यह कैलकुलेटर क्या करता है
यह टूल किसी सैंपल के माध्य (μ) और मानक विचलन (σ) के आधार पर उस रेंज का अनुमान लगाता है जिसमें "वास्तविक मान" के होने की सबसे अधिक संभावना है। यह मानकर चलता है कि संबंधित राशि सामान्य वितरण (normal distribution) का पालन करती है, और सममित दोतरफा अंतराल \(\mu \pm z\cdot\sigma\) देता है, जहाँ \(z\) आपके चुने हुए विश्वास स्तर के लिए मानक-सामान्य क्रांतिक मान (critical value) होता है। माध्य और मानक विचलन सामान्य संख्याएँ हैं, और अंतराल उन्हीं इकाइयों में मिलता है जो आपने दी थीं।
इसका उपयोग कैसे करें
अपना माध्य, अपना मानक विचलन (जो 0 या उससे अधिक होना चाहिए), और विश्वास स्तर प्रतिशत में दर्ज करें, जहाँ 50 < विश्वास < 100 हो (आमतौर पर 95)। कैलकुलेटर प्रतिशत को प्रायिकता \(p\) में बदलता है, क्रांतिक मान \(z = \Phi^{-1}\!\left(\frac{1+p}{2}\right)\) निकालता है, और निचली व ऊपरी सीमा लौटाता है। 100% पर अंतराल अनंत हो जाएगा, इसलिए विश्वास स्तर 100 से कम ही रहना चाहिए।
सूत्र की व्याख्या
प्रायिकता \(p = \text{विश्वास}/100\) के लिए, दोतरफा \(z\) मान \((1+p)/2\) पर मानक सामान्य क्वांटाइल होता है। 95% के लिए यह \(\Phi^{-1}(0.975) \approx 1.95996\) है, इसलिए अंतराल \(\mu \pm 1.96\sigma\) बनता है। याद रखने योग्य कुछ मुख्य बिंदु: 68.26% कवरेज का मतलब \(\mu \pm 1\sigma\), 95.45% का मतलब \(\mu \pm 2\sigma\), और 99.73% का मतलब \(\mu \pm 3\sigma\) होता है। व्युत्क्रम सामान्य CDF की गणना एक रैशनल (Acklam) सन्निकटन और उसके बाद Halley परिशोधन चरण से की जाती है, इसलिए किसी लुकअप टेबल की ज़रूरत नहीं पड़ती।
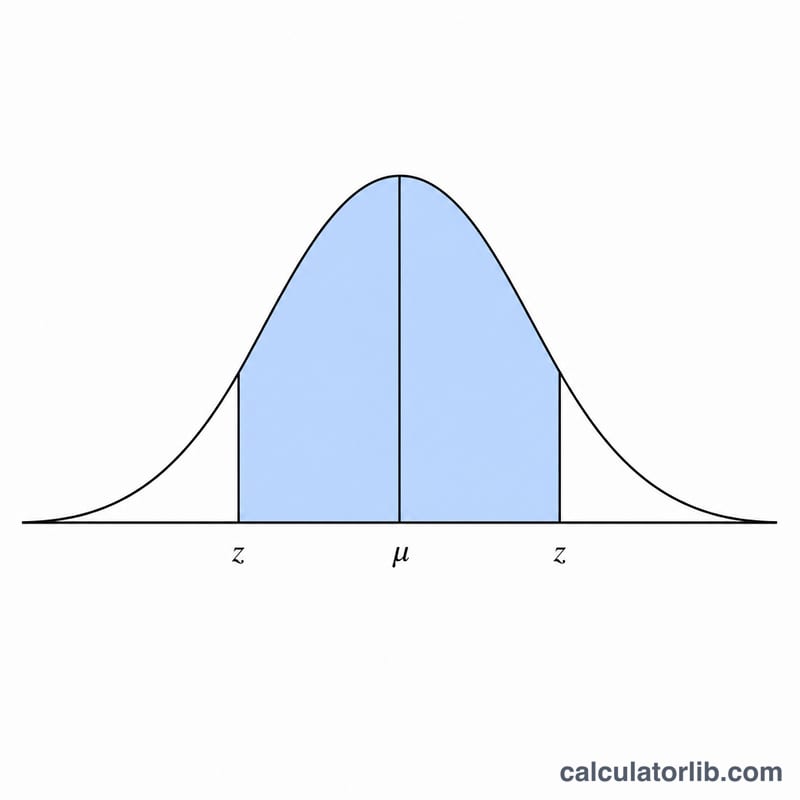
हल किया हुआ उदाहरण
मान लीजिए माध्य = 100, sd = 5 और विश्वास = 99%: तब \(p = 0.99\), \(z = \Phi^{-1}(0.995) \approx 2.57583\)। $$\text{निचली सीमा} = 100 - 2.57583\cdot 5 = 87.121$$ $$\text{ऊपरी सीमा} = 100 + 12.879 = 112.879$$ परिणाम दिखेगा "87.12 और 112.88 के बीच"।
अक्सर पूछे जाने वाले सवाल
95% के लिए 1.96 क्यों, 1.645 क्यों नहीं? एक सममित दोतरफा अंतराल बचे हुए 5% को 2.5% की दो पूँछों में बाँटता है, जिससे \(\Phi^{-1}(0.975) \approx 1.96\) मिलता है। 1.645 तो एकतरफा 95% क्वांटाइल है और दोतरफा रेंज के लिए सही नहीं है।
क्या मुझे इसके बजाय t-वितरण इस्तेमाल करना चाहिए? जब \(\sigma\) का अनुमान किसी छोटे सैंपल से लगाया गया हो, तो सैंपल आकार \(n\) वाला t-वितरण (अंतराल \(\mu \pm t\cdot s/\sqrt{n}\)) अधिक उपयुक्त होता है। यह टूल जानबूझकर \(\sigma\) को एक ज्ञात जनसंख्या मान मानता है और सामान्य \(z\) का उपयोग करता है, इसलिए इसमें \(n\) की ज़रूरत नहीं पड़ती।
अगर sd = 0 हो तो क्या होगा? तब अंतराल सिकुड़कर एक ही बिंदु \([\text{माध्य}, \text{माध्य}]\) रह जाता है।