这个计算器的用途
给定一个样本均值(\(\mu\))和一个标准差(\(\sigma\)),本工具可以估算"真值"很可能落在的区间。它假设该变量服从正态分布,并给出对称的双侧区间 \(\mu \pm z\cdot\sigma\),其中 \(z\) 是你所选置信水平对应的标准正态临界值。均值和标准差都是普通数值,计算得到的区间会沿用你输入数据的单位。
如何使用
依次填入均值、标准差(须大于或等于 0),以及以百分比表示的置信水平,取值范围为 50 < 置信水平 < 100(常用 95)。计算器会先把百分比转换为概率 \(p\),再求出临界值 \(z = \Phi^{-1}\!\left(\frac{1+p}{2}\right)\),最后给出区间的下限和上限。当置信水平为 100% 时区间会变成无穷大,因此置信水平必须小于 100。
公式详解
令概率 \(p = \text{置信水平}/100\),则双侧 \(z\) 值就是标准正态分布在 \(\frac{1+p}{2}\) 处的分位数。以 95% 为例,\(\Phi^{-1}(0.975) \approx 1.95996\),因此区间为 \(\mu \pm 1.96\sigma\)。几个常见的参考点:68.26% 覆盖率对应 \(\mu \pm 1\sigma\),95.45% 对应 \(\mu \pm 2\sigma\),99.73% 对应 \(\mu \pm 3\sigma\)。正态分布的逆累积分布函数采用有理式(Acklam)近似,并加上一步 Halley 迭代修正,因此无需查表即可计算。
$$\text{CI} = \text{Mean }\mu \pm z \cdot \text{SD }\sigma \\[1.5em] \text{where}\quad z = \Phi^{-1}\!\left(\frac{1 + \frac{\text{Confidence }\%}{100}}{2}\right)$$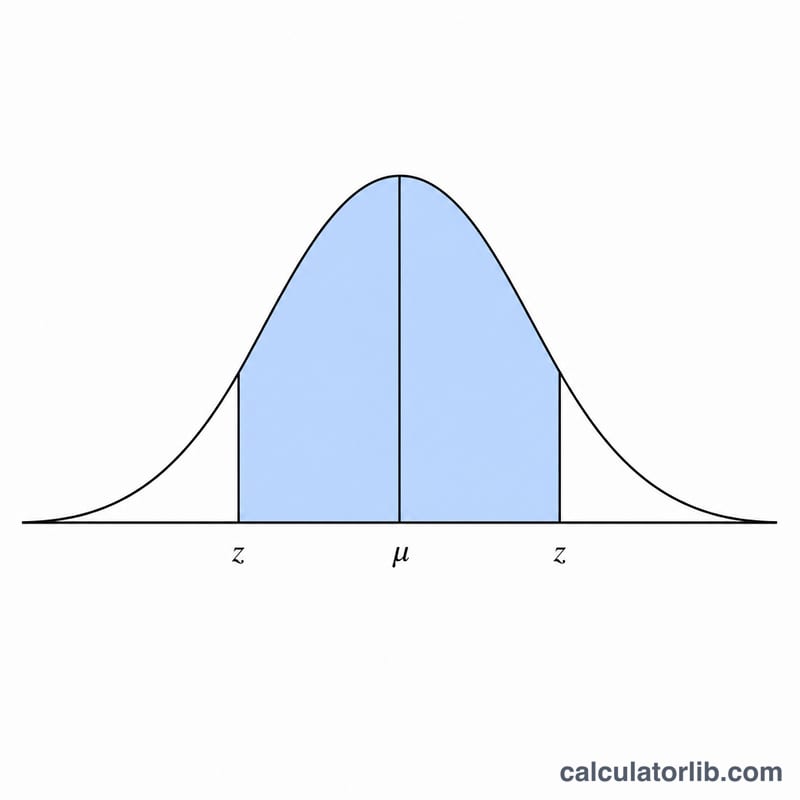
实例演算
设均值 = 100,标准差 = 5,置信水平 = 99%:此时 \(p = 0.99\),\(z = \Phi^{-1}(0.995) \approx 2.57583\)。
$$\text{下限} = 100 - 2.57583\cdot 5 = 87.121$$$$\text{上限} = 100 + 12.879 = 112.879$$结果显示为"介于 87.12 与 112.88 之间"。
常见问题
为什么 95% 用的是 1.96,而不是 1.645?对称的双侧区间会把剩下的 5% 平均分到两端,每端 2.5%,于是对应 \(\Phi^{-1}(0.975) \approx 1.96\)。而 1.645 是单侧 95% 的分位数,用在双侧区间上并不正确。
我是不是应该改用 t 分布?如果 \(\sigma\) 是从小样本中估计出来的,那么用自由度与样本量 \(n\) 相关的 t 分布(区间为 \(\text{均值} \pm t\cdot s/\sqrt{n}\))会更合适。本工具有意把 \(\sigma\) 视为已知的总体值,使用正态分布的 \(z\),因此不需要输入 \(n\)。
如果标准差为 0 怎么办?这时区间会退化为一个点 \([\text{均值}, \text{均值}]\)。