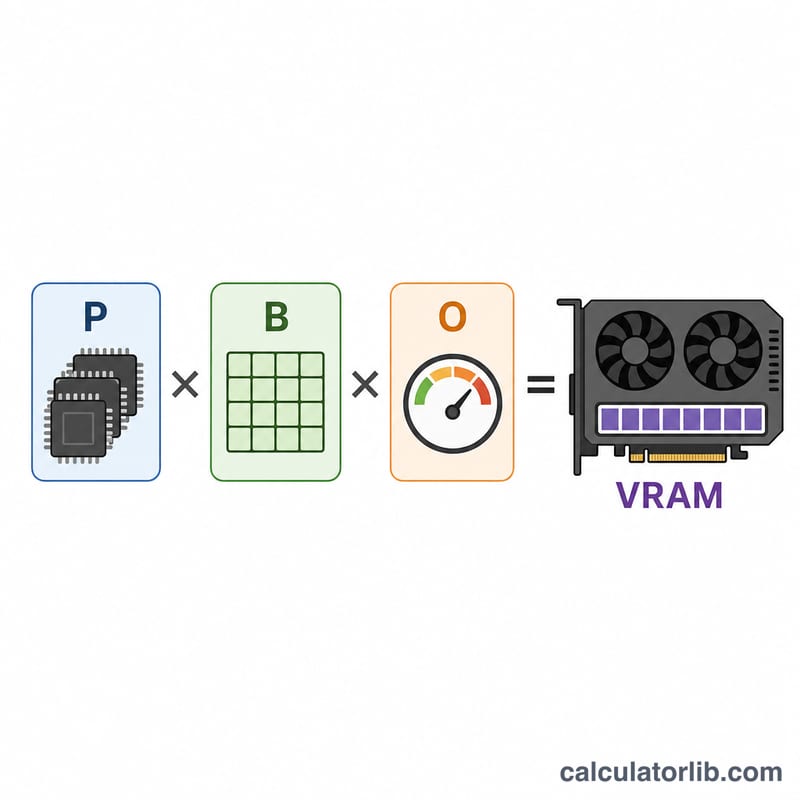
Exemple concret
Pour un modèle 7B en FP16 avec un facteur de surcharge de 1,2 : $$7 \times 2 \times 1{,}2 = 16{,}8 \text{ Go}$$ Cela tient confortablement sur une carte de 24 Go. Le même modèle en INT4 : $$7 \times 0{,}5 \times 1{,}2 = 4{,}2 \text{ Go}$$ qui tourne sans problème sur un GPU de 8 Go.
FAQ
Pourquoi l'utilisation réelle dépasse-t-elle la taille des poids bruts ? Le cache KV grandit avec la longueur du contexte et la taille du lot, et le framework réserve de la mémoire pour les activations et les tampons : c'est précisément ce que le facteur de surcharge cherche à approximer.
Cela inclut-il l'entraînement ? Non. L'entraînement nécessite environ 3 à 4 fois plus de mémoire pour les états de l'optimiseur et les gradients ; cette estimation concerne uniquement l'inférence.
Quel facteur de surcharge utiliser ? Comptez environ 1,2 pour des prompts courts, et 1,5 à 2,0 (voire plus) pour les contextes longs ou un batching important.