개념 설명
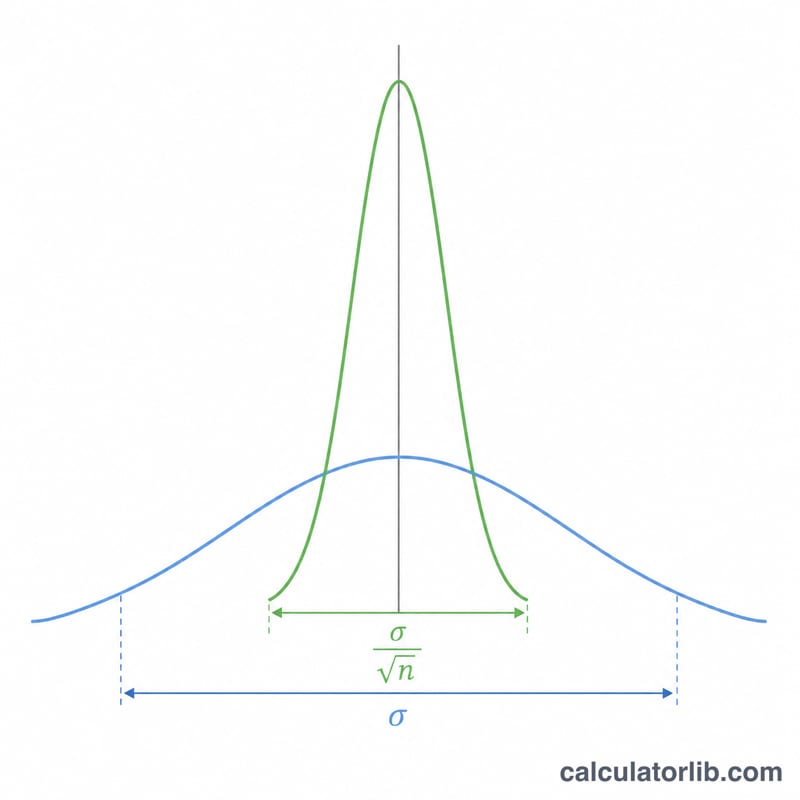
표본평균의 표준편차는 흔히 평균의 표준오차(SEM, Standard Error of the Mean)라고 부르며, 무작위로 뽑은 표본의 평균이 실제 모평균에서 얼마나 벗어날 수 있는지를 나타내는 값입니다. 모집단 표준편차 \(\sigma\)가 개별 데이터들이 얼마나 흩어져 있는지를 보여준다면, 표준오차는 표본평균들이 얼마나 흩어지는지를 보여줍니다. 관측값을 많이 모을수록 표본평균은 모평균 주위에 더 촘촘하게 모이게 됩니다.
계산기 사용법
모집단 표준편차(\(\sigma\))와 표본 크기(\(n\))를 입력하세요. 계산기는 \(\sigma\)를 \(n\)의 제곱근으로 나누어 표준오차를 돌려줍니다. 이 값은 신뢰구간을 만들거나, 가설검정을 수행하거나, 추정한 평균이 얼마나 믿을 만한지를 판단할 때 활용할 수 있습니다.
공식 풀이
둘 사이의 관계는 다음과 같습니다.
$$\sigma_{\bar{x}} = \frac{\sigma}{\sqrt{n}}$$
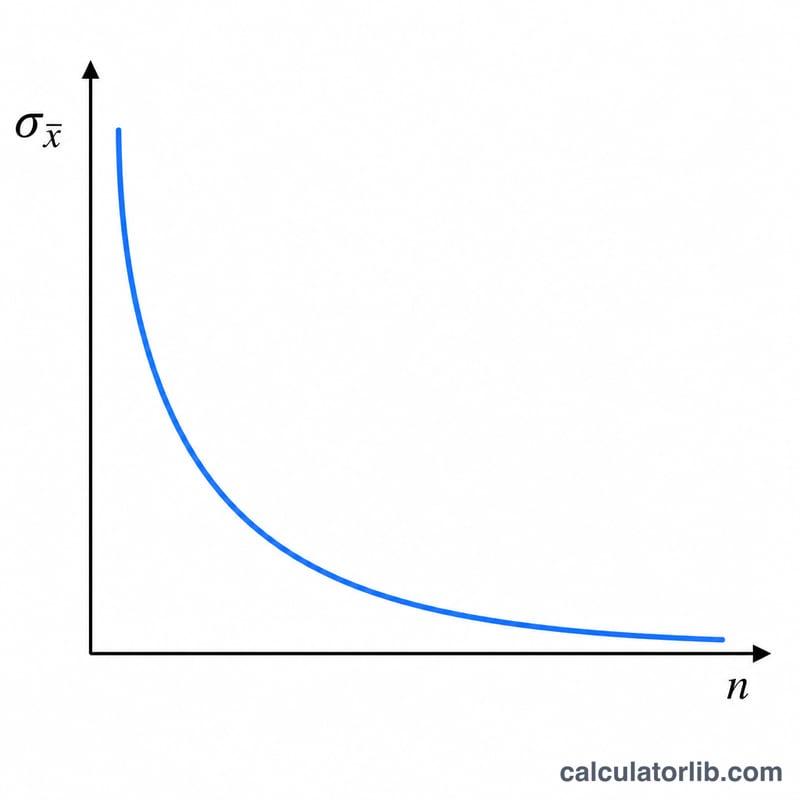
\(n\)이 제곱근 안에 들어가 있기 때문에 표준오차를 절반으로 줄이려면 표본 크기를 네 배로 늘려야 합니다. 이러한 "수익 체감" 성질은 연구 설계의 핵심입니다. 정밀도를 크게 높이려 할수록 비용이 점점 더 가파르게 증가하기 때문입니다.
예제 풀이
어떤 모집단의 표준편차가 \(\sigma = 10\)이고, \(n = 25\)개의 관측값을 표본으로 뽑았다고 가정해 봅시다. 그러면 $$\sigma_{\bar{x}} = \frac{10}{\sqrt{25}} = \frac{10}{5} = 2$$가 됩니다. 즉, 표본평균은 실제 모평균을 중심으로 대략 2 단위 정도 변동하게 됩니다.
자주 묻는 질문
\(\sigma\)와 표준오차는 무엇이 다른가요? \(\sigma\)는 개별 값들의 변동성을 나타내고, 표준오차는 표본평균의 변동성을 나타냅니다. 그리고 표준오차는 (\(n > 1\)일 때) 항상 \(\sigma\)보다 작습니다.
표본표준편차 \(s\)만 가지고 있다면 어떻게 하나요? \(\sigma\) 대신 \(s\)를 넣어 추정 표준오차 \(s / \sqrt{n}\)를 구하면 됩니다. 공식은 동일합니다.
왜 \(n\)이 아니라 \(\sqrt{n}\)으로 나누나요? 표본평균의 분산이 \(\sigma^2/n\)이기 때문입니다. 여기에 제곱근을 취해 표준편차 단위로 되돌리면 \(\sigma/\sqrt{n}\)이 됩니다.





