Что такое калькулятор требований к VRAM для LLM?
Этот инструмент помогает прикинуть, сколько видеопамяти GPU (VRAM) понадобится, чтобы загрузить и запустить большую языковую модель (LLM) в режиме инференса. Основной вес здесь имеют два фактора: количество параметров модели и точность, с которой хранится каждый вес. Дополнительно учитывается коэффициент запаса — он отражает память под KV-кэш, активации и контекст CUDA, которые «съедают» ресурсы сверх самих весов.
Как пользоваться калькулятором
Укажите размер модели в миллиардах параметров (например, 7 для модели 7B или 70 для Llama-3 70B). Выберите точность: FP32 занимает 4 байта на вес, FP16/BF16 — 2 байта, INT8 — 1 байт, а квантизация INT4 — всего 0,5 байта. Наконец, задайте коэффициент запаса: значение 1,2 (запас 20%) — разумный вариант по умолчанию для инференса с коротким контекстом, а для длинных контекстов или батчинга его стоит увеличить.
Разбор формулы
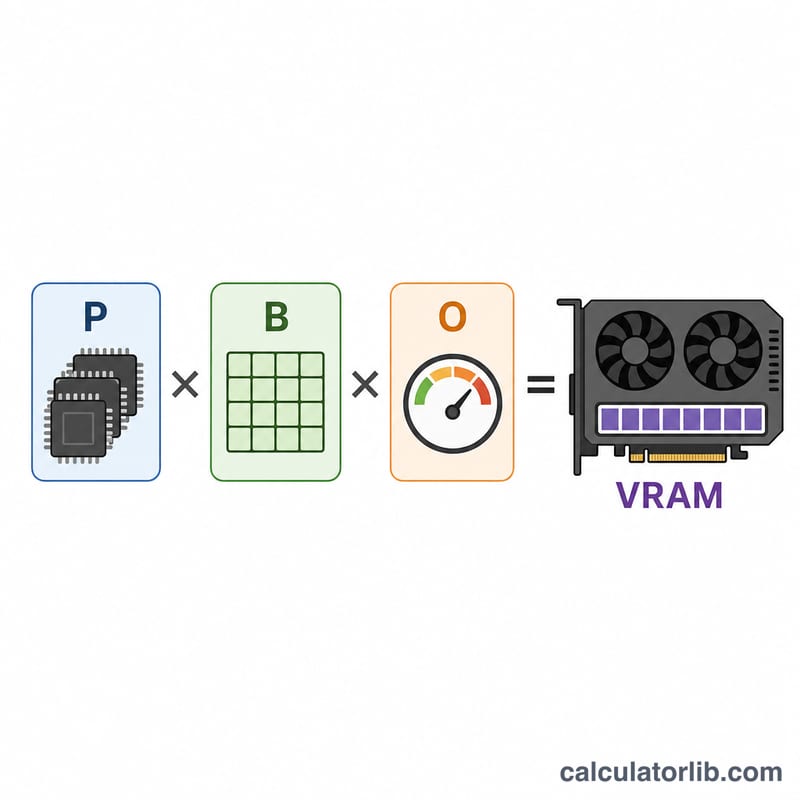
$$\text{VRAM (ГБ)} = \text{Параметры (млрд)} \times \text{Байт на параметр} \times \text{Коэффициент запаса}$$ Поскольку 1 миллиард байт ≈ 1 ГБ, умножение количества параметров в миллиардах на число байт на параметр сразу даёт результат в гигабайтах. Коэффициент запаса затем увеличивает эту цифру, чтобы покрыть память, расходуемую во время работы.
Пример расчёта
Для модели 7B в формате FP16 с коэффициентом запаса 1,2: $$7 \times 2 \times 1{,}2 = 16{,}8 \text{ ГБ}$$ Это спокойно помещается на карте с 24 ГБ. Та же модель в INT4: $$7 \times 0{,}5 \times 1{,}2 = 4{,}2 \text{ ГБ}$$ — легко работает даже на видеокарте с 8 ГБ.
Частые вопросы
Почему реальное потребление выше, чем вес самих весов? KV-кэш растёт вместе с длиной контекста и размером батча, а фреймворк резервирует память под активации и буферы — именно это и учитывает коэффициент запаса.
Учитывает ли расчёт обучение? Нет. Для обучения нужно примерно в 3–4 раза больше памяти под состояния оптимизатора и градиенты; эта оценка рассчитана на инференс.
Какой коэффициент запаса выбрать? Используйте около 1,2 для коротких запросов и 1,5–2,0 и выше — для длинных контекстов или интенсивного батчинга.