¿Qué es la calculadora de VRAM para un LLM?
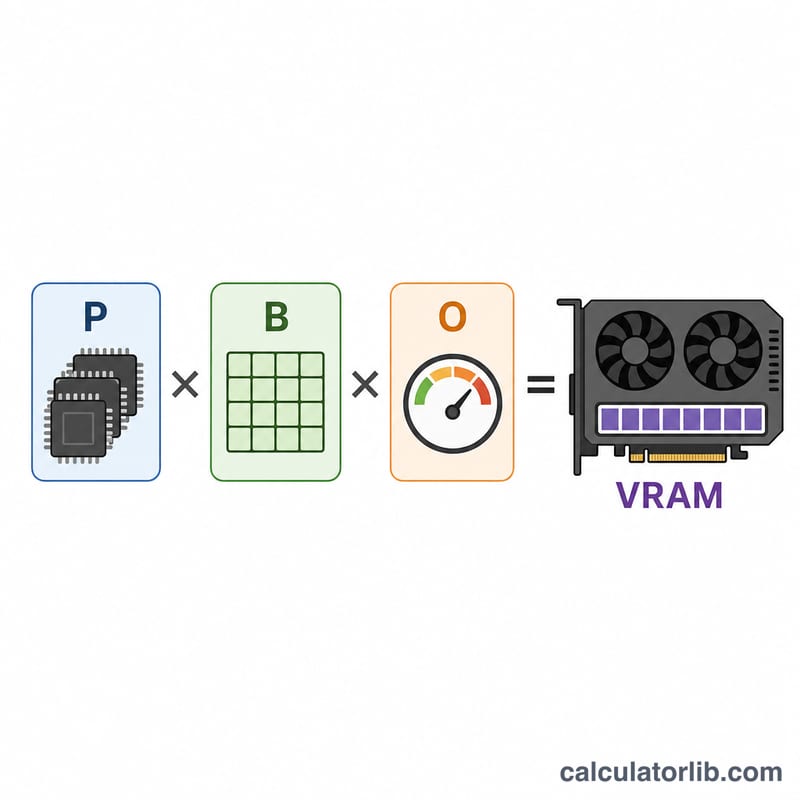
Esta herramienta estima cuánta memoria de vídeo de la GPU (VRAM) necesitas para cargar y ejecutar un modelo de lenguaje grande (LLM) durante la inferencia. La cantidad de memoria depende sobre todo del número de parámetros del modelo y de la precisión numérica con la que se almacena cada peso. Un factor de margen (o de seguridad) tiene en cuenta la caché KV, las activaciones y el contexto de CUDA, que consumen memoria más allá del peso bruto del modelo.
Cómo utilizarla
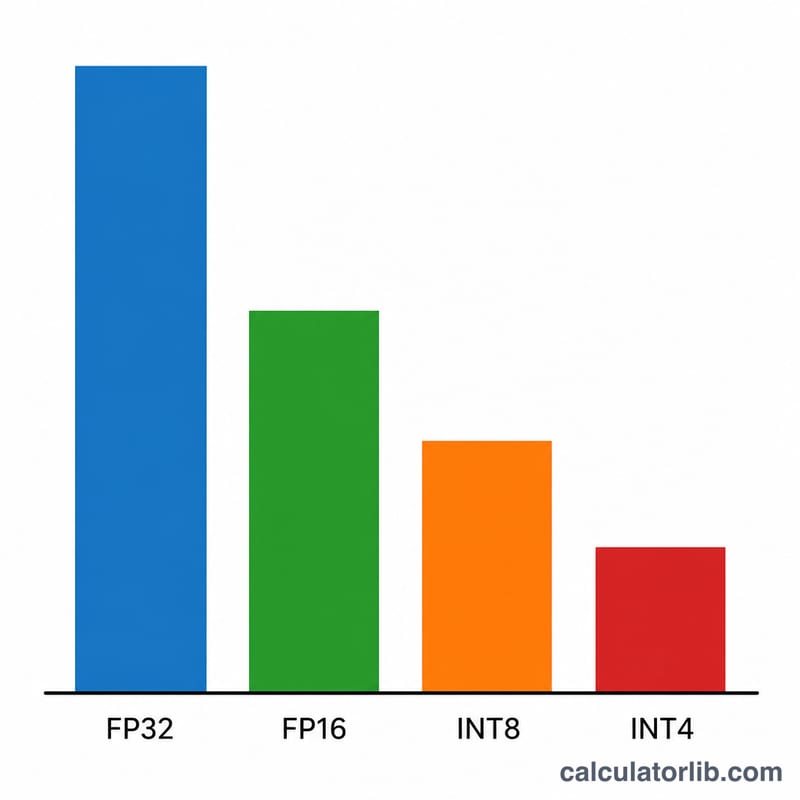
Introduce el tamaño del modelo en miles de millones de parámetros (por ejemplo, 7 para un modelo de 7B o 70 para Llama-3 70B). Elige la precisión: FP32 usa 4 bytes por peso, FP16/BF16 usa 2 bytes, INT8 usa 1 byte y la cuantización INT4 usa 0,5 bytes. Por último, ajusta el factor de margen: 1,2 (un colchón del 20 %) es un valor por defecto razonable para inferencia con contextos cortos; auméntalo si trabajas con contextos largos o por lotes (batching).
La fórmula explicada
$$\text{VRAM (GB)} = \text{Par\'ametros (miles de millones)} \times \text{Bytes por par\'ametro} \times \text{Margen}$$ Como 1000 millones de bytes ≈ 1 GB, multiplicar los parámetros en miles de millones por los bytes por parámetro da directamente el resultado en gigabytes. El factor de margen amplía después esa cifra para cubrir la memoria de ejecución.
Ejemplo práctico
Para un modelo de 7B en FP16 con un factor de margen de 1,2: $$7 \times 2 \times 1{,}2 = 16{,}8 \text{ GB}$$ Cabe sin problemas en una tarjeta de 24 GB. El mismo modelo en INT4: $$7 \times 0{,}5 \times 1{,}2 = 4{,}2 \text{ GB}$$ y se ejecuta fácilmente en una GPU de 8 GB.
Preguntas frecuentes
¿Por qué el uso real es mayor que el peso bruto del modelo? La caché KV crece con la longitud del contexto y el tamaño del lote, y el framework reserva memoria para las activaciones y los búferes: eso es lo que aproxima el factor de margen.
¿Incluye el entrenamiento? No. El entrenamiento necesita aproximadamente entre 3 y 4 veces más memoria para los estados del optimizador y los gradientes; esta estimación está pensada para la inferencia.
¿Qué margen debería usar? Usa alrededor de 1,2 para prompts cortos y entre 1,5 y 2,0 o más para contextos largos o un batching intensivo.