什么是 Token 转字数计算器?
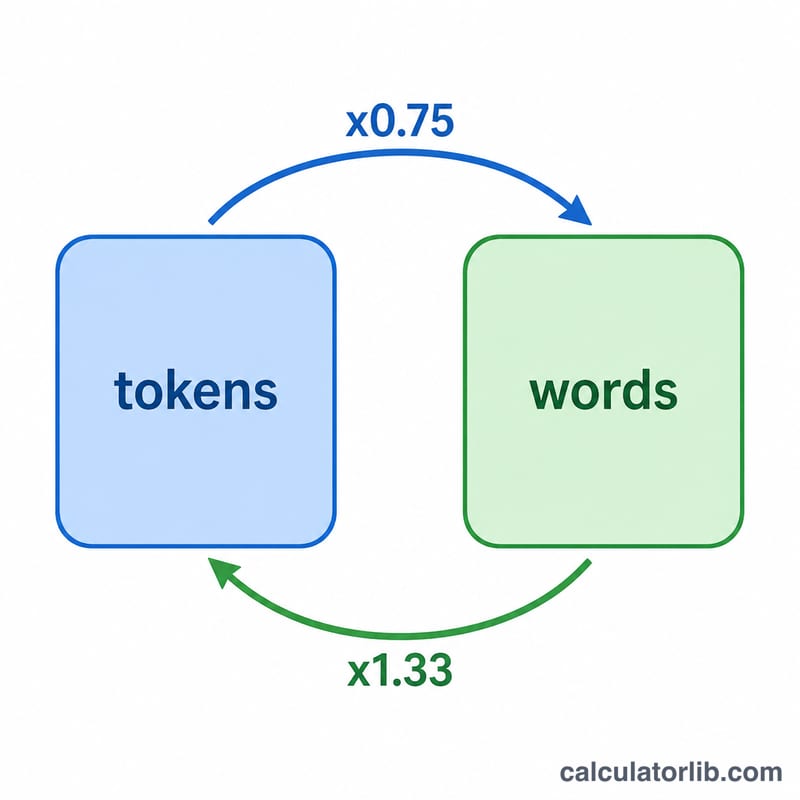
GPT、Claude、Gemini 等大语言模型(LLM)并不是逐字阅读文本,而是把文本拆成一个个 Token 来处理。一个 Token 可以是一个完整的单词、一个单词的一部分,甚至是一个标点符号。对于常见的英文文本而言,一个 Token 大约对应 0.75 个英文单词(换算下来约为每个单词 1.33 个 Token)。本计算器可以把 Token 数量换算成大致的字数,也可以把字数换算成它大概会消耗多少 Token。需要注意的是,这套比例主要基于英文,中文等其他语言的分词方式不同,实际 Token 用量往往更高。
使用方法
先选择换算方向——Token 转字数 或 字数转 Token,输入数量,并可按需调整 每 Token 词数 比例(默认 0.75)。工具会立即给出换算结果以及所使用的比例。如果处理的是代码或非英文文本(通常会占用更多 Token),可以把比例调低;如果是简单、重复的英文内容,则可适当调高。
公式解析
换算本质上就是一个简单的比例关系。由 Token 估算字数:
$$\text{字数} = \text{Token 数} \times \text{比例}$$由字数估算 Token:
$$\text{Token 数} = \frac{\text{字数}}{\text{比例}}$$以默认比例 0.75 计算,1,000 个 Token ≈ 750 个词,1,000 个词 ≈ 1,333 个 Token。这些都只是估算值——真实的分词结果会因模型、语言和内容而异。
实例演示
假设某次 API 调用显示用掉了 1,000 个 Token。按默认比例计算:
$$1000 \times 0.75 = 750 \text{ 词}$$反过来,如果你写了一篇 1,500 词的文章,想知道它大概要消耗多少 Token:
$$1500 \div 0.75 = 2{,}000 \text{ 个 Token}$$——这对于控制在模型上下文窗口范围内、或者预估 API 费用都很有帮助。
常见问题
每 Token 0.75 词这个比例总是准确吗? 不一定——它是针对英文的常用经验法则。代码、数字以及其他语言往往每个词要占用更多 Token,因此遇到这些情况建议把比例调低。
为什么 Token 这么重要? 大模型的计费和上下文长度限制都是按 Token(而不是字数)来计算的,因此换算有助于你预估成本和判断内容是否放得下。
怎样才能得到精确数值? 请使用模型官方的分词器(例如 OpenAI 的 tiktoken)。本计算器提供的是快速近似值,并非精确计数。