这个计算器能做什么
大语言模型显存需求计算器可以帮你估算加载并运行一个大语言模型(LLM)需要多少 GPU 显存。它会用模型的参数量(以十亿 B 为单位)乘以所选精度下每个参数占用的字节数,再乘以一个开销系数,把激活值、KV 缓存以及框架自身占用的缓冲区也考虑进去。
如何使用
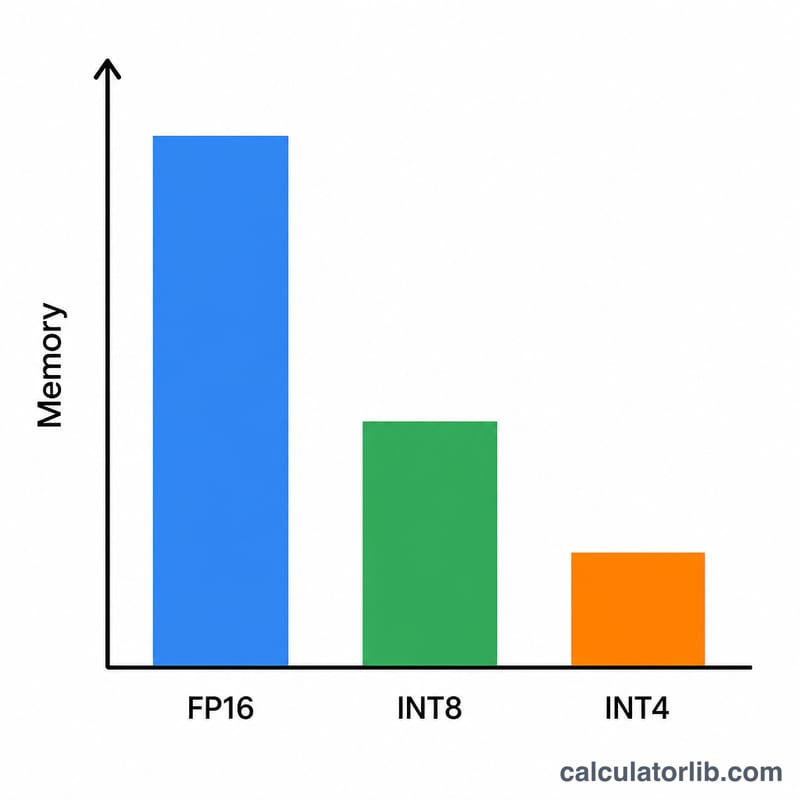
填入模型参数量,单位为十亿(例如 7B 模型填 7,70B 模型填 70)。然后选择量化精度:FP16/BF16 每个权重占 2 字节,INT8 占 1 字节,4-bit 占 0.5 字节,2-bit 占 0.25 字节。默认开销系数为 1.2(即预留 20% 的余量),这对推理场景来说是一个比较合理的起点;如果你要跑长上下文或批量请求,可以适当调高。
计算公式解析
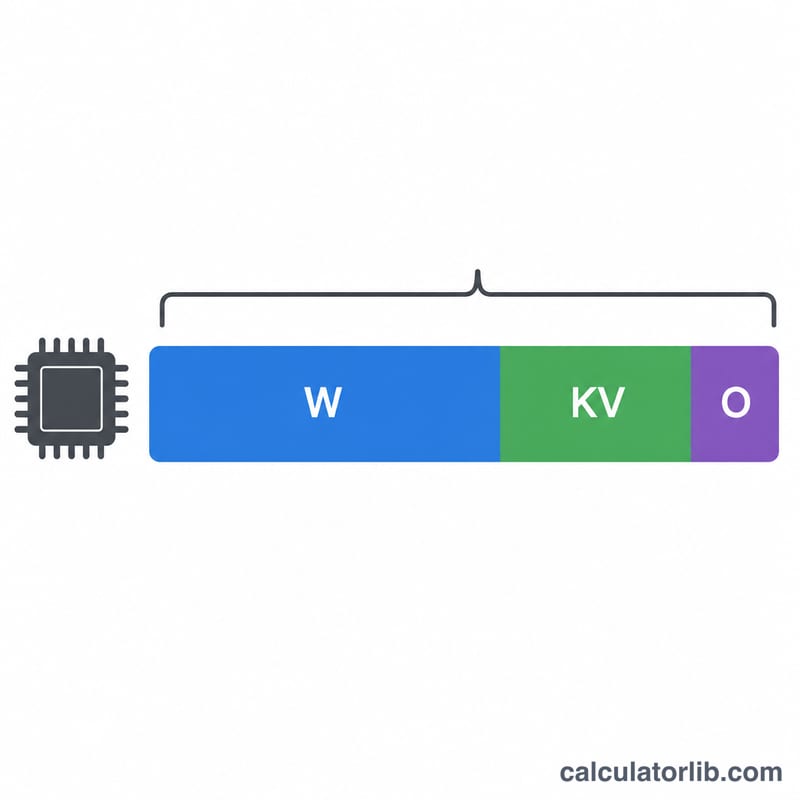
$$\text{显存(GB)} = \text{参数量(十亿)} \times \text{每参数字节数} \times \text{开销系数}$$前两项算出的是模型权重本身的原始大小(单位 GB)。开销系数则用来预留 PyTorch、CUDA 以及注意力机制 KV 缓存在运行时额外占用的内存——这些都是单看权重大小所忽略掉的部分。
实例演算
以一个 7B 模型、4-bit 精度为例:\(7 \times 0.5 = 3.5\) GB 权重。再乘以 1.2 的开销系数:$$3.5 \times 1.2 = 4.2 \text{ GB}$$这在一块 8 GB 的消费级显卡上可以轻松装下。同一个模型若改用 FP16,则需要 \(7 \times 2 \times 1.2 = 16.8\) GB,得用 24 GB 显存的显卡才行。
常见问题
结果准确吗?不完全准确——这只是一个推理场景下的估算值。实际占用会随上下文长度、批量大小以及所用推理框架而变化。它适合用来做规划,而不是精确到最后一兆字节。
这包含训练所需的显存吗?不包含。训练需要的显存要多得多(还要存优化器状态、梯度等),往往是推理数值的 4 倍甚至更多。
开销系数该选多少?短上下文推理用 1.2 就够了;长上下文或并发请求场景建议用 1.3~1.5。