यह क्या है
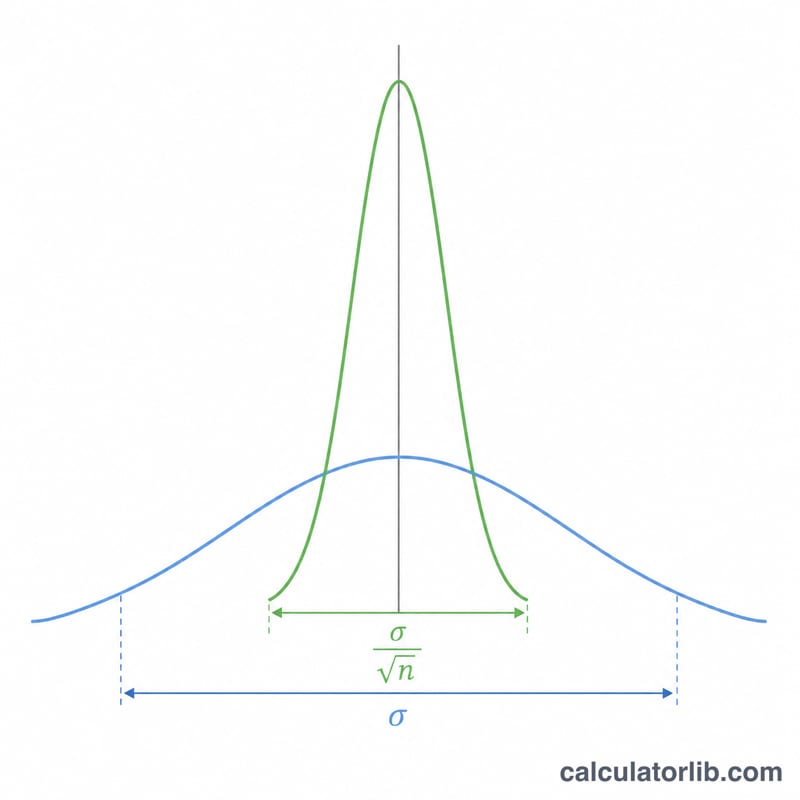
सैंपल माध्य के मानक विचलन को आमतौर पर माध्य की मानक त्रुटि (Standard Error of the Mean, SEM) कहा जाता है। यह बताता है कि किसी यादृच्छिक (random) सैंपल का औसत, असली जनसंख्या माध्य से कितना भटक सकता है। जहाँ जनसंख्या मानक विचलन \(\sigma\) अलग-अलग डेटा बिंदुओं के फैलाव को दर्शाता है, वहीं मानक त्रुटि सैंपल माध्यों के फैलाव को मापती है। आप जितने ज़्यादा प्रेक्षण (observations) इकट्ठा करेंगे, आपके सैंपल के औसत उतने ही पास-पास जनसंख्या माध्य के आसपास सिमट जाएँगे।
कैलकुलेटर का उपयोग कैसे करें
जनसंख्या मानक विचलन (\(\sigma\)) और सैंपल साइज़ (\(n\)) दर्ज करें। कैलकुलेटर \(\sigma\) को \(n\) के वर्गमूल से भाग देकर मानक त्रुटि निकाल देता है। इस परिणाम का उपयोग आत्मविश्वास अंतराल (confidence interval) बनाने, परिकल्पना परीक्षण (hypothesis test) करने, या किसी अनुमानित माध्य की विश्वसनीयता आँकने के लिए करें।
सूत्र की व्याख्या
इनके बीच संबंध यह है:
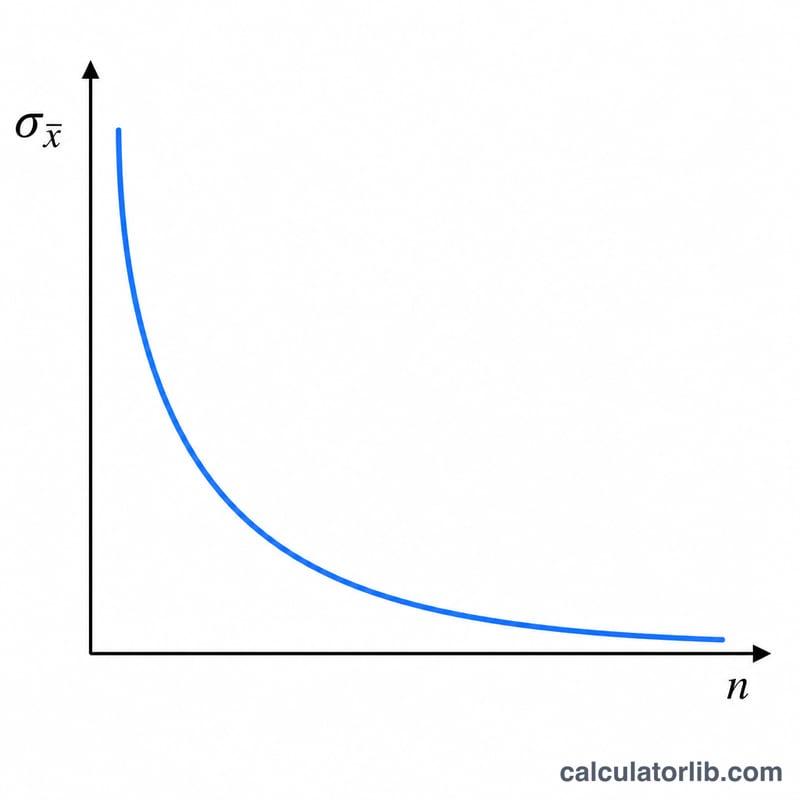
