
Para qué sirve esta calculadora
La Calculadora de VRAM para LLM estima cuánta memoria de GPU necesitas para cargar y ejecutar un modelo de lenguaje grande. Multiplica el número de parámetros del modelo (en miles de millones) por los bytes que ocupa cada parámetro según la precisión elegida y, después, aplica un factor de sobrecarga que tiene en cuenta las activaciones, la caché KV y los búferes del framework.
Cómo usarla
Indica el tamaño del modelo en miles de millones de parámetros (por ejemplo, 7 para un modelo de 7B o 70 para uno de 70B). Elige la cuantización: FP16/BF16 usa 2 bytes por peso, INT8 usa 1 byte, 4 bits usa 0,5 bytes y 2 bits usa 0,25 bytes. El factor de sobrecarga predeterminado de 1,2 (un margen del 20 %) es un buen punto de partida para la inferencia; auméntalo si trabajas con contextos largos o procesamiento por lotes.
La fórmula al detalle
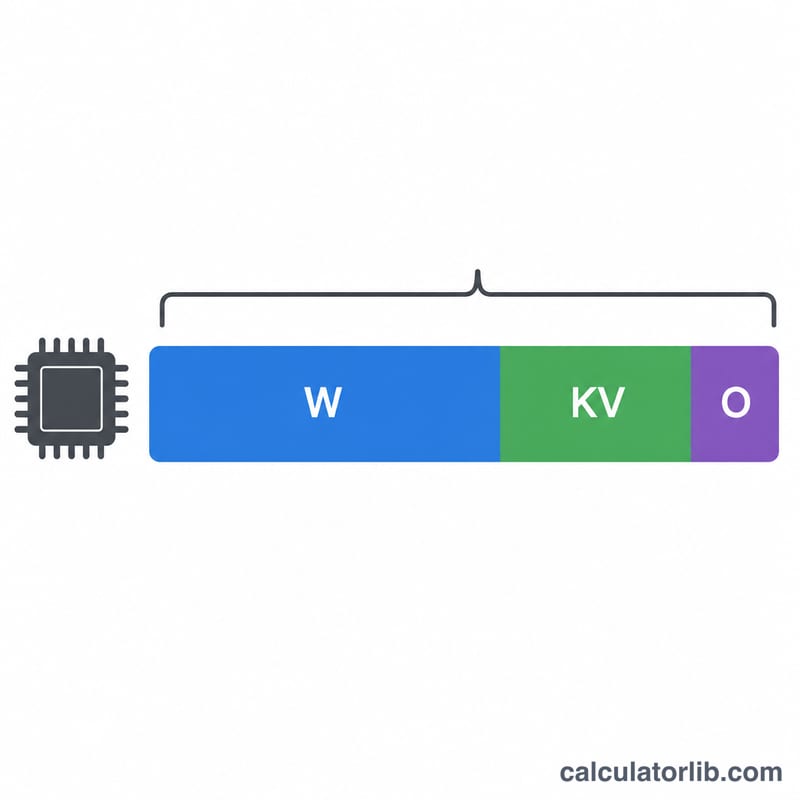
$$\text{VRAM (GB)} = \text{Par\acute{a}metros (miles de millones)} \times \text{bytes por par\acute{a}metro} \times \text{sobrecarga}$$ Los dos primeros términos dan el tamaño bruto de los pesos del modelo en gigabytes. El multiplicador de sobrecarga reserva la memoria adicional que consumen en tiempo de ejecución PyTorch, CUDA y la caché KV de atención, algo que el tamaño bruto de los pesos por sí solo no contempla.
Ejemplo práctico
Un modelo de 7B con precisión de 4 bits: \(7 \times 0{,}5 = 3{,}5\) GB de pesos. Con un factor de sobrecarga de 1,2: \(3{,}5 \times 1{,}2 = 4{,}2\) GB. Cabe holgadamente en una GPU de consumo de 8 GB. El mismo modelo en FP16 necesita \(7 \times 2 \times 1{,}2 = 16{,}8\) GB, lo que exige una tarjeta de 24 GB.
Preguntas frecuentes
¿Es un cálculo exacto? No: es una estimación para inferencia. El consumo real varía según la longitud del contexto, el tamaño del lote y el framework de servicio. Úsala para planificar, no para afinar hasta el último megabyte.
¿Incluye la memoria de entrenamiento? No. Entrenar requiere muchísimo más (estados del optimizador, gradientes), a menudo 4 veces o más la cifra de inferencia.
¿Qué sobrecarga debo usar? 1,2 es adecuado para inferencia con contexto corto; usa entre 1,3 y 1,5 para contextos largos o solicitudes simultáneas.