माध्य की मानक त्रुटि क्या है?
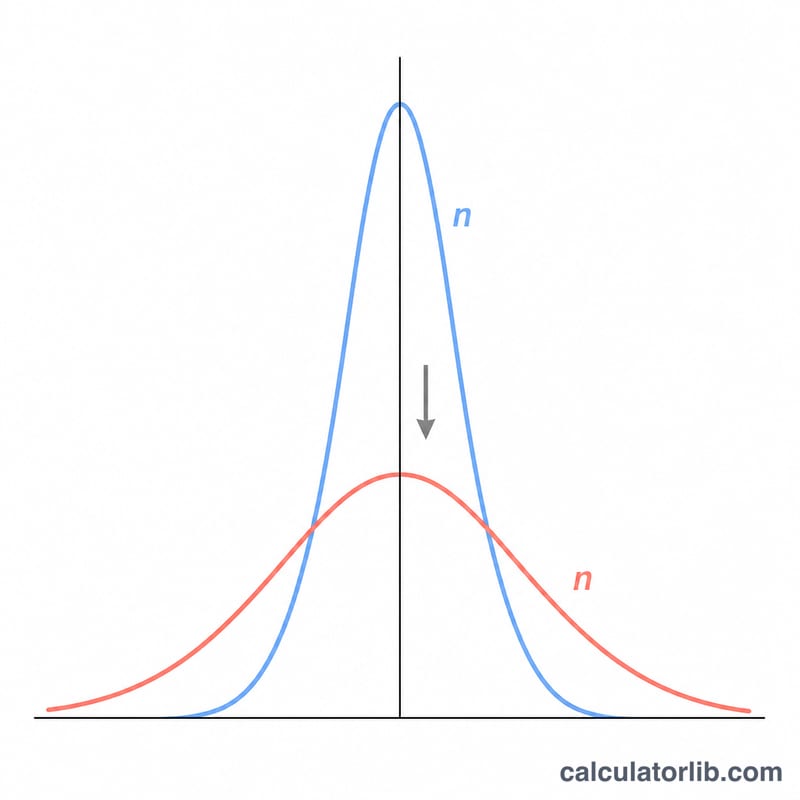
माध्य की मानक त्रुटि (Standard Error of the Mean, SEM) यह बताती है कि किसी सैंपल का माध्य वास्तविक जनसंख्या (population) माध्य से कितना भटक सकता है। जहाँ मानक विचलन (standard deviation) हर एक डेटा बिंदु के बिखराव को दर्शाता है, वहीं SEM यह बताता है कि आपके औसत का अनुमान कितना सटीक है। सैंपल जितना बड़ा होगा, मानक त्रुटि उतनी ही कम होगी — यानी आपका सैंपल माध्य जनसंख्या माध्य का उतना ही भरोसेमंद अनुमान बन जाता है।
इस कैलकुलेटर का उपयोग कैसे करें
अपने सैंपल का मानक विचलन (s) और सैंपल साइज़ (n) दर्ज करें, और नतीजा देखें। कैलकुलेटर मानक विचलन को सैंपल साइज़ के वर्गमूल से भाग देता है। अगर आपके पास केवल कच्चा डेटा (raw data) है, तो पहले उसका मानक विचलन निकालें, फिर उसे प्रेक्षणों की संख्या के साथ यहाँ डालें।
सूत्र की व्याख्या
सूत्र है $$\text{SEM} = \frac{\text{Std. Dev. (s)}}{\sqrt{\text{Sample Size (n)}}}$$। यहाँ \(s\) सैंपल का मानक विचलन है और \(n\) प्रेक्षणों की संख्या है। चूँकि n वर्गमूल के नीचे आता है, इसलिए सैंपल साइज़ को चार गुना करने पर भी मानक त्रुटि सिर्फ आधी होती है — किसी अध्ययन (study) की योजना बनाते समय यह एक बहुत काम का नियम है।
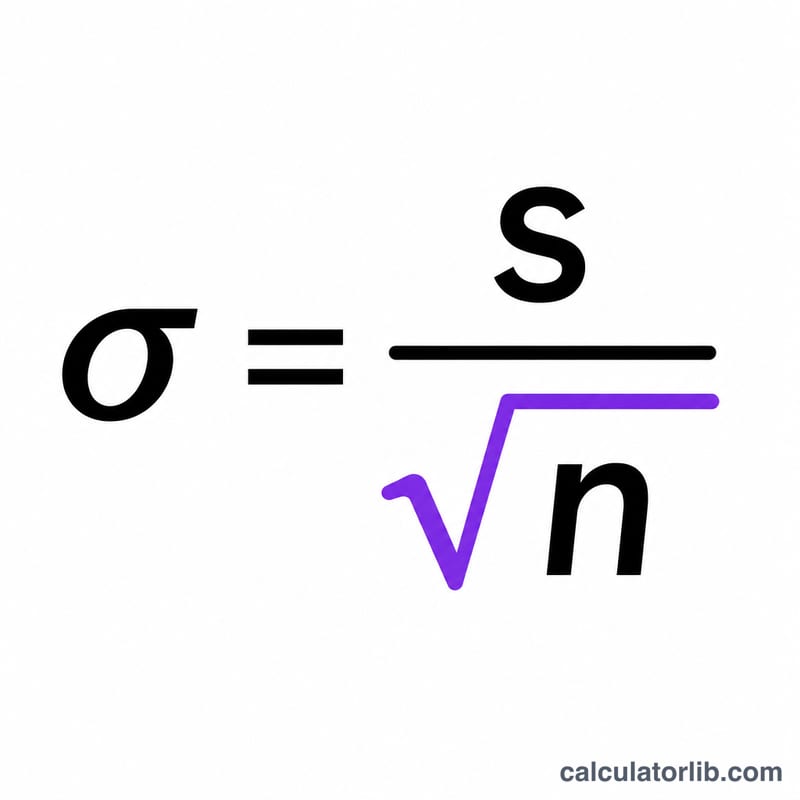
हल किया हुआ उदाहरण
मान लीजिए 25 मापों वाले एक सैंपल का मानक विचलन 15 है। तो $$\text{SEM} = \frac{15}{\sqrt{25}} = \frac{15}{5} = 3$$ होगा। यानी सैंपल माध्य का अनुमान 3 इकाई की मानक त्रुटि के साथ लगाया गया है। ऐसे में सामान्य 95% कॉन्फिडेंस इंटरवल लगभग माध्य \(\pm\, 1.96 \times 3\) होगा।
अक्सर पूछे जाने वाले सवाल
क्या SEM और मानक विचलन एक ही चीज़ हैं? नहीं। मानक विचलन डेटा बिंदुओं के बीच की विविधता मापता है; जबकि SEM यह मापता है कि सैंपल माध्य, जनसंख्या माध्य के अनुमान के तौर पर कितना बदल सकता है।
बड़े सैंपल में SEM कम क्यों हो जाता है? ज़्यादा प्रेक्षणों का औसत लेने से यादृच्छिक त्रुटि (random error) घट जाती है, इसलिए माध्य एक ज़्यादा स्थिर अनुमान बन जाता है।
अगर मुझे सिर्फ जनसंख्या का मानक विचलन पता हो तो? आप उसे s की जगह इस्तेमाल कर सकते हैं; सूत्र वही रहता है — \(s / \sqrt{n}\)।