$$\sigma_{\bar{x}} = \frac{\sigma}{\sqrt{n}}$$चूँकि \(n\) वर्गमूल के नीचे होता है, इसलिए मानक त्रुटि को आधा करने के लिए सैंपल साइज़ को चार गुना बढ़ाना पड़ता है। यह "घटते प्रतिफल" (diminishing returns) वाला गुण अध्ययन की रूपरेखा (study design) का अहम हिस्सा है — सटीकता में बड़ा सुधार हासिल करना उत्तरोत्तर महँगा होता जाता है।
हल किया हुआ उदाहरण
मान लीजिए किसी जनसंख्या का मानक विचलन \(\sigma = 10\) है और आप \(n = 25\) प्रेक्षणों का सैंपल लेते हैं। तब $$\sigma_{\bar{x}} = \frac{10}{\sqrt{25}} = \frac{10}{5} = 2$$ यानी सैंपल माध्य आम तौर पर असली जनसंख्या माध्य के आसपास लगभग 2 इकाई तक घटते-बढ़ते रहेंगे।
अक्सर पूछे जाने वाले सवाल
\(\sigma\) और मानक त्रुटि में क्या फ़र्क है? \(\sigma\) अलग-अलग मानों की परिवर्तनशीलता दर्शाता है; जबकि मानक त्रुटि सैंपल माध्य की परिवर्तनशीलता दर्शाती है, और (\(n > 1\) के लिए) यह हमेशा \(\sigma\) से छोटी होती है।
अगर मेरे पास सिर्फ़ सैंपल मानक विचलन s हो तो? \(\sigma\) की जगह \(s\) का उपयोग करके अनुमानित मानक त्रुटि \(s / \sqrt{n}\) निकालें। सूत्र बिल्कुल वही रहता है।
\(\sqrt{n}\) से भाग क्यों, \(n\) से क्यों नहीं? सैंपल माध्य का प्रसरण (variance) \(\sigma^2/n\) के बराबर होता है; इसका वर्गमूल लेकर मानक-विचलन इकाइयों में वापस आने पर \(\sigma/\sqrt{n}\) मिलता है।