माध्य की मानक त्रुटि क्या है?
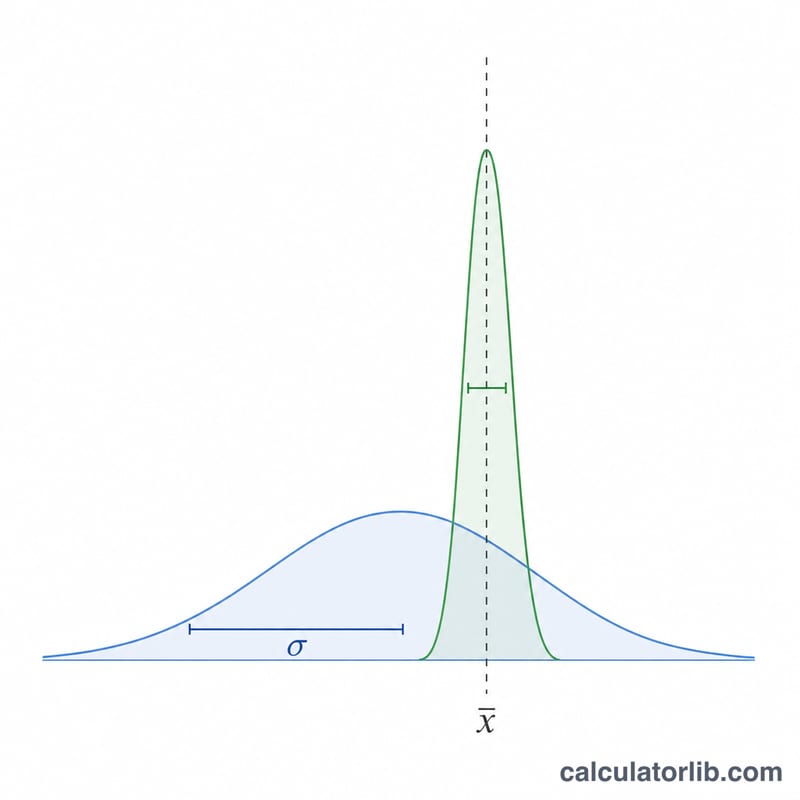
माध्य की मानक त्रुटि (SEM या SE) यह बताती है कि आपके नमूने का माध्य (sample mean) वास्तविक जनसंख्या के माध्य (population mean) से कितनी दूर हो सकता है। जहाँ मानक विचलन (standard deviation) यह दर्शाता है कि अलग-अलग आँकड़े एक-दूसरे से कितने फैले हुए हैं, वहीं मानक त्रुटि यह बताती है कि माध्य का आपका अनुमान कितना सटीक है। नमूना जितना बड़ा होगा, मानक त्रुटि उतनी ही कम होगी — यानी आपके माध्य का अनुमान उतना ही भरोसेमंद होगा।
इस कैलकुलेटर का उपयोग कैसे करें
बस दो मान भरें: अपने नमूने का मानक विचलन (s) और नमूना आकार (n)। कैलकुलेटर मानक विचलन को नमूना आकार के वर्गमूल से भाग देकर माध्य की मानक त्रुटि निकाल देता है। यह एक सार्वभौमिक सांख्यिकीय सूत्र है जो हर क्षेत्र में काम आता है — जीवविज्ञान, वित्त, मनोविज्ञान, इंजीनियरिंग और भी बहुत कुछ।
सूत्र की व्याख्या
सूत्र है $$\text{SE} = \frac{\text{Standard Deviation }(s)}{\sqrt{\text{Sample Size }(n)}}$$। यहाँ s नमूने का मानक विचलन है और n प्रेक्षणों (observations) की संख्या है। चूँकि \(n\) वर्गमूल के अंदर है, इसलिए मानक त्रुटि को आधा करने के लिए आपको नमूना आकार को चार गुना बढ़ाना पड़ता है — किसी अध्ययन की योजना बनाते समय यह बात बहुत काम की है।

हल किया हुआ उदाहरण
मान लीजिए किसी नमूने का मानक विचलन 15 है और उसमें 25 प्रेक्षण हैं। तब मानक त्रुटि होगी $$15 \div \sqrt{25} = 15 \div 5 = 3$$। यानी नमूने का माध्य वास्तविक जनसंख्या के माध्य के लगभग 3 इकाइयों के भीतर (एक मानक त्रुटि) अनुमानित है।
अक्सर पूछे जाने वाले सवाल
मानक विचलन और मानक त्रुटि में क्या अंतर है? मानक विचलन आँकड़ों के बीच की विविधता मापता है, जबकि मानक त्रुटि नमूने के माध्य के अनुमान की सटीकता मापती है।
क्या बड़ा नमूना मानक त्रुटि घटाता है? हाँ। जैसे-जैसे \(n\) बढ़ता है, \(\sqrt{n}\) बढ़ता है और मानक त्रुटि घटती जाती है, जिससे माध्य का अधिक सटीक अनुमान मिलता है।
क्या मैं जनसंख्या का मानक विचलन इस्तेमाल कर सकता हूँ? अगर आपको वास्तविक जनसंख्या का मानक विचलन (σ) पता है, तो आप \(\text{SE} = \sigma / \sqrt{n}\) का उपयोग कर सकते हैं। पर ज़्यादातर मामलों में आपके पास केवल नमूने का मानक विचलन \(s\) ही होता है।