
這個計算器的用途
LLM 顯存需求計算器能幫你估算載入並執行大型語言模型所需的 GPU 記憶體。它會將模型的參數量(以十億為單位)乘上你所選精度下每個參數佔用的位元組數,再套用一個額外開銷係數,把激活值(activations)、KV 快取以及框架緩衝區等運算負擔一併納入考量。
使用方式
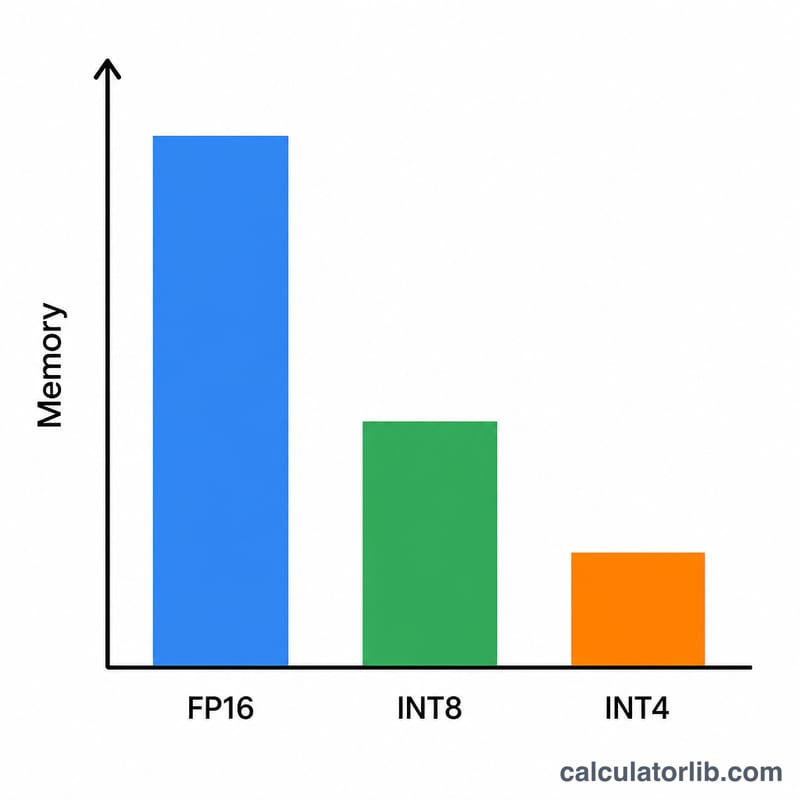
輸入模型大小,單位為十億參數(例如 7B 模型填 7、70B 模型填 70)。接著選擇量化精度:FP16/BF16 每個權重佔 2 位元組,INT8 佔 1 位元組,4-bit 佔 0.5 位元組,2-bit 則佔 0.25 位元組。預設的額外開銷係數為 1.2(也就是預留 20% 的緩衝),對推論用途來說是合理的起點;若你要處理長上下文或批次運算,可以再往上調高。
公式說明
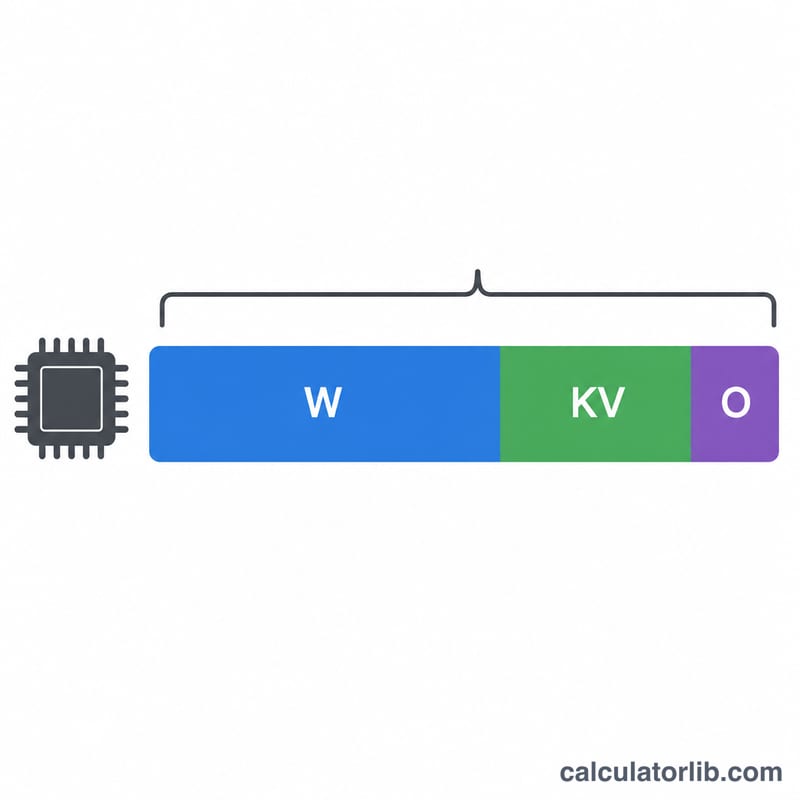
$$\text{顯存 (GB)} = \text{參數量 (十億)} \times \text{每參數位元組數} \times \text{額外開銷係數}$$前兩項相乘可得出模型權重本身的大小(GB)。而額外開銷係數則用來預留 PyTorch、CUDA 以及注意力機制 KV 快取在執行階段所消耗的額外記憶體——這些都是單看權重大小所無法反映的。
實例試算
以 7B 模型搭配 4-bit 精度為例:\(7 \times 0.5 = 3.5\) GB 的權重。再乘上 1.2 的額外開銷係數:$$3.5 \times 1.2 = 4.2 \text{ GB}$$這樣的需求在 8 GB 的消費級顯示卡上可以從容運行。同一個模型若改用 FP16,則需要 \(7 \times 2 \times 1.2 = 16.8\) GB,這就得靠 24 GB 等級的顯示卡才跑得動了。
常見問題
這個數字準確嗎?不算精確——它是一個推論階段的估算值。實際用量會隨上下文長度、批次大小與所使用的服務框架而有所不同。建議拿來做規劃參考,不必斤斤計較到最後一 MB。
有把訓練所需的記憶體算進去嗎?沒有。訓練所需的記憶體遠遠更多(包含優化器狀態、梯度等),往往是推論數字的 4 倍以上。
額外開銷係數該設多少?短上下文推論用 1.2 就很夠了;若是長上下文或需要同時處理多個請求,建議調到 1.3~1.5。