什么是样本均值标准差
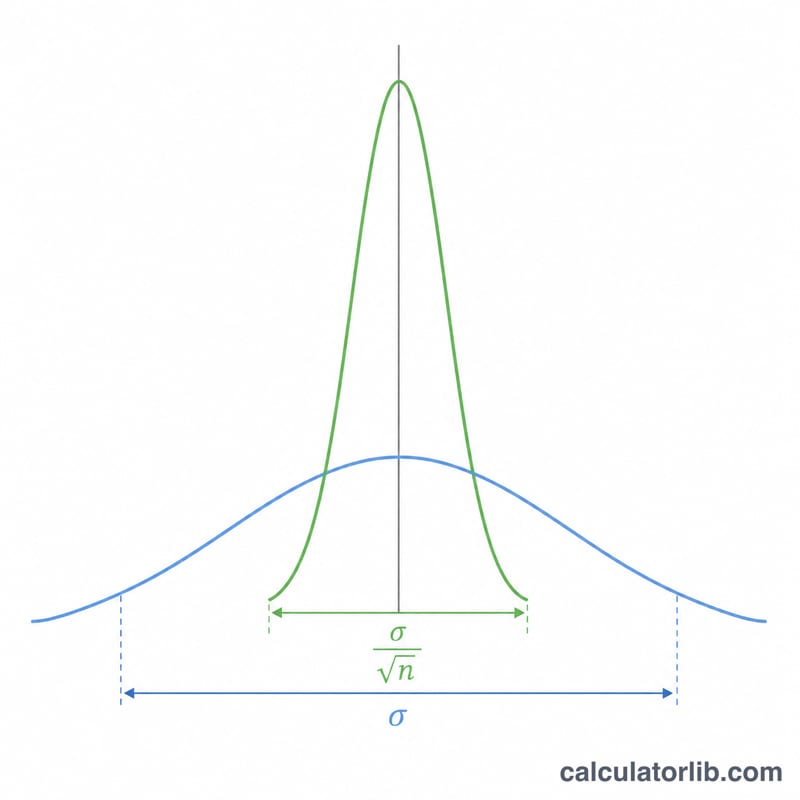
样本均值的标准差,更常见的叫法是均值标准误(SEM,Standard Error of the Mean),用来衡量一份随机样本的平均值与真实总体均值之间预期会有多大偏差。总体标准差σ描述的是单个数据点的离散程度,而标准误描述的则是样本均值的离散程度。采集的观测值越多,各次抽样得到的平均值就越紧密地聚集在总体均值附近。
如何使用本计算器
输入总体标准差(σ)和样本量(n),计算器会用σ除以n的平方根,得出标准误。你可以用这个结果来构建置信区间、进行假设检验,或判断一个估计出来的均值到底有多可靠。
公式详解
两者之间的关系为:
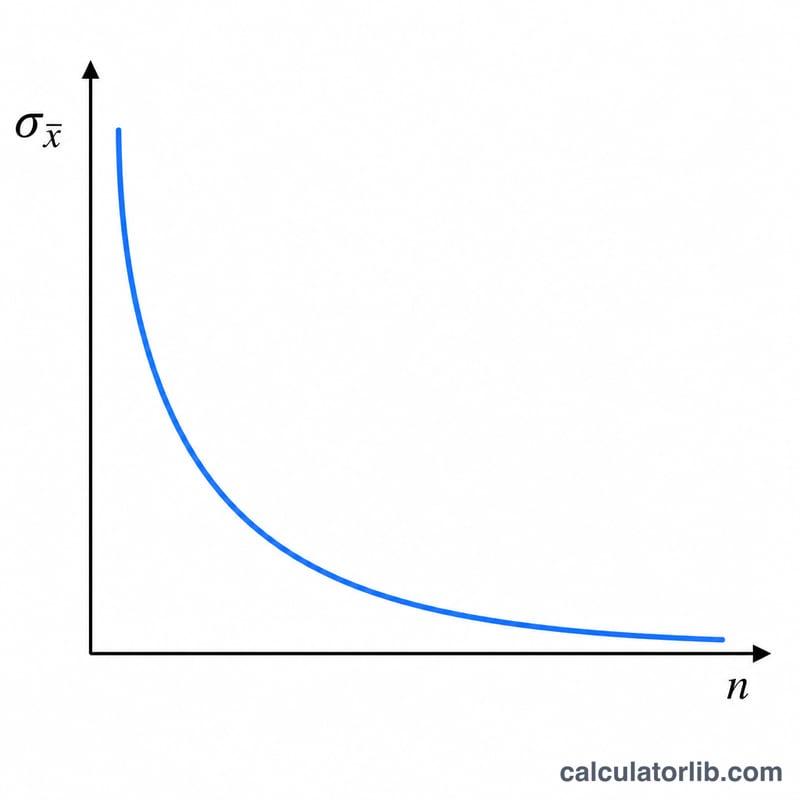
$$\sigma_{\bar{x}} = \frac{\text{Population SD } (\sigma)}{\sqrt{\text{Sample size } (n)}}$$由于n位于平方根之下,想把标准误缩小一半,样本量就得扩大到原来的四倍。这种「边际收益递减」的特性是研究设计中的核心考量:精度每提升一档,所需的成本都会越来越高。
Advertisement
实例演算
假设某总体的标准差σ = 10,你抽取了n = 25个观测值组成样本。那么
$$\sigma_{\bar{x}} = \frac{10}{\sqrt{25}} = \frac{10}{5} = 2$$也就是说,样本均值通常会在真实总体均值上下波动约2个单位。
常见问题
σ和标准误有什么区别?σ描述的是单个数值的波动程度;标准误描述的是样本均值的波动程度。当n > 1时,标准误总是小于σ。
如果我只有样本标准差s该怎么办?直接用s代替σ即可,得到估计的标准误 \(s / \sqrt{n}\),公式完全一样。
为什么除以√n而不是n?因为样本均值的方差等于 \(\sigma^2/n\);为了回到标准差(而非方差)的单位,需要再开平方根,于是得到 \(\sigma/\sqrt{n}\)。