這個計算器能做什麼
本工具會在已知樣本平均數(\(\mu\))與標準差(\(\sigma\))的情況下,估計「真值」可能落在的範圍。它假設該數值服從常態分布(normal distribution),並回傳對稱的雙尾區間 \(\mu \pm z\cdot\sigma\),其中 \(z\) 是你所選信賴水準對應的標準常態臨界值。平均數與標準差皆為一般數字,計算出的區間也會以你輸入的相同單位呈現。
使用方式
請輸入平均數、標準差(必須大於或等於 0),以及以百分比表示的信賴水準,範圍須符合 50 < 信賴水準 < 100(最常用的是 95)。計算器會先把百分比換算成機率 \(p\),求出臨界值 \(z = \Phi^{-1}\!\left(\frac{1+p}{2}\right)\),再回傳區間的下限與上限。當信賴水準為 100% 時區間會變成無限大,因此數值必須維持在 100 以下。
公式說明
令機率 \(p = \text{信賴水準}/100\),雙尾的 \(z\) 值即為標準常態分布在 \((1+p)/2\) 處的分位數。$$\text{CI} = \text{Mean }\mu \pm z \cdot \text{SD }\sigma$$ $$\text{where}\quad z = \Phi^{-1}\!\left(\frac{1 + \frac{\text{Confidence }\%}{100}}{2}\right)$$ 以 95% 為例,\(\Phi^{-1}(0.975) \approx 1.95996\),因此區間為 \(\mu \pm 1.96\sigma\)。幾個實用的對照點:68.26% 的覆蓋率相當於 \(\mu \pm 1\sigma\)、95.45% 相當於 \(\mu \pm 2\sigma\)、99.73% 則相當於 \(\mu \pm 3\sigma\)。反常態累積分布函數採用有理式(Acklam)近似法,再加上一次 Halley 修正步驟計算,因此完全不需要查表。
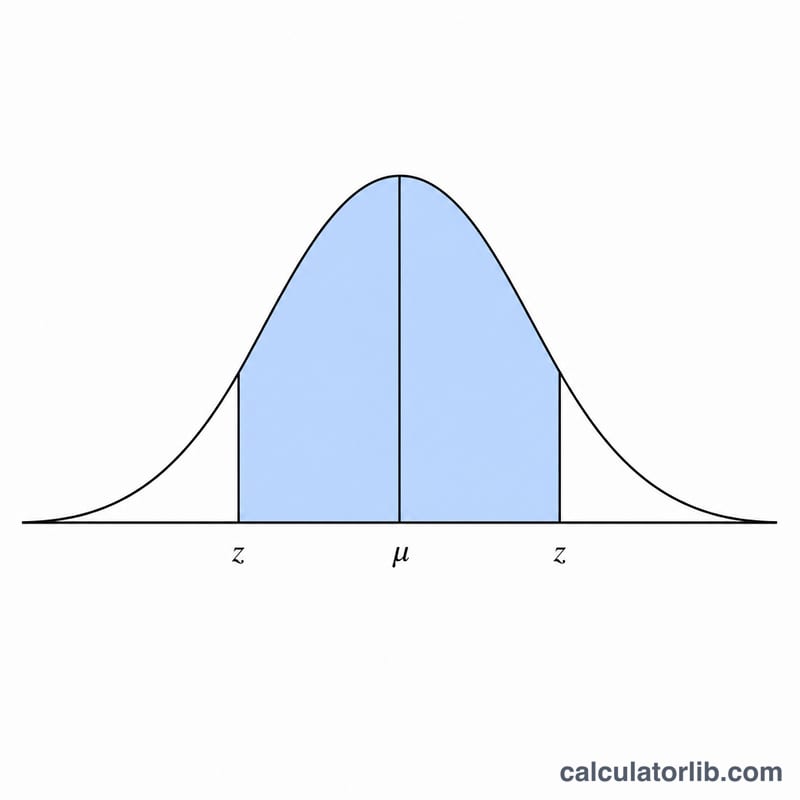
實例演算
假設平均數 = 100、標準差 = 5、信賴水準 = 99%:\(p = 0.99\),\(z = \Phi^{-1}(0.995) \approx 2.57583\)。$$\text{下限} = 100 - 2.57583\cdot 5 = 87.121$$ $$\text{上限} = 100 + 12.879 = 112.879$$ 結果即顯示為「介於 87.12 與 112.88 之間」。
常見問題
為什麼 95% 用的是 1.96,而不是 1.645?對稱的雙尾區間會把剩下的 5% 平分成兩條各 2.5% 的尾端,因此取 \(\Phi^{-1}(0.975) \approx 1.96\)。而 1.645 是單尾 95% 的分位數,用在雙尾範圍上並不正確。
我是不是該改用 t 分布?當 \(\sigma\) 是由小樣本估計而來時,使用自由度與樣本數 \(n\) 相關的 t 分布(區間為 \(\text{平均數} \pm t\cdot s/\sqrt{n}\))會更恰當。本工具刻意將 \(\sigma\) 視為已知的母體參數,並採用常態分布的 \(z\) 值,因此不需要輸入 \(n\)。
如果標準差 = 0 呢?此時區間會收縮成單一一點 \([\text{平均數}, \text{平均數}]\)。