मानक त्रुटि क्या है?
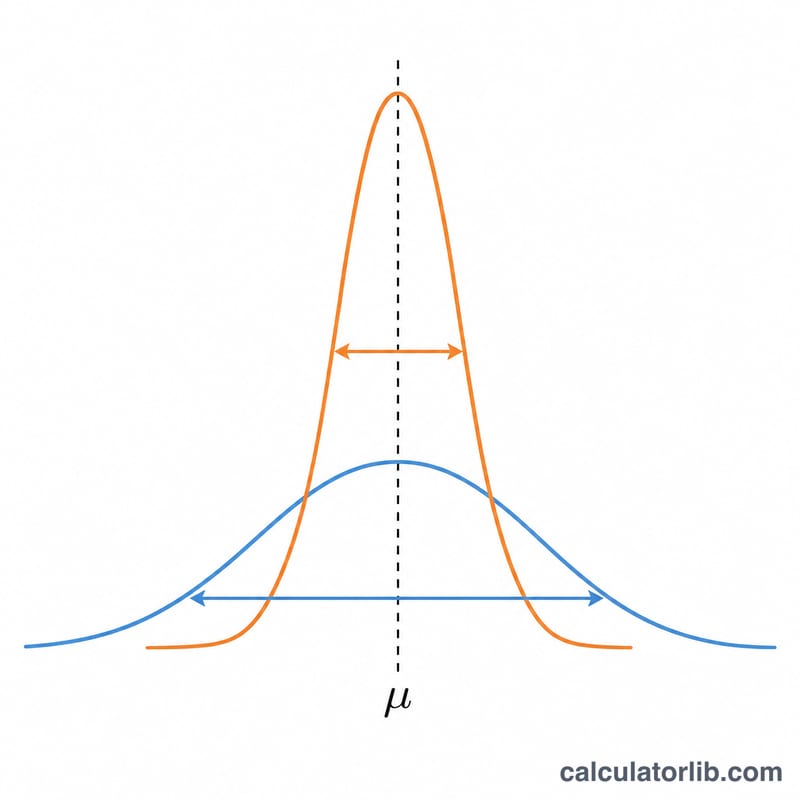
माध्य की मानक त्रुटि (SEM, या संक्षेप में SE) यह बताती है कि किसी नमूने का माध्य वास्तविक जनसंख्या माध्य से कितना अलग होने की संभावना रखता है। जहाँ मानक विचलन अलग-अलग आँकड़ों के फैलाव को दर्शाता है, वहीं मानक त्रुटि आपके अनुमानित औसत की सटीकता को दर्शाती है। मानक त्रुटि जितनी कम होगी, आपका नमूना माध्य जनसंख्या माध्य का उतना ही भरोसेमंद अनुमान माना जाएगा।
इस कैलकुलेटर का उपयोग कैसे करें
बस दो मान दर्ज करें: नमूना मानक विचलन (s) और नमूना आकार (n)। कैलकुलेटर मानक विचलन को नमूना आकार के वर्गमूल से विभाजित करता है और तुरंत माध्य की मानक त्रुटि दिखा देता है। जब भी आप विश्वास अंतराल बनाएँ, परिकल्पना परीक्षण करें, या त्रुटि की सीमा (margin of error) बताएँ, तब इसका इस्तेमाल करें।
सूत्र को समझें
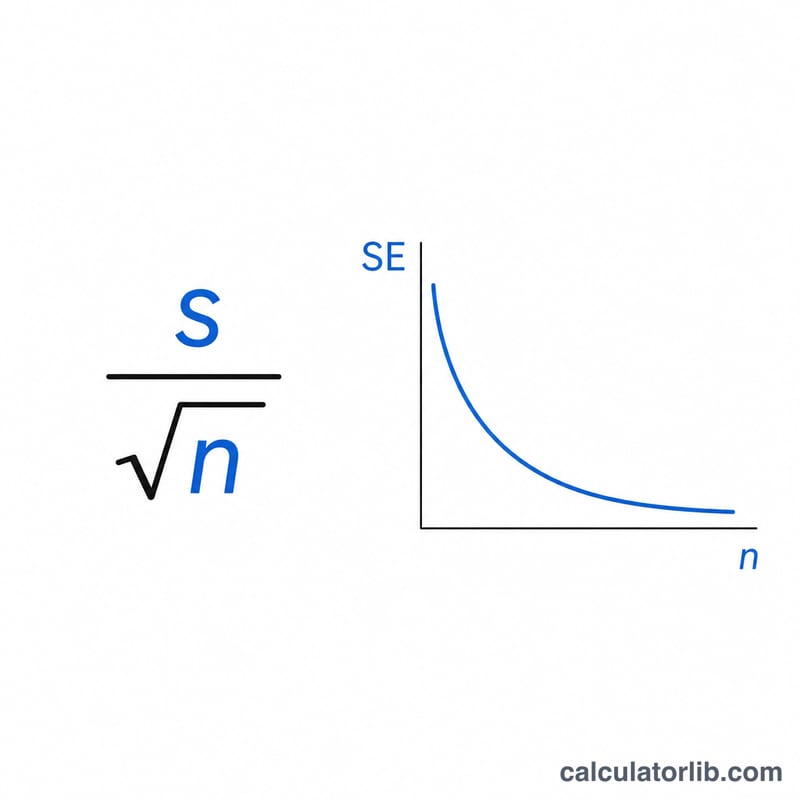
मानक त्रुटि की गणना $$\text{SE} = \frac{s}{\sqrt{n}}$$ से होती है। यहाँ हर (denominator) में मौजूद \(n\) का वर्गमूल ही असली कुंजी है: जैसे-जैसे आपका नमूना आकार बढ़ता है, वर्गमूल धीमी गति से बढ़ता है, इसलिए मानक त्रुटि घटती जाती है। मानक त्रुटि को आधा करने के लिए आपको चार गुना अधिक आँकड़े इकट्ठा करने पड़ते हैं। यही वजह है कि बड़े नमूने जनसंख्या माध्य का अधिक सटीक अनुमान देते हैं।
हल किया हुआ उदाहरण
मान लीजिए 25 मापों वाले एक नमूने का मानक विचलन 10 है। तब $$\text{SE} = \frac{10}{\sqrt{25}} = \frac{10}{5} = 2$$ यानी नमूना माध्य के वास्तविक जनसंख्या माध्य से लगभग 2 इकाई तक अलग होने की संभावना है। अगर आप नमूने को बढ़ाकर 100 कर दें, तो SE घटकर \(\frac{10}{10} = 1\) हो जाएगी, जिससे सटीकता दोगुनी हो जाएगी।
अक्सर पूछे जाने वाले सवाल
मानक विचलन और मानक त्रुटि में क्या अंतर है? मानक विचलन अलग-अलग आँकड़ों के बीच की परिवर्तनशीलता को मापता है; जबकि मानक त्रुटि यह मापती है कि नमूना माध्य, जनसंख्या माध्य के अनुमान के रूप में कितना बदल सकता है।
क्या नमूना आकार बढ़ने पर मानक त्रुटि घटती है? हाँ। चूँकि हर में \(n\) वर्गमूल के नीचे आता है, इसलिए नमूना आकार बढ़ाने से मानक त्रुटि कम हो जाती है।
क्या मैं इसे अनुपात (proportions) के लिए इस्तेमाल कर सकता हूँ? यह कैलकुलेटर माध्य की मानक त्रुटि के लिए है। अनुपात की मानक त्रुटि के लिए एक अलग सूत्र \(\sqrt{\frac{p(1-p)}{n}}\) का उपयोग किया जाता है।