
À quoi sert ce calculateur
Le calculateur de VRAM pour LLM estime la quantité de mémoire GPU nécessaire pour charger et exécuter un grand modèle de langage (LLM). Il multiplie le nombre de paramètres du modèle (en milliards) par le nombre d'octets occupés par chaque paramètre à la précision choisie, puis applique un facteur de marge tenant compte des activations, du cache KV et des tampons du framework.
Comment l'utiliser
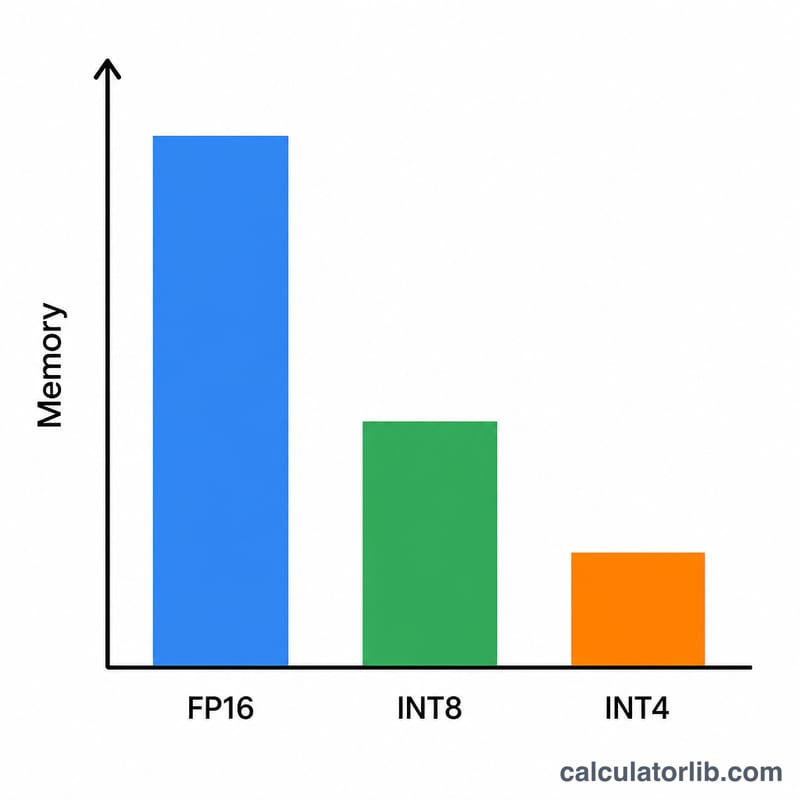
Indiquez la taille du modèle en milliards de paramètres (par exemple 7 pour un modèle 7B, 70 pour un modèle 70B). Choisissez la quantification : FP16/BF16 utilise 2 octets par poids, INT8 en utilise 1, le 4 bits 0,5 octet et le 2 bits 0,25 octet. La marge par défaut de 1,2 (soit un tampon de 20 %) constitue un bon point de départ pour l'inférence ; augmentez-la pour les contextes longs ou les traitements par lots.
La formule expliquée
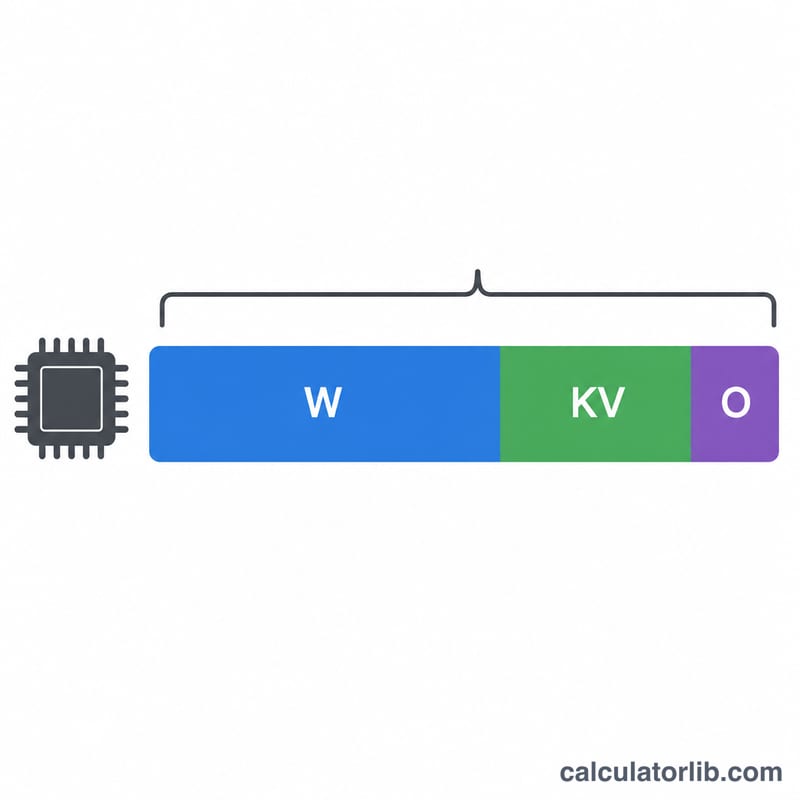
$$\text{VRAM (Go)} = \text{Paramètres (milliards)} \times \text{octets par paramètre} \times \text{marge}$$ Les deux premiers termes donnent la taille brute des poids du modèle en gigaoctets. Le facteur de marge réserve la mémoire supplémentaire que consomment PyTorch, CUDA et le cache KV de l'attention au moment de l'exécution — une consommation que la seule taille des poids ne prend pas en compte.
Exemple concret
Un modèle 7B en précision 4 bits : \(7 \times 0{,}5 = 3{,}5\) Go de poids. Avec un facteur de marge de 1,2 : \(3{,}5 \times 1{,}2 = 4{,}2\) Go. Cela tient sans problème sur un GPU grand public de 8 Go. Le même modèle en FP16 nécessite \(7 \times 2 \times 1{,}2 = 16{,}8\) Go, ce qui exige une carte de 24 Go.
FAQ
Est-ce exact ? Non — il s'agit d'une estimation pour l'inférence. La consommation réelle varie selon la longueur du contexte, la taille des lots et le framework de service utilisé. Servez-vous-en pour planifier, pas au mégaoctet près.
Cela inclut-il la mémoire d'entraînement ? Non. L'entraînement demande beaucoup plus de mémoire (états de l'optimiseur, gradients), souvent 4 fois ou davantage le chiffre de l'inférence.
Quelle marge utiliser ? 1,2 convient pour une inférence à contexte court ; utilisez 1,3 à 1,5 pour les contextes longs ou les requêtes simultanées.