什麼是樣本平均數標準差
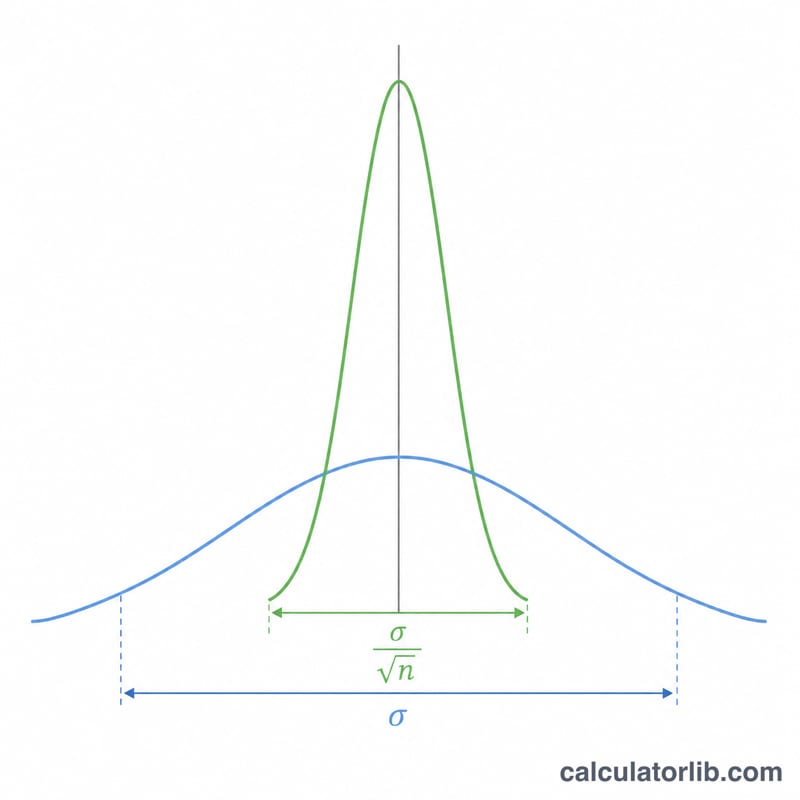
樣本平均數的標準差,更常見的名稱是平均數的標準誤(standard error of the mean,簡稱 SEM),用來衡量隨機樣本的平均數預期會偏離真正母體平均數多少。母體標準差 \(\sigma\) 描述的是個別資料點的分散程度,而標準誤描述的則是樣本平均數的分散程度。蒐集的觀測值越多,樣本平均數就會越緊密地聚集在母體平均數附近。
如何使用本計算器
輸入母體標準差(\(\sigma\))與樣本數(\(n\)),計算器會將 \(\sigma\) 除以 \(n\) 的平方根,得出標準誤。你可以用這個結果來建立信賴區間、進行假設檢定,或判斷一個估計平均數有多可靠。
公式解析
兩者的關係為:
$$\sigma_{\bar{x}} = \frac{\sigma}{\sqrt{n}}$$由於 \(n\) 位於平方根之下,若想把標準誤縮小一半,樣本數就必須擴大為原本的四倍。這種「邊際效益遞減」的特性是研究設計的核心:精準度每提升一級,所需付出的成本都會越來越高。
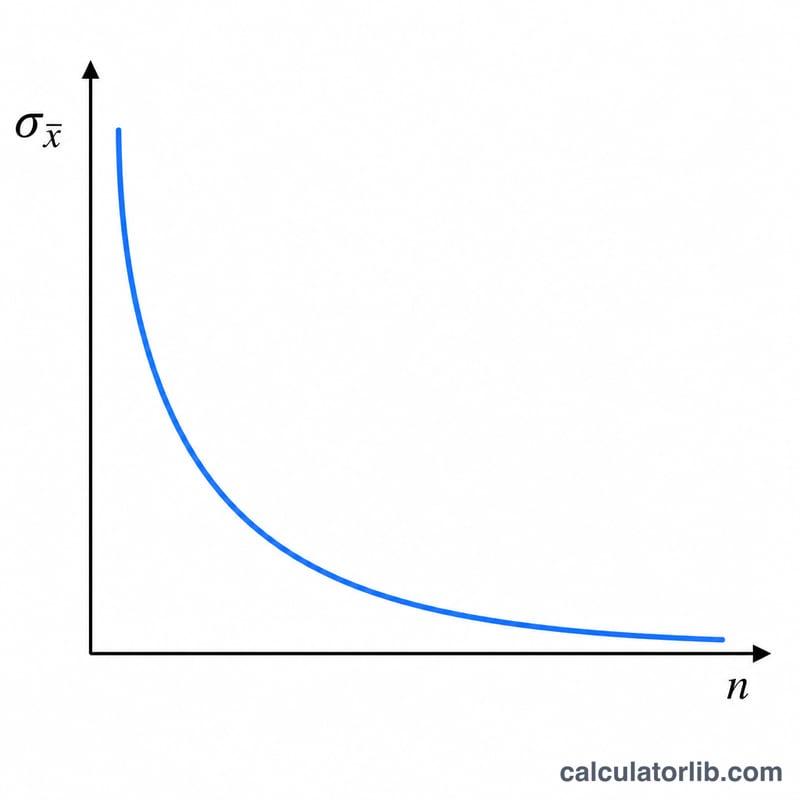
實例演算
假設某母體的標準差 \(\sigma = 10\),而你抽取了 \(n = 25\) 個觀測值的樣本,則 $$\sigma_{\bar{x}} = \frac{10}{\sqrt{25}} = \frac{10}{5} = 2$$ 也就是說,樣本平均數通常會在真正母體平均數上下約 2 個單位的範圍內波動。
常見問題
\(\sigma\) 和標準誤有什麼差別?\(\sigma\) 描述的是個別數值的變異程度;標準誤描述的則是樣本平均數的變異程度,而且當 \(n > 1\) 時,標準誤一定會比 \(\sigma\) 小。
如果我手上只有樣本標準差 \(s\) 怎麼辦?直接用 \(s\) 取代 \(\sigma\),即可得到估計的標準誤 \(s / \sqrt{n}\),公式完全相同。
為什麼是除以 \(\sqrt{n}\),而不是除以 \(n\)?因為樣本平均數的變異數等於 \(\sigma^2/n\);要回到「標準差」的單位,就必須取平方根,因此得到 \(\sigma/\sqrt{n}\)